Slovoeb
Содержание:
- Как работать с программой Словоёб?
- Как работать с программой словоеб?
- Способы составления семантического ядра
- Установка и настройка утилиты
- Как парсить ключевые запросы в СловоЁБ
- Какой функционал предоставляет Spywords
- Чем Словоеб отличается от Кей Коллектора
- Как работать в программе
- Приступаем к настройке Slovoeb’а
- Как правильно пользоваться Словоеб
- Парсинг поисковых фраз в Словоебе
- Установка Slovoeb в Linux
Как работать с программой Словоёб?
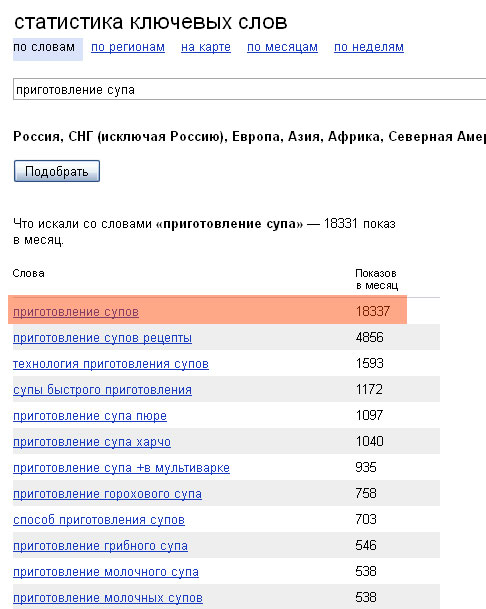
Сервис для составления семантического ядра Словоёб. Первое, для чего мы скачали данную программу — быстрее собрать семантическое ядро. Для этого в нем есть все те же функции, что и в Яндекс.Wordstat. Это сбор по левой колонке, по правой колонке Wordstat («что еще искали…»), сбор частотностей. Но сейчас вы сможете собрать весь необходимый пакет ключевых слов щелчком одной кнопки. Для этого, правда, вам все же нужно пройти первый этап сбора собственными усилиями. Т.е. составить список из нескольких самых значимых фраз, которые описывают страницу вашего сайта. Например, для моего текста подойдут запросы «словоеб» и «поиск ключевых слов».
Нажимаем красную кнопку «Пакетный сбор фраз по левой колонке Yandex.Wordstat» и вписываем туда эти слова. Нажимаем кнопку «Начать сбор» и Словоёб приступает к работе.
Внизу в окне программы есть вкладка «Журнал событий», где вы сможете следить за процессом: нет ли ошибок и прочее. Когда сбор закончен, вы можете его продолжить по правой колонке, если вам показалось, что найденных слов мало.
Кроме того, есть еще и функция сбора поисковых подсказок. Именно тех, которые Google и Яндекс предлагают при вводе слов в строку поиска. Зачастую предложенные ими варианты могут быть очень удачными. Я чаще собираю семантическое ядро именно так.
После того, как вы завершили сбор фраз, можете приступать к сбору частотностей, вида «!» (для точного вхождения ключа) или «» (для вхождения по всем его словоформам).
Отсеять лишние фразы вы можете перед сбором частотностей, либо после. В зависимости о того, как много у вас получилось запросов. Чтобы упростить отбор ключей, можно воспользоваться фильтром «Стоп-слова». Например, у меня лишними будут запросы, в которых есть слово «скачать». Я его вношу в фильтр и нажимаю «Отметить фразы в таблице». Как видите, эти фразы отмечены галочкой в таблице сбора. И я их просто удаляю.
Когда вы отсеяли всё лишнее и собрали всю необходимую информацию, выгружайте ваш файл в Excel (вверху слева есть зеленая иконка «Экспортировать данные») и работайте с ними в удобном формате. Вот так легко программа для составления семантического ядра справляется со своей задачей.
Как работать с программой словоеб?
После установки программы (ссылка на скачивание ниже), вы открываете програму и перед вами появится примерно вот такое окно:
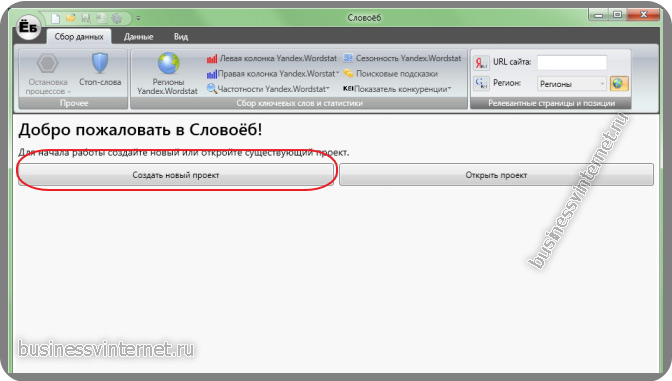
Вы кликаете «новый проект», называете его и указываете путь, куда сохранить на вашем компьютере.
Далее указываете свой главный запрос в строке «запрос» и нажимаете ентер:
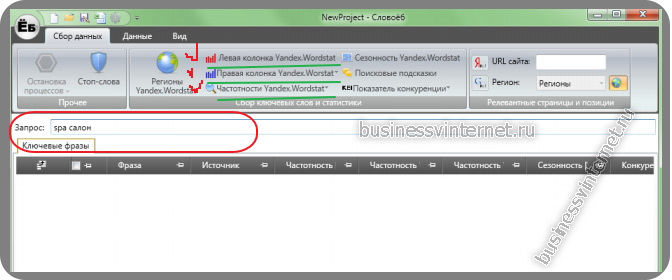
Спустя какое то время — перед вами готовый результат. Далее, чтобы оценить настоящую частотность поискового запроса (вида: «!ключевое слово»), кликаете собрать частотность вида «!слово»:
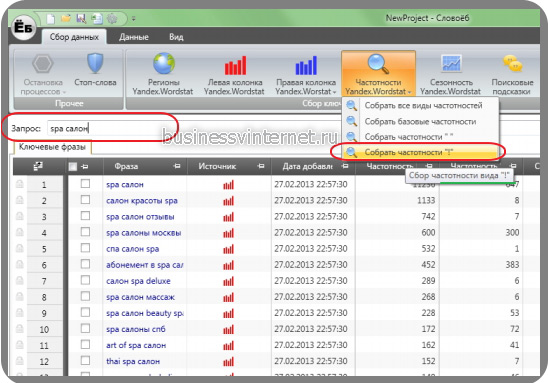
Перед вами полная картина потенциальных поисковых запросов, которые вы можете использовать.
Я в качестве главного запроса выбрал «spa салон». Это достаточно «широкий» запрос.
Но можно выбрать из множества результатов 10-20 ключевых слов, который и взять за основу (план) для написания статьи.
Если ничего не нашли подходящего в таком списке — выполните поиск по правой колонке яндекса (или поставьте другой главный запрос, отражающий тематику будущей статьи).
Результат поиска ключевых слов в программе словоеб.
https://www.youtube.com/subscribe_widget
После того, как отобрали 10-20 ключевых слов для статьи, рекомендую их проверить в статистике https://adwords.google.com.
Ведь в Яндексе они могут быть просто накручены seo оптимизаторами (люди, которые составляют семантическое ядро например).
Поэтому, вы вбиваете свои запросы (которые отобрали для написания статьи) в гугл для анализа. Если Гугл показывает нулевые показатели, то запрос «накрученный» и его надо заменить.
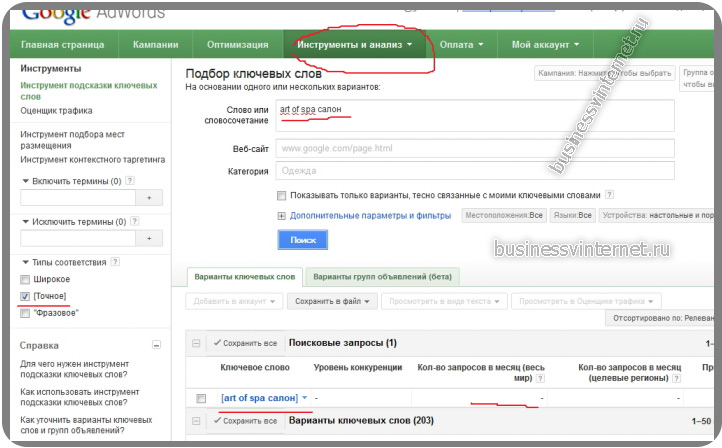
Также рекомендую использовать сервис семраш (_http://ru.semrush.com/) для оценки стоимости клика по контекстной рекламе.
Вот что у меня получилось в Словоеб (данные только из левой колонки Яндекса):
|
spa салон |
11236 |
647 |
|
салон красоты spa |
1133 |
8 |
|
spa салон отзывы |
742 |
7 |
|
spa салоны москвы |
600 |
300 |
|
спа салон spa |
532 |
1 |
|
абонемент в spa салон |
452 |
383 |
|
салон spa deluxe |
289 |
6 |
|
spa салон массаж |
268 |
6 |
|
spa салон beauty spa |
228 |
53 |
|
spa салоны спб |
172 |
72 |
|
art of spa салон |
162 |
41 |
|
thai spa салон |
152 |
7 |
|
spa салон desheli |
149 |
46 |
|
spa deluxe салон красоты |
147 |
42 |
|
салон day spa |
141 |
1 |
|
игра spa салон |
130 |
62 |
|
spa салон челябинск |
119 |
61 |
|
spa салон услуги |
115 |
6 |
|
салон spa deluxe тверская 18 |
115 |
59 |
|
spa cocteil спа салон |
101 |
11 |
|
spa салон цены |
100 |
5 |
|
art of spa салон отзывы |
94 |
66 |
|
1с spa салон |
90 |
14 |
|
spa салон екатеринбург |
89 |
39 |
|
массажный spa салон |
88 |
1 |
|
spa салон пермь |
85 |
29 |
|
мужской spa салон |
81 |
22 |
|
day spa салон красоты |
79 |
41 |
|
spa cocktail салон |
79 |
51 |
|
сертификат в spa салон |
75 |
9 |
|
spa салон для мужчин |
75 |
31 |
|
spa салон донецк |
73 |
26 |
|
салон красоты beauty spa |
72 |
10 |
|
spa салон grand |
71 |
14 |
|
spa салон подарочный сертификат |
65 |
8 |
|
spa салоны нижнего новгорода |
64 |
25 |
|
spa салоны новосибирск |
62 |
18 |
|
spa салон 7 красок |
57 |
13 |
|
spa салоны красноярск |
57 |
30 |
|
vita spa салон |
57 |
4 |
|
spa салон для двоих |
56 |
25 |
|
spa салоны алматы |
56 |
21 |
|
spa салон ростов |
56 |
6 |
|
spa салон краснодар |
55 |
2 |
|
салон spa relax |
54 |
6 |
|
spa салон самара |
53 |
19 |
|
spa салон харьков |
50 |
22 |
|
spa салон зеленоград |
48 |
6 |
|
spa салон киев |
47 |
26 |
|
spa салоны тюмень |
46 |
21 |
Способы составления семантического ядра
Key Collector
Для составления семантики мы можем воспользоваться программами для создания СЯ. Какие-то из них делают почти всю работу за вас – их еще называют автоматическими. В каких-то сервисах придется больше работать самостоятельно.
Например, есть такая платная утилита Key Collector. Хотя в ней этот процесс почти полностью автоматизирован, необходимо знать, как настроить Key Collector. На выходе вам лишь остается немного прибраться в запросах, убрав оттуда наиболее бесполезные, что включает в себя запросы от роботов, спам и т. д. Стоимость такой программы составляет почти 2 000 рублей.
Яндекс Вордстат
Заниматься сбором семантики можно и с помощью сервиса от Яндекса – Вордстат. Им очень легко пользоваться, достаточно просто ввести ключевое слово, он выведет вам запросы, в которых присутствует данный ключ. Вместе с этим Wordstat покажет вам и похожие запросы, которые также могут быть интересны при продвижении.
В этой статье с помощью Вордстата мы будем собирать первичные ключи, которые понадобятся нам для дальнейшего сбора семантического ядра. Но об этом позже, а пока я приведу вам еще несколько способов, с помощью которых можно собрать семантику.
Яндекс Вордстат + СловоЁБ
Программа с таким красочным названием является абсолютно бесплатным аналогом Key Collector. Естественно и функционала в нем чуть меньше, чем в коммерческом конкуренте, но для сбора семантического ядра под поисковое продвижение этого вполне хватит.
Если вам интересно, чем СловоЁБ отличается от Кей Коллектора, просто взгляните на эту табличку.
Безусловно, отличий здесь вагон и маленькая тележка. Однако для простого сбора ядра возможностей СловоЁБа вполне хватит.
Онлайн-сервисы
Итак, помимо вышеописанных вариантов, семантику можно сделать с помощью онлайн-сервисов. Если вы забьете запрос “Сбор семантики онлайн”, то поисковик выдаст вам большое количество всевозможных онлайн-инструментов. Они могут быть как хорошими, так и плохими. И, соответственно, как платными, так и бесплатными.
С помощью различных онлайн-сервисов можно еще узнать семантическое ядро конкурентов. Будьте уверены, что практически все компании занимаются проверкой данных своих потенциальных соперников.
Заказ у специалиста
Вы можете просто купить готовое решение у специалиста. Он все сделает, и на выходе вы получите целостный файлик со всеми запросами. Далее из него уже можно будет создать список статей с техническими заданиями к ним. Ну и отдать это все на растерзание копирайтерам. Но это уже вопрос делегирования обязанностей, его сегодня затрагивать мы не будем.
Установка и настройка утилиты
Скачанный архив нужно обязательно распаковать, запустить файл exe. А еще лучше перетащить значок Ёb на панель задач: для дальнейшего использования. Остальные папки и файлы архива, кроме тескстового ( рекомендую его прочесть), удалять нельзя.
Теперь, запустив утилиту, можно приступать к работе. В открывшемся окне, непосвященному пользователю, прежде всего советую ознакомиться с настройками программы (значок шестеренки в верхней панели); даже простое начальное ознакомление с этой функцией, позволит больше понять принцип работы утилиты.
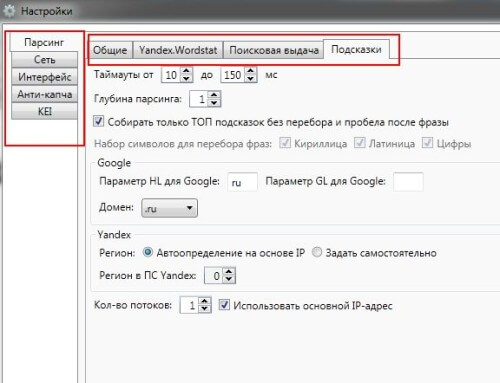
Для начала достаточно ознакомиться с каждой функцией настроек и ничего не менять в них. Не все поймете, но позже поможет практика.
Приступая к дальнейшей работе, после изучения настроек, вначале прошу обратить на блоки в верхнем левом углу: при наведении курсора на каждую из иконок, открывается текст, позволяющий понять, какую функцию будет выполнять программа, если кликнуть по иконке или строке:
Все, что нужно сделать — прочесть и понять. «Сбор данных» — это главная функция, на которую нужно кликнуть, прежде чем выбрать приступить к операции их сбора по нужной фразе или ключевому слову. «Данные» — в этом блоке предоставляется чистка или редактирование уже введенных данных, даже по ходу проводимых операций:
Все настолько просто, что разобраться в этих блоках можно за одну-две минуты.
Если вы открыли строку «Сбор данных», то дальше можно приступать к работе с основным блоком. Начинающим рекомендую опробовать каждую функцию из основного блока панели программы. Так будет легче понять смысл и назначение из них. Прежде, чем приступить к парсингу, нужно создать проект!
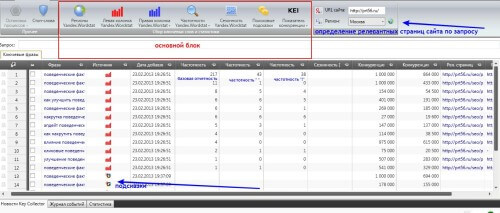
При активации каждого из них поочередно: «Регионы Yаndex. Wordstat», «Левая колонка Yandex. Wordstat» и т.д, программа выдаст необходимую для вас информацию.
Но прежде вам нужно будет подождать, пока она их соберет (пропарсит). Наблюдать ход процесса нужно в нижней части программы, где будет передвигаться специальный ползунок слева направо (статистика). Ожидание должно происходить до тех пор, пока процесс не завершится. Можно посмотреть, так же, «Журнал событий».

Среди центральных основных функций, я хочу выделить функцию «Подсказки»: при выполнении задания по ней, программа, по аналогии с ПС, выдает дополнительные поисковые запросы, среди которых можно найти те низкочастотные фразы, которые будут очень кстати при продвижении по низкочастотным запросам (НЧ).
Верхний правый блок замечателен тем, что с его помощью определяется релевантность страниц выбранного вами сайта по всем ключевым словам, которые предоставила программа в результате парсинга («Фразы»). Подбор релевантных страниц производится в Яндексе и Гугле ( по отдельности в каждом столбце окна программы). Ни в Яндекс Вордстат, ни в Гугл Адвордс (то, о чем я говорил выше) такой функции, разумеется, нет. 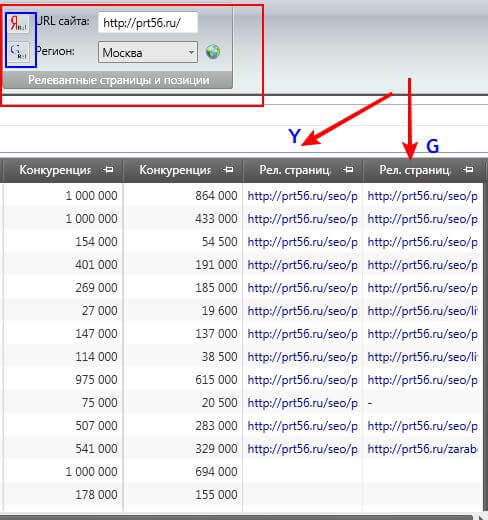
Как парсить ключевые запросы в СловоЁБ
После того, как мы подобрали основные ключевые запросы, которые будем парсить (их можно сохранить для дальнейшей обработки в программе Excel, или подобной), переходим к работе с программой парсером.
После первого запуска необходимо провести минимальные настройки для дальнейшей работы с программой. Первое, это ввести логин и пароль от имеющегося аккаунта Яндекс в формате «мойлогин:мойпароль». Я рекомендую для работы с Словоёбом использовать отдельно созданную учетную запись, чтоб не потярять наработки. если вдруг аккаунт будет по каким то причинам заблокирован. Для ввода логина и пароля жмем значок шестеренки в верхней пали программы и в открывшемся окне выбираем вкладку «Yandex.Direct»:
Далее переходим на вкладку «Yandex.Wordstat», и выставляем значение «глубина парсинга» равное двум.
После чего сохраняем настройки. Все программа готова к работе. Теперь создаем новый проект, нажав кнопку «Создать новый проект» и сохраняем его в удобном для нас месте.
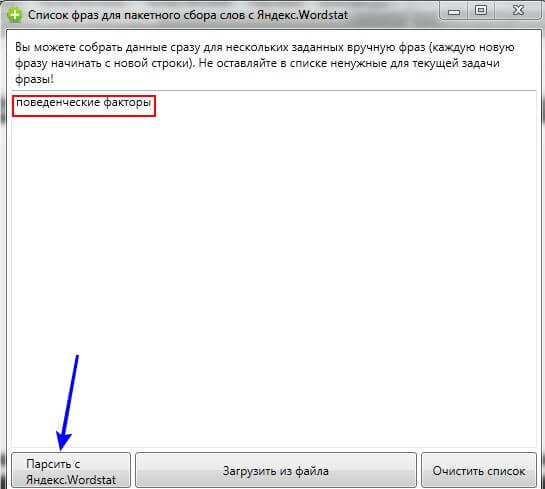
В открывшемся окне проекта переименовываем название Группы по умолчанию в ключевое слово, которое собираемся парсить и жмем кнопку «Пакетный сбор слов из левой колонки….», для начала процедуры парсинга.
В следующем окне вводим ключевое слово, которое мы хотим найти в разных сочетаниях и жмем кнопку «Начать сбор».
Если появится окно с капчей, то вводим соответствующие символы и запускаем поиск.
Вот и все. Сбор слов начался. Вы можете ждать, пока программа соберет все вариации и остановится сама, или остановить поиск вручную, если данные в колонке «Частотность» напротив найденных слов будут составлять менее цифры 7.
Затем можно скопировать найденные слова кликнув правой кнопкой мышки по колонке «Фраза» и выбрав в выпадающем меню пункт «Скопировать колонку в буфер обмена».
Далее найденные слова можно вставить в Excel файл и продолжить там работу по сортировке этих слов, очистки от не нужных приложений и не подходящих ключевых фраз.
Какой функционал предоставляет Spywords
Стоит ли спорить о том, насколько полезным может быть данный сервис для любого блогера или вебмастера?
Ведь его довольно богатый функционал позволяет производить множество манипуляций, направленных на seo-продвижение сайта в поисковых системах и охват большей аудитории.
Список заявленных служб выглядит следующим образом:
- Анализ конкурентов;
- Битва доменов;
- Война доменов;
- Рейтинги доменов;
- Умный подбор запросов.
Пройдемся более детально по каждой из них.
Анализ конкурентов
Это очень мощный инструмент, который позволяет узнать на каких позициях и по каким ключевым словам сайт находится в выдаче Яндекса и Google (для примера возьмем сайт самой компании Spywords).
Для чего нам эта информация нужна?
Все очень просто: именно под эти запросы можно написать свои статьи и перехватить немного трафика и себе. А может даже и не немного
Здесь стоит отметить, что в работу лучше брать не все запросы, а только с хорошей частотностью и невысокой конкуренцией. Как проверить эти показатели и какой сервис для этого нужно использовать я расскажу в следующей статье.
Статья уже готова и ждет вас вот здесь.
Так что, кто еще не подписался — подписывайтесь, а то есть вероятность пропустить реально полезную информацию.
Помимо этого, анализ транслирует изменения в позициях за определенное время и показывает основных конкурентов. Также анализ позволяет видеть текст объявлений в кампаниях контекстной рекламы и стоимость клика по каждой из поисковых фраз.
Я пока особо в подробности данной информации не вдавалась, поскольку мы не монетизируем блог. Но на будущее, конечно, эта информация будет необходима. Поэтому нужно знать, где её можно получить. Вот мы с вами теперь знаем где — сервис SpyWords.
Итак, какую информацию мы можем получить, проведя анализ своих конкурентов:
- запросы в поиске;
- позиции в поиске;
- сниппеты и урлы страниц;
- динамика позиций;
- запросы и позиции в контексте;
- оценка трафика.
Также анализировать конкурентов можно и в этом сервисе. Подробнее про него можно прочитать здесь.
Битва доменов
Это уникальный инструмент, который позволяет производить сравнение одновременно двух или трех доменов. Сравнение проводиться по таким основным параметрам, как запросы и трафик из контекста, запросы в топ 10 и 50 и, соответственно, трафик из поиска.
Благодаря этой услуге, можно посмотреть по каким пунктам ваш сайт не дотягивает до основных конкурентов, и направить все силы на восполнение и исправление этого недочета.
Сравним сайты Spywords и его конкурента xtool:
Также сервис предоставляет сравнительные диаграммы, на которых можно визуально наблюдать источники наибольшего количества трафика для каждого из доменов.
Война доменов
В отличие от Pro тарифа, функция «Война доменов» доступна только в тарифном плане Unlim. Он практически дублирует возможности «Битвы доменов», но главной его особенностью является то, что для сравнения можно добавлять до 20 разных доменов.
Такое дополнение превращает этот инструмент в настоящий исследовательский центр. Если в вашей нише много конкурентов, анализ каждого из них в отдельности может отнять достаточно времени.
Благодаря функции «Война доменов» можно не только ускорить этот процесс, но и значительно его автоматизировать, так как одна сводка дает детальную информацию по каждому из конкурирующих сайтов.
Рейтинг доменов
Это самый новый инструмент на сайте, который позволяет отслеживать позиции сайтов в поисковой выдаче, однако он доступен лишь в продвинутом тарифном плане.
Там можно просматривать текущую ситуацию в топе выдачи систем Яндекс и Google, следить за взлетами и падениями в выбранный период времени. Это значительно облегчает работу, потому что больше нет необходимости ежедневно отслеживать изменения в выдаче, перебирая вручную тысячи разнообразных запросов.
Умный подбор запросов
Еще один незаменимый помощник в работе вебмастера или блогера, который позволяет в считанные секунды составить полное семантическое ядро.
Вводим в строку необходимый запрос и нажимаем на кнопку «Найти все лучшие слова!»
И выбираем те запросы, которые считаем нужными.
Отличительной чертой этой функции на Spywords является ее большая практичность, так как ядро составляется из тех фраз, которые рекламодатели используют в своих контекстных кампаниях. В то время как большинство похожих сервисов по подбору ключевых фраз не делают детальную выборку по всем доступным фразам, перемешивая качественные слова с откровенно мусорными, Spywords отсеивает нерелевантные и некачественные варианты.
Для любого блогера такой инструмент станет отличной находкой и помощником в генерации новых идей и составлении семантические ядра.
Чем Словоеб отличается от Кей Коллектора
Обе программы были созданы для автоматического парсинга запросов с Яндекс.Вордстата, Директа и прочих сервисов, которые бы могли дать статистику и частотность поисковых фраз. В дальнейшем эта информация используется для составления семантического ядра. А уже сама семантика нужна для грамотного и быстрого продвижения ресурсов в поисковых системах.
Собирать ядро можно и вручную, но в этом случае придется потратить кучу времени и нервов. А для каких-то отдельных ниш это вообще на грани невозможного, поэтому лучше даже не пытаться.
В чем же отличие Словоеба и Кей Коллектора? Ведь обе этих программы от одного разработчика и созданы для одних целей. Можно рассматривать их как ограниченную и расширенную версию.
Бесплатный Словоеб очень ограничен в функционале. Но его вполне хватит для местного непрофессионального использования.
В свою очередь Кей Коллектор может быть использован как новичками, так и профессиональными специалистами. Вот отличия Словоеба версии 2.0 и Кей Коллектора.
Как видите, Словоеб 2.0 работает только с Вордстатом и поисковыми подсказками. В то время как КК работает почти со всеми известными поисковыми системами. Иными словами, Словоеб можно использовать только для составления семантики относительно Яндекса. Для других поисковых систем придется покупать платный вариант.
Также тут есть и функциональные отличия. Их достаточно много, но все-таки при помощи Словоеба можно собрать семантическое ядро. А это все, что нас интересует.
Как работать в программе
Теперь мы кратко разберемся, как пользоваться этой программой. Сложностей тут никаких нет. Но все равно стоит дать небольшую инструкцию, которая будет включать в себя последовательность действий и обзор некоторых функций.
Для начала вы должны создать проект. Идем в главное меню (кнопочка Еб в углу), нажимаем на “Создать проект”. Выскочит окно нашего файлового менеджера, где нам будет предложено заполнить поле “Имя” и сохранить наш файл проекта в каком-то месте.
Это все делается на ваше усмотрение. Но лучше сохранять проекты в той же папке, где и сам Словоеб. После того, как вы кликнете “Сохранить”, проект откроется в окне программы.
В нижней части программы мы видим настройки регионов для Яндекса и Гугла. Самая первая отвечает за Яндекс.Вордстат, вторая – за Директ, третья – Гугл. Также тут есть кнопка обновления, которая поможет вам в случае, если программа начнет тупить.
Чуть выше вы можете видеть вкладки: “Новости” – которых уже не было 2 года, “Журнал событий” – лог всех операций, производимых через утилиту, и “Статистика” – тут будет отображаться статистика по собранным ключевикам.
Еще выше у нас расположилось большое поле, где будут все запросы и их частотности. Вся информация представлена в виде удобной таблицы.
Рядом “Управление группами”. С помощью этого инструмента вы сможете разбивать запросы на группы и работать уже с ними.
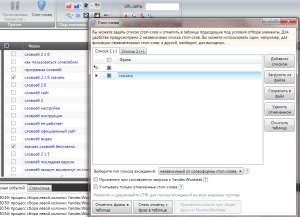
В самом верху у нас находятся инструменты для работы с семантическим ядром. Самая первая из доступных нам кнопок позволяет работать с минус-словами. Туда можно вписать слова и фразы, которые программа должна игнорировать при сборе ядра.
Рядом идут инструменты для работы с Вордстатом и поисковыми подсказками. Вы можете собрать ключи из левой колонки Вордстата (с наличием самого ключа в запросах), правой колонки (похожие запросы). После этого можно собрать поисковые подсказки или проверить корректность словоформ. Здесь же инструменты для вычисления KEI и сбора частотностей.
Для добавления своих поисковых фраз вы должны перейти во вкладку “Данные”, нажать на кнопку “Добавить фразы”. У вас выскочит окно, куда вы сможете ввести одну или несколько поисковых фраз.
Поисковые фразы можно добавлять в текущую группу, либо же создать новую. Также вы можете воспользоваться функцией “Загрузить из файла”. Программа работает только с TXT-файлами, поэтому если вы сохраняли поисковые фразы где-то еще – самое время перенести их в блокнот. После этого вы сможете собрать частотности или провести любые другие операции с этими данными.
Как только работа по сбору семантического ядра и очистке его от лишнего мусора будет закончена, вы должны экспортировать всю информацию в файл. Для этого найдите в левом верхнем углу иконку с Excel-файлом и кликните на нее. Далее вновь откроется окно файлового менеджера, используя которое вы и сохраните файлик с таблицей.
Вы можете сохранить проект и вернуться к работе над ним позже. Для этого нажмите на иконку сохранения, также выберите папку через файловый менеджер и кликните на “Сохранить”.
Приступаем к настройке Slovoeb’а
Скачивание его можно произвести с официального сайта (http://seom.info/new/SlovoEB).
Установка не требуется — распаковывается в любое место архив и запускается исполняющим файлом Slovoeb.exe.
Перед настройкой нужно запомнить каталог, где будут эти настройки храниться и ознакомиться с правилами подбора ключевых слов — так как, само собой, это очень важно для подобной программы. Итак, после запуска видим окно:. Итак, после запуска видим окно:
Итак, после запуска видим окно:
Перед началом работы создайте несколько аккаунтов на Яндексе
Также перед настройкой рекомендовано создание хотя бы пяти-шести аккаунтов на Яндексе, так как будет нужна обязательная авторизация (Спецсимволы в паролях не допускайте).
Во время работы программы осуществляется мощное количество запросов к поисковой системе от ваших аккаунтов. В ответ на это можно нарваться на уведомление о том, что аккаунт вычеркнут из списка. Поэтому не используйте реальные свои адреса (явки):
Чтобы избежать блокировки рабочих аккаунтов, используйте специально созданные несколько клонов
ВАЖНО. Все ошибки программы удобно отслеживать в журнале событий. При появлении ошибки в Словоёбе «нет поля запроса» — просмотрите внимательно журнал.
При появлении ошибки в Словоёбе «нет поля запроса» — просмотрите внимательно журнал.
Входим в настройки.
Вкладка Yandex.Direct
На вкладке Yandex.Direct осуществляется ввод значений логина и пароля через двоеточие (ознакомившись с предупреждением на вкладке).
ВАЖНО. Каждый последующий логин/пароль пишется с новой строки!
Парсинг.Общие
Значения, указанные на картинке, меняются с выходом обновлений (имеются в виду значения по умолчанию). Кроме того, эти параметры нужно сообразовывать «под себя». Но при отсутствии опыта оптимальными будут предложенные самой программой.
Пояснение параметров видно из другого рисунка:
Пояснения к параметрам программы
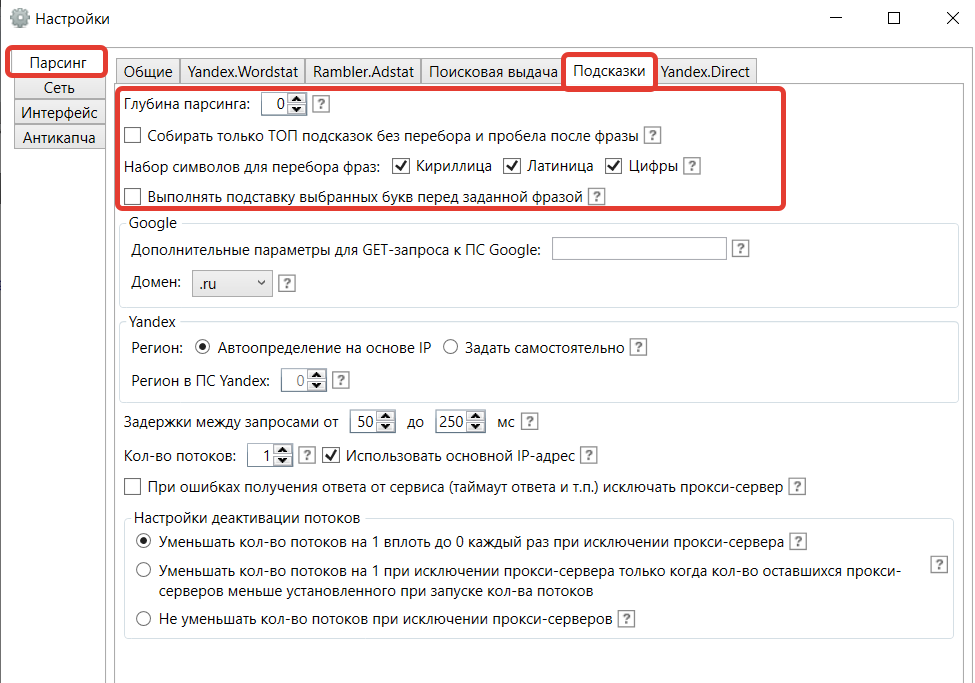
Яндекс.Вордстат
В этой вкладке:
- Значение глубины выставляется ноль. Значение «единица» приведёт к возникновению перегрузки системы и долгому ожиданию. При установлении значения 2 — после основного парсинга программа приступит к глубинному анализу по каждому из ключевых слов. Это приведёт к блокировке IP-адреса;
- Максимальное количество парсируемых страниц;
- Прорабатываются страницы от тысячи показов в месяц до ста (на убывание);
- Вводится логин/пароль через двоеточие;
- Сохранить изменения.
Подсказка для вкладки «поисковая выдача» представлена на картинке:
Пример заполненных значений
Настройка Антикапчи
Важный момент — распознавание капчи. Для того чтобы от неё избавиться нужно воспользоваться дополнительным сервисом. Утилита поддерживает такие:
- Antigate;
- SocialLink;
- CaptchaBot;
- ruCaptcha;
- RIPCaptcha.
Первый представляется более классическим, платным (однако недорогим). CaptchaBot — более современен.
Отыскать их можно по ссылкам: antigate.com и anti-captcha.com.
Вход в отладку антикапчи совершается щелчком по вкладке левой части окна настроек.
Ключ антикапчи, полученный в её настройках, нужно ввести в поле «Antigate Key»:
Введите полученный код
Другие вкладки:
«Сеть» и «Подсказки» оставляем нетронутыми, интерфейс настраивается исходя из собственных предпочтений.
Как правильно пользоваться Словоеб
Если вы не против, то я буду показывать процесс работы опять-таки с помощью скриншотов из КейКоллектора. Конечно же вы не против. И давайте тогда рассмотрим например, как собрать ключевые слова для настройки Яндекс-Директа.
Парсинг базового ключа
Первым делом нам надо распарсить наш базовый ключ. Допустим, мы настраиваем рекламу для доставки пиццы на дом. Нашим базовым ключом в этом случае будет “доставка пицца” или просто “пицца”. Но ввести просто “пицца” – значит обречь себя на долгую ручную чистку списка ключей от всяких “рецептов пиццы в домашних условиях”.
Поэтому давайте возьмем “доставка пицца”. Создайте новый проект, и перед началом работы обязательно укажите регион, в котором вы собираетесь рекламироваться.
Если это вся Россия, то ничего не меняйте.
Теперь мы нажимаем на кнопочку парсинга Вордстат и вводим наш базовый ключ.
Программа начинает работать, а мы можем пока перекурить и оправиться.
Через некоторое время все процессы остановятся – значит парсинг завершен. И мы увидим список ключевых слов, которые нам подобрал Словоеб.
Но при этом он нам показывает только “базовую частотность”. То есть мы видим не точное количество запросов в месяц того или иного ключа, а общее количество запросов основного ключа + хвост.
Например, в списке, выданном Словоебом есть основной ключ “Телефон доставки пиццы”. И значение – 6560 запросов в месяц. Это значит 1000 запросов “телефон доставки пиццы” + еще 1000 запросов “телефон пицца доставка” + еще и еще.
А нам нужны точные значения, иначе мы никогда не сможем прогнозировать – какое количество трафика в месяц мы получим, и сколько мы с этого сможем заработать.
Поэтому переходим ко второй части парсинга – к Директу.
Узнаем точное количество запросов
Для того, чтобы узнать точное количество запросов к каждому ключу, мы нажимаем на синий значок Яндекс-Директа.
Обратите внимание на галочку “Целью запуска является сбор частотностей для колонок Вордстата”. То есть в основном эта функция как раз и используется для того, чтобы узнать точные показатели запросов. Конечно, он вам может показать еще стоимость клика по тому или иному запросу в Директе, но я никогда этим не пользуюсь
Слишком большая нагрузка на программу, и слишком неточные получаются результаты
Конечно, он вам может показать еще стоимость клика по тому или иному запросу в Директе, но я никогда этим не пользуюсь. Слишком большая нагрузка на программу, и слишком неточные получаются результаты.
Если вам нужны данные по точной словоформе, то можно еще поставить галочку в поле “!”. После этого нажимаем “Получить данные” и опять отправляемся пить кофе.
Вот что теперь мы имеем:
Как вы видите, наш такой перспективный ключ “телефон доставки пиццы” запрашивают на самом деле не шесть тысяч раз в месяц, а всего 22 раза в месяц. А мы-то уже губы раскатали.
Теперь, когда у нас есть объективные результаты, мы можем переходить к следующим этапам настройки. Это будет фильтр слов. То есть нам надо удалять те ключевые запросы, которые нам явно не подходят. Делать это можно прямо в интерфейсе Словоеба, или можете сначла выгрузить результаты в эксель и работать там. Давайте рассмотрим второй вариант.
Экспорт результатов
Для того, чтобы выгрузить полученные данные, нажмите на значок “эксель” в левом верхнем углу интерфейса, и укажите, куда надо сохранить файл.
Когда вы откроете файл, то увидите примерно вот такую картину:
Теперь вы можете спокойно удалять ненужные ключевые запросы, оставляя только те, по которым к вам точно придут клиенты. После этого вам еще надо будет создать рекламные объявления для каждого запроса. Об этом мы уже говорим подробнее в статье “Как самому настроить контекстную рекламу”.
Парсинг поисковых фраз в Словоебе
Познакомившись с интерфейсом этой замечательной программы и проставив все нужные настройки, пора переходить к процессу парсинга поисковых запросов из сервиса статистики Яндекса. Далее я расписал пошаговый план сбора будущих ключевых слов в Словоебе. Для примера использовал данные Вордстата по запросу «инфобизнес».
Создаем новый проект (или открываем готовый). В самом начале парсинга нужно сделать свой проект, в котором будут находиться нужные нам поисковые фразы по заданным словам. Обычно каждый проект у меня называется по одной теме.
Указываем стоп-слова. Если мы знаем, какие слова мы не хотели бы видеть в спарсенных поисковых запросах, то их необходимо прописать. Например, для коммерческого сайта этими словами будут «бесплатно», «халява», «скачать» и т.д. Таким образом мы облегчаем процесс сбора будущих ключевиков.
Выбираем регион продвижения. Для того, чтобы получить реальные параметры спарсенных поисковых запросов, необходимо задать нужный регион (аналогичный в сервисе Вордстат). Например, если Ваш блог продвигается по всей России, то в программе необходимо назначить такую же географическую область. Обычно я использую регион «Москва» или «Россия». В данном примере взят второй вариант. Выбрав регион, нажимаем левую кнопку парсинга Вордстата (кнопка №5) и получаем таблицу данных с поисковыми запросами и базовыми частотностями:
Фильтруем полученные запросы. Когда процесс сбора всех поисковых запросов закончился, мы должны пробежаться по ним и удалить те фразы, которые не подходят для нашей тематики. Поверьте, в каждой теме таких слов бывает достаточно. Но их обязательно нужно удалить, потому что они никак не дадут нам ключевые слова для продвижения нашего блога. Чтобы удалить их, сначала надо их выделить в таблице (с помощью чек-боксов):
Затем подводим мышку к нашей таблице с поисковыми фразами, нажимаем ее правую кнопку и в выпадающем меню выбираем соответствующую команду удаления:
Таким образом на выходе мы получаем уже тематические слова по нашим заданным фразам со своими базовыми частотностями. Теперь можно получить и другие параметры поисковых фраз, благодаря которым мы сможем выбрать самые качественные будущие ключевые слова.
Собираем точные частотности. На этом этапе парсинга нашей задачей является получение уточняющих параметров запросов от пользователей поисковых систем — они будут нужны при отборе качественных ключевых слов. Для этого нажимаем кнопку по сбору частотностей (на картинке интерфейса — элемент под номером 7) и выбираем из появившегося меню строку «Собрать частотности !» (картинка справа).
Удаляем слова-пустышки. После того, как в таблице данных наши спарсенные поисковые фразы получат свое значение точной частотности, необходимо удалить из нее так называемые слова-пустышки (точная частотность которых крайне мала и обычно имеет значение от 0 до 2). Удалить можно таким же способом, который показан выше по тексту.
В итоге мы получаем таблицу с данными частотностей для каждого полученного из поиска запроса. Теперь можно сделать ряд дополнительных действий (узнать конкуренцию по версии Словоеба, определить самую релевантную страницу по каждому ключевику) или экспортировать полученные поисковые фразы для дальнейшей обработки.
Таким образом, мы прошли весь процесс парсинга левой колонки Вордстата. Если нам необходимо для расширения тематики узнать дополнительные слова, можно воспользоваться парсингом правой колонки (процесс сбора запросов там такой же, какой мы сейчас рассмотрели).
Установка Slovoeb в Linux
Для запуска Словоеб Ubuntu, нам нужна 32-битная система Windows, так что если в вас 64 бит нужно экспортировать специальную переменную, чтобы создать префикс 32 бит. Заодно и создадим новый префикс:
$ export WINEARCH=win32
Теперь переходим к установке всех необходимых компонентов. Их довольно таки много.
Установим шрифты:
Установим компоненты среды выполнения Microsoft Visual Runtime:
Установим Flash плеер и ie8, браузер обязательно нужен чтобы выполнить запуск словоеб linux:
Начнем установку Microsoft Net Framework, нам нужна версия 4.0, но для ее установки необходимо будет установить и все предыдущие. Сначала выполните:
После завершения установки утилита откроет браузер и папку, скачайте установочный файл и скопируйте в открытую папку, затем еще раз выполните:
Теперь устанавливаем четвертую версию:
Дальше нам нужно установить пакет windowscodecs:
Но библиотека в 64-битной системе установится не полностью. Поэтому скачиваем библиотеку здесь и скидываем ее в папку ~/Slovoeb/drive_c/windows/system32/:
Теперь остался последний штрих. Скачиваем библиотеку msctf.dll для Windows XP и тоже скопируйте ее в ~/Slovoeb/drive_c/windows/system32/:
Дальше запускаем winecfg, переходим на вкладку библиотеки и нажимаем кнопку Добавить. Далее пишем *msctf и выбираем сторонняя (Windows).
Нажимаем Ok и выполняем команду, чтобы зарегистрировать библиотеку в системе:
Наконец загружаем самую последнюю версию Словоеб с официального сайта. Распаковываем в папку с загрузками:
И осталось запустить:
Все работает. Можете протестировать проверку позиций или сбор подсказок. Slovoeb Ubuntu отлично работает, точно так же как в в Windows. Если остались вопросы, пишите комментарии.
Обновление. Slovoeb прекрасно устанавливается и работает в 2019 по этой инструкции с wine 3.0. А вот KeyCollector запускается, но пока проект открыть невозможно. Видимо поддержка Microsoft NET 4.0 содержит еще много недоработок.