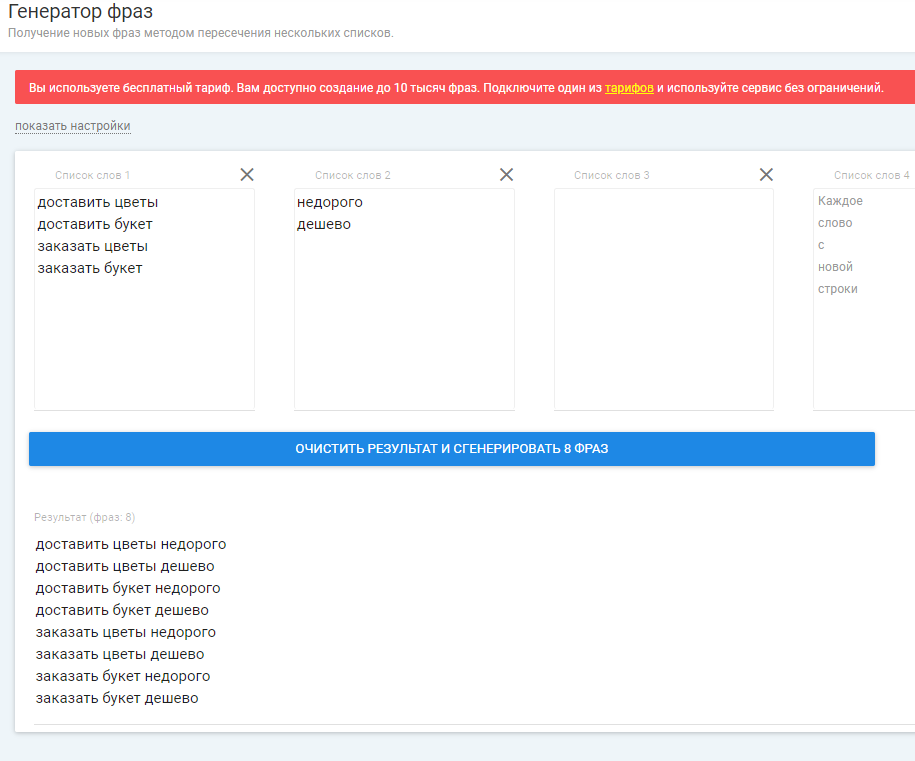
Что такое семантическое ядро и как оно влияет на seo?
Содержание:
- Serpstat
- Подбор эффективных запросов в Google AdWords
- Какие есть парсеры для Вордстата?
- Пошаговый алгоритм работы с сервисом:
- Как создать семантическое ядро?
- SpyWords
- Парсинг
- Распределение семантического ядра: внешняя оптимизация сайта
- Как группировать запросы
- Как правильно настроить Словоеб
- Изучайте трудность ключевых слов
- Для чего нужен парсинг частотности
- Этап второй. Сбор поисковых подсказок
Serpstat
Serpstat — многофункциональный сервис для поисковой оптимизации сайта, один из самых популярных сервисов на рынке с внушительным набором наград.
Serpstat похож на сервис SpyWords. Его возможности:
- анализ сразу нескольких доменов конкурентов и скачивание их семантического ядра вместе с текстами объявлений и посадочными страницами;
- анализ уровня конкуренции по различным ключевым словам и их частотности;
- выгрузка списка конкурентов в поисковой выдаче и контекстной рекламе.
Программа платная, но есть пробный период. После него за минимальный тариф Lite придется платить 69$ в месяц без учета скидок.
На мой взгляд, сервис поможет бизнесу создать лучший контент и привлечь качественный трафик на ваш сайт.
Составление семантического ядра — ключевой момент создания рекламной кампании и продвижения сайта в выдаче, который занимает значительную часть времени PPC-специалиста. А с сервисами подбора и анализа семантики вы забудете об этих долгих и утомительных процессах.
Подбор эффективных запросов в Google AdWords
Хочу поделится с Вами своим методом подбора эффективных ключевых слов в Google. Этим методом можно подбирать любые слова, а главное отсеивать ненужные (хорошее подспорье не только для новичков — примечание редактора). Всем Вам известен Инструмент AdWords для подсказки ключевых слов.
Итак, начнем. Идем в инструмент https://ads.google.com/home/ , желательно использовать его в зарегистрированном аккаунте.
Вводим слово и выбираем “C моим списком слов”:
В зависимости от тематики, добавляем минус слова. И выбираем Точное соответствие.
Теперь перед нами список слов в двух вариантах. Чтобы не получилось такого…
Слово – Мир – Целевой регион
… Добавляем фильтр
Убираем Широкое значение слова. Теперь все это сохраняем, то есть, сохраняем только Точные.
Не думайте что слов много, их будет намного меньше. Открываем загруженный файл. Перед нами много столбцов
Удалите столбец Уровень конкуренции и Кол-во запросов в месяц (весь мир)
Зачем нам мир , если нам интересен регион. Поставьте первые два столбца так:
- Ключевое слово
- Кол-во запросов в месяц (целевые регионы)
Следом идут месяца (в файле они будут). Остальное удалите. Теперь внимательно все просматриваем и убираем неподходящие Вам слова.
Отсортируйте все по столбцу “Кол-во запросов в месяц (целевые регионы)” От минимального к максимальному. Если у Вас был фильтр (как я писал выше), то нулевых запросов у Вас не будет. Но вот теперь самое интересное, убираем сезонные или стихийные запросы. Например:
Запрос “причины мирового экономического кризиса”
- Широкое 170
- Точное 110
А последние 4 месяца 0! запросов, то есть их не было четыре месяца и, наверное, не будет уже (на момент написания, google обновил базу и поставил не 110 а 16, но я подбирал неделей ранее). Вывод: Если Вы подбираете слова «на долго», то смотрите на месяца. Чтобы запрос был стабилен.
Данный метод эффективен для НЧ запросов и, собственно, для трафикового продвижения.
Какие есть парсеры для Вордстата?
Обработка запросов в ВордСтат возможна только в ручном режиме. Это увеличивает время формирования семантического ядра (СЯ) даже для небольшого проекта. Для автоматизации разрабатывают программы и онлайн-сервисы – парсеры. Они собирают данные статистики Яндекс, используя технологию API и другие программные комплексы. В итоге пользователь может обрабатывать большой объем информации.
Цель работы парсеров – актуальная статистика ключевых фраз с возможностью углубленного анализа по параметрам. Это реализуется следующими способами:
- Программы. Сбор актуальной статистики WordStat, анализ по критериям пользователя. Условия использования – условно-бесплатное или платное.
- Онлайн-сервисы. По сравнению с программами обладают меньшим функционалом. Преимущества – экономия времени, не нужно устанавливать ПО.
- Специализированные программы. Разрабатываются для решения узконаправленных задач.
Выбор зависит от объема запросов и точности результатов. Онлайн-сервисы скачивают данные из Яндекса, чтобы уменьшить время формирования отчета. Поэтому информация не объективная. На это влияет частота обновления баз конкретного парсера.
Пошаговый алгоритм работы с сервисом:
Создание задачи. Чтобы создать задачу, необходимо перейти во вкладку Wordstat и нажать «Создать новую задачу»
Шаг первый: Поисковая система и регион.
Здесь необходимо ввести название задачи (обязательное поле). Можно ввести любое название, часто бывает удобно вводить название сайта, чтобы в будущем легко найти нужную задачу.
Выберите регион.
Шаг второй: Настройки сбораЗдесь есть два чекбокса от выбора которых, будет зависеть тип задачи:
Сбор ключевых слов из левой колонки Wordstat
Сбор частотности (популярности ключевых слов)
Во вкладке «Сбор ключевых слов из левой колонки Wordstat», где вы указываете количество страниц выдачи Wordstat, по которым пройдет робот. Чем глубже идет робот – тем больше ключевых слов можно получить — «Парсить страниц»
Так же вы можете выбрать «Сбор ключевых слов с правой колонки». В такому случае вы соберете ключевые слова с левой и правой колонки Wordstat Сбор частотности (популярности ключевых слов)
Вы указываете необходимый вам тип частотности
Также здесь есть возможность не собирать частотности ниже заданного предела.
В парсинге вордстата используется умный алгоритм, он обходит ограничения в 7 слов, которое есть при парсинге через Яндекс.Директ (парсинг через Яндекс.Директ использует большинство оптимизаторов при работе в кей коллекторе).
Шаг третий: «Ключевые слова и цена».Загружаем запросы.
Можно загрузить списком либо через файл. Поддерживаемые форматы файла: xls, xlsx. Необходимо указать столбец, из которого должны браться данные, а также учитывать или нет первую строку.
Функционал стоп-слов позволит отфильтровать ваш список и сэкономить время и средства. Вы можете воспользоваться готовым списком стоп-слов — выбрать стоп-слова по тематикам и нужный вам регион.
«Эксперт опции» позаботиться о том, что бы вы не потеряли нужные слова
Обращаем внимание, что по умолчанию применяется символьное соответствие — т.е. стоп-слово «бу» удалит слова и фразы содержащие в себе сочетания букв «бу» — «бублик, бу холодильник, бумага» и т.д
Если выбрать фразовое соответствие стоп-слово «бу» удалит только слово / сочетания слов со словом «бу» — «бу холодильник, купить холодильник бу, бу», но не «бумага, бумеранг» и т.п.
Затем нажимаем «Создать новую задачу».
На странице списка задач виден статус заявки.
Очередь – данные еще не собираются. Сбор данных – счетчик показывает, сколько ключевых слов обработано.На паузе – вы можете вручную поставить задачу на паузу, если не уверены, что хотите его собирать. Или же, задача может сама встать на паузу т.к. у вас кончились деньги на балансе.Готов – и рядом появляется возможность скачать .xlsx файл.
После завершения обработки вы можете сразу отправить файл на кластеризацию.
Экспортный файл имеет вид:
А так же вы можете создать задачи по парсингу Wordstat: сбор левой колонки и проверка частотности через API (api wordstat yandex) — https://www.rush-analytics.ru/api
Как создать семантическое ядро?
Формирование семантического ядра — это комплексный процесс, включающий анализ тематики и структуры сайта, работу со специальными сервисами и программами, редактирование базы ключей вручную. Есть два основных принципа создания СЯ:
- подбор максимального количества ключей и дальнейшей очистки;
- подбор точных ключевых фраз с самого начала с последующим расширением базы.
Мы обратились к нескольким SEO-экспертам, чтобы узнать, какой подход они предпочитают.
Тарас Гуща, СЕО в SEO.UA, склоняется к первому методу:
Лучше много ключей и потом чистить. Потому как иногда можно упустить весьма стоящие ключевые фразы. Нам как профессионалам продвижения сайтов надо давать клиентам максимальный результат. Поэтому каждая ключевая фраза, которая может конвертировать потенциальную аудиторию в клиента, очень важна.
А вот Катерина Золотарева, Founder & CEO в Site24, считает, что в зависимости от выбранной стратегии можно использовать оба подхода:
Если проект небольшой или в сложной для формирования семантики нише, например, технологические услуги, то однозначно надо собирать все и даже больше, потом вычеркивать нерелевантное, а околотематические ключи отправлять в блог.
Также имеет смысл глубоко заниматься семантикой, если проект уже имеет позиции, трафик, а стандартные базовые ключи и так уже включены в метатеги и текст. Тогда глубокая проработка семантики поможет вам значительно улучшить видимость и трафик.
Этапы создания семантического ядра
Создание СЯ можно разделить на три этапа.
- Выбор подхода для создания СЯ.
Есть несколько стратегий того, как можно собрать семантического ядро. Их применяют в зависимости от того, имеет ли ресурс структуру или только находится в процессе разработки, какой у него уровень оптимизации, какие позиции по ключевым словам он занимает и т.д..
- Сбор запросов с помощью специальных инструментов.
Сервисы подбора ключевых слов дают возможность охватить максимальное число запросов и поисковых подсказок. Для лучшего результата стоит задействовать инструменты для анализа семантики конкурентов.
- Формирование СЯ из общей базы запросов.
Этапы преобразования облака тематических запросов в семантическое ядро включают два основных этапа:
- очистка базы ключей от ненужных запросов;
- кластеризация путем деления семантики на группы.
Также в процессе анализа ключей можно отделить минус-слова. Кластеризация базы запросов предшествует распределению ключевых фраз по URL. В следующих разделах мы рассмотрим все этапы разработки семантического ядра подробно.
Подходы при создании семантического ядра
Рассмотрим стандартные схемы для создания баз ключей. В зависимости от конкретного случая можно использовать один из подходов, приведенных ниже, или же индивидуальную стратегию.
ПЕРВЫЙ ПОДХОД — ФОРМИРОВАНИЕ СТРУКТУРЫ НОВОГО САЙТА НА ОСНОВЕ СЯ.
- Исследование рыночной ниши/торговой линейки/брифа клиента.
- Определение списка основных запросов (seed keywords).
- Сбор максимального количества фраз для каждого основного ключа.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Очистка полученного списка запросов от дублей и мусорных фраз (при наличии списка минус-слов).
- Автоматическая кластеризация через SE Ranking.
- Окончательная очистка запросов.
- Создание структуры сайта по разделам, категориям, страницам на основе кластеризации.
ВТОРОЙ ПОДХОД — СБОР СЯ ПОД ГОТОВУЮ СТРУКТУРУ САЙТА
- Анализ структуры и разделов сайта.
- Определение списка основных запросов.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Сбор максимального количества релевантных ключевых фраз для запросов из п. 2 и 3.
- Очистка от мусорных и нерелевантных фраз.
- Разделение собранных запросов под существующие категории и страницы.
ТРЕТИЙ ПОДХОД — ОБНОВЛЕНИЕ СЕМАНТИЧЕСКОГО ЯДРА ДЛЯ САЙТА.
- Анализ существующей семантики сайта.
- Поиск «слабых мест»: сбор актуальных запросов в тематике, изучение поисковых подсказок, анализ конкурентов для определения недостающих ключей.
- Создание списка упущенных запросов и распределение их по разделам, категориям, страницам.
SpyWords
Сервис SpyWords позволяет определить нишу своего сайта, подобрать нужные ключевые слова, а также отслеживать показатели конкурентов.
Возможности SpyWords:
- Определение перспективных продуктов и ниш для запуска рекламы;
- Определение перечня конкурентов по конкретному запросу;
- Анализ конкурентов по контексту и поиску;
- Определение списка ключевых слов конкурентов;
- Просмотр преимуществ, которые конкуренты указывают в рекламе;
- Получение семантического ядра по заданному ключевому слову;
- Получение семантического ядра конкурентов.
Тарифы:
|
Период |
Business |
PRO |
Unlim |
|
12 месяцев (3 бесплатных месяца) |
312 долларов |
387 долларов |
780 долларов |
|
6 месяцев (1 бесплатный месяц) |
173 доллара |
215 долларов |
434 доллара |
|
1 месяц |
35 долларов |
43 доллара |
87 долларов |
|
1 сутки |
7 долларов |
9 долларов |
18 долларов |
Парсинг
После составления масок, их необходимо «распарсить», т.е. собрать список ключевых запросов, которые образовываются с помощью наших масок. Эти запросы также называют «хвостом».
Для парсинга мы используем Кей Коллектор. Это программа, которая создана специально для работы с семантическим ядром. Она платная, но на сегодня это лучший инструмент для работы с СЯ.
Если вы настраиваете кампании только для себя, возможно, нет смысла покупать ее. В таком случае можете попробовать ее бесплатный аналог «Словоеб» или собрать запросы в ручную с помощью Wordstat или инструмента для работы с ключевыми словами от Google Ads.
Чистка списка фраз
После парсинга, в зависимости от ниши, мы могли получить несколько тысяч или даже десяток тысяч ключевых слов. Но подходит нам только часть этих фраз.
Чтобы не показывать рекламу незаинтересованным пользователям и не сливать рекламный бюджет в пустую, нам необходимо собрать список минус-слов, которые будут блокировать рекламу по неподходящим нам запросам.
Например, если вы распарсили запрос ремонт квартир, то там будут такие запросы, как ремонт квартир своими руками или ремонт квартир книги. Своими руками и книга говорят о том, что человек не собирается заказывать услуги, а хочет сделать ремонт самостоятельно, поэтому нам нет смысла показывать им рекламу. Мы добавляем эти слова в список минус-слов.
Околоцелевы запросы
Например, вы продаете детские коляски. Ваша целевая аудитория — молодые мамы. Вы начинаете думать, что могут искать молодые мамы в интернете и добавляете такие фразы: детская кроватка, автокресла, комбинезон для новорожденного и т.д.
В теории такой подход может сработать, но есть нюансы:
1) за эти запросы тоже конкурируют рекламодатели и они могут быть дороже, чем ваши целевые запросы; 2) ваша реклама будет нерелевантной – человек интересуется детской одеждой, а вы ему предлагаете купить коляску. На поиске Google и Яндекс кликов будет мало и они будут дорогие. В РСЯ, как показывает опыт, также будет мало показов, низкий CTR и низкая конверсия.
Такие запросы можно протестировать, если вы уже используете основные источники трафика, но вам этого мало и хотите расширяться.
Информационные запросы
Перед покупкой товара или заказом услуги люди проходят разные этапы заинтересованности. Например, перед тем, как купить кроссовки для бега, человек может искать информацию в интернете, как правильно выбрать кроссовки для бега, а перед покупкой нового матраса — информацию об улучшении качестве сна.
С помощью контекстной рекламы мы можем обращаться к пользователям на разных этапах принятия решения. Но будет большой ошибкой пытаться продавать им «в лоб» и вести их сразу на страницу товара или услуги. Скорее всего, они ничего не закажут, а просто закроют сайт.
Чтобы реклама на околоцелевые запросы дала результаты, нужно подготовить релевантные и интересные для пользователей страницы, с которых вы уже будете вести их вниз по воронке продаж.
Распределение семантического ядра: внешняя оптимизация сайта
Теперь кластеры нужно проанализировать и распределить по посадочным (целевым) страницам вашего сайта. Если есть похожие по смыслу кластеры — не нужно создавать под них отдельные страницы и тем самым плодить дублированный контент. Отбираем из них самый частотный кластер и его используем. Не пытайтесь также распределить на одной странице сразу несколько кластеров — это не приведет к успеху, придерживайтесь структуры и правила: каждый кластер = отдельному URL на сайте.
Когда вы уже определились с URL-страниц для своих кластеров, нужно подготовить техническое задание, чтобы распределить ключевые слова с точки зрения SEO-оптимизации. Переходим в инструмент Текстовый Анализатор SEO и создаем в нем под каждый кластер отдельный проект. Добавляем ключевые слова и запускаем проект. Текстовый Анализатор проанализирует тексты сайтов-конкурентов из выдачи ТОПа и сгенерирует ТЗ, которые дальше вы можете отправить копирайтеру.
Отдельно про функционал Текстовый Анализатор мы рассказывали в предыдущих материалах:
- Базовое руководство по Текстовому Анализатору
- Статья «Работаем с Текстовым Анализатором»
- Видеоруководство по Текстовому Анализатору
- Вебинар по Текстовому Анализатору
Как группировать запросы
Чтобы понять, как распределять ключевые слова по отдельным страницам, нужно сгруппировать запросы. Для этого надо создать семантические кластеры.
Чаще всего, ключевые слова из кластеров первого и второго уровней определяются еще на этапе мозгового штурма. Для этого просто нужно хорошо разбираться в своем продукте или ориентироваться на структуру сайтов-конкурентов. Семантика остальных подуровней определяется на этапе детального составления семантического ядра и его кластеризации
Еще одно важное условие — каждая группа запросов последнего уровня должна соответствовать одной потребности пользователя. Например, покупка конкретного вида детского белья
Используем Словоёб с уже известной нам функцией быстрого фильтра. С его помощью можно легко отсортировать фразы по категориям для дальнейшего внедрения на посадочных страницах.
1. Введите в поле быстрого фильтра базовое ключевое слово, которое может станет названием для категории/подкатегории/посадочной страницы (например, бренд детского постельного белья «Непоседа») и нажмите Enter.
2. Выделите нужные фразы и скопируйте их.
3. Удалите отмеченные строки правой кнопкой мыши.
4. Создайте в правом меню новую группу (например, с названием «Непоседы»).
5. Для добавления только что выбранных фраз в эту группу, перейдите во вкладку «Данные» — «Добавить фразы».
6. Вернитесь к прежнему списку нажатием клавиши Enter в поле поиска быстрого фильтра.
7. Повторите эту процедуру с другими запросами. Ключевые фразы автоматически выстроятся в алфавитном порядке, благодаря чему можно легко удалить лишние слова или выделить похожие фразы в отдельную группу.
Группировка вручную требует много времени (особенно в том случае, если семантика достаточно широкая). Для автоматизации этого процесса можно использовать платные Key Collector, Rush-Analytics, Just-Magic, или бесплатный скрипт Devaka.ru. Часто приходится объединять некоторые группы запросов. Например, такие:
Согласитесь, создавать две отдельные категории под фразы «красивое белье» и «стильное белье» неразумно 🙂 Для понимания важности фраз для каждой категории/посадочной страницы, скопируйте их в Планировщик ключевых слов Google в раздел «Получение статистики запросов и трендов»:
Так вы проверяете популярность (частотность) поискового запроса. В целом все поисковые запросы делятся на:
- ВЧ-запросы (высокочастотные).
- СЧ-запросы (среднечастотные).
- НЧ-запросы (низкочастотные).
- Микро НЧ-запросы.
При этом нет точных цифр, по которым можно с уверенностью сказать, что запрос принадлежит к определенной группе. Все зависит от тематики сайта. В одних тематиках фраза с частотностью 1000 запросов в месяц может быть низкочастотной (фильмы, музыка), в других — 200 запросов уже может быть признаком высокочастотной фразы (финансовая тематика). Соотношение этих групп: Наиболее высокочастотные запросы впоследствии вписывайте в метатеги. А под низкочастотные оптимизируйте страницы сайта. Как правило, они очень низкоконкурентны, и достаточно провести качественную работу с текстами, чтобы вывести соответствующие страницы в ТОП.
Читайте, как привлечь целевой трафик на сайт с помощью формирования максимально широкого семантического ядра.
После всех этих манипуляций вы получите подробную структуру сайта, состоящую из ключевых фраз для:
Как правильно настроить Словоеб
Основные инструменты
При помощи программы Словоеб можно:
- Осуществить пакетный подбор слов используя правую и левую колонку Yandex.Wordstat. Можно данные действия провести и вручную, зайдя на сайт статистики поисковых запросов Яндекс, но это довольно долго и не весьма удобно, лучше использовать данную программу.
- Осуществить пакетный подбор слов используя Rambler. Adstat. Возможность аналогична с 1 пунктов, только на основании данных статистики запросов поисковика Rambler. Я эти возможности не использую, мне вполне хватает данных Яндекса.
- Определить конкурентность по данному запросу. Тут всё просто, чем выше конкурентность данного запроса, тем сложней его продвинуть и войти по нему в ТОП по поисковой выдаче.
- Определить релевантные страницы по данному запросу в Яндекс и Google. Программа поможет определить релевантную страницу по каждому ключевому запросу и место в выдаче Яндекса и Google по вашему КС. К примеру, если я ранее подбирал ключевые слова и написал под них заметку, то через время можно проверить, есть ли в выдаче основных поисковиков мой сайт по данным запросам.
- Проверить сезонность поисковых запросов, определить KEI (Keyword Effectiveness Index (KEI) — оценка ключевого слова, выраженная в цифровом значении, дающая представление о его эффективности, с точки зрения поискового продвижения). Эти возможности считаю дополнительными и использую редко))
Вот, в принципе, все возможности программы, рекомендую всем, кто пишет статьи, использовать её возможности. Это поможет вам правильно подбирать ключевые фразы и слова и использовать их грамотно в теле заметки. Подробно о том, как правильно писать статьи, рекомендую почитать:
Где скачать программу Словоеб и Key Collektor
Как всегда, рекомендую вам скачивать софт с официальных сайтов разработчика
Скачать бесплатную программу Словоеб и Key Collektor можно тут — http://seom.info/tools/
На странице ищите нужную вам программу и скачивайте самую актуальную версию.
После того, как программу скачаете, распакуйте архив, запускайте программу файлом Slovoeb, после чего нужно внести корректные настройки и данные своих аккаунтов Яндекс и Рамблер, чтобы была возможность парсить запросы.
Настройка программы Словоеб
Любой инструмент для корректной работы необходимо правильно настроить, будь то пианино или софт для вебмастера
После запуска программы находим слева вверху иконку в виде шестеренки (настройки) и переходим в эту вкладку.
Мы пройдёмся детально только по первому разделу «Парсинг», про остальные расскажу коротко, они не столь важны.
Парсинг => Общие
Настройки, которые я выделил на скриншоте выше желтым, вам необходимо сверить со своими. Дело в том, что по умолчанию, с выходом обновлений программы эти цифры могут изменяться. Я выбрал оптимальные и предлагаю вам выбрать такие же параметры, если у вас своё мнение, пожалуйста, выбирайте те цифры, которые для вас являются оптимальными, не возражаю ))
Парсинг=> Yandex.Wordstat
Тут настройки я также слегка подкорректировал и выставил следующие:
Я установил минимальное значение «фразы с частотностью» не менее 25, поскольку для ключевых слов менее 25 писать заметки не стоит, не будет результата и трафика))
Парсинг=> Yandex.Direct
Далее 3 подраздела главы «Парсинг» я пропускаю ( Rambler, поисковая выдача и подсказки) и обращаю ваше внимание на то, что необходимо обязательно внести данные своего аккаунта Яндекс в последний подраздел/
Настоятельно вам рекомендую создать новый аккаунт в Директ и внести его данные в настройках программы Словоеб. Внесите данные название аккаунта и пароль к нему через двоеточие-
логин: пароль
Внимание!
Если вы установили программу на новый ПК, то пароль и логин делайте
новый! Программа не будет работать с одним логином Яндекса на разных
устройствах! У меня на рабочем компе одни логин и пароль, на другом
другие данные Яндекса. Теперь ваша программа готова к обработке данных)) Если у вас часто выскакивает капча при работе программы и вам лень ее вводить ручками, можете воспользоваться сервисами, которые это сделают за вас (раздел настроек «Антикапча») Меня «капча» особо не беспокоит, поэтому я справляюсь сам, без помощи подобных сервисов
Теперь ваша программа готова к обработке данных)) Если у вас часто выскакивает капча при работе программы и вам лень ее вводить ручками, можете воспользоваться сервисами, которые это сделают за вас (раздел настроек «Антикапча») Меня «капча» особо не беспокоит, поэтому я справляюсь сам, без помощи подобных сервисов.
Также можно убрать при помощи настроек лишние колонки (я Рамблером не использую, мне Яндекса вполне хватает), изменить шрифт в программе (я размер на 14 выставил) и прочие мелочи, но это уже каждый сам сможет сделать.
Изучайте трудность ключевых слов
Выбранные ключи могут оказаться трудными для продвижения.
Да, вы можете выбрать клевую семантику, но ваши группы ключевых слов могут уже быть продвинутыми в ТОП у конкурентов.
Например, у ключа «Продвижение сайта и раскрутка сайта» разные ключи в ТОП. И по факту это тоже могут быть главные страницы сайтов.
Почему так? Все просто: в заголовке умещается максимум один ключ — больше длина не позволяет. Более того, очень сложно раскидать релевантный текст сразу на всю страницу, включив оба ключа и при этом не допустить переспама.
Для оценки трудности ключевых слов используйте Ahrefs. Просто добавьте свой список ключевых слов в сервис в разделе «Анализ ключевых слов».
В готовом результате изучите:
- Показатель KD (Keyword Difficulty) — чем ниже, тем лучше для вас.
- Сходную тематику. Расширьте запас ключевых слов в данной группе.
Учтите, сбор показателей метрик — платный. Следите за числом израсходованных метрик в сервисе.
Для чего нужен парсинг частотности
Оценка объема трафика по определенным ключевым словам
Частотность в Яндекс.Вордстат отображает количество показов по выбранному ключевому слову за месяц в определенном регионе. С помощью этих данных можно примерно рассчитать потенциальный объем трафика, который можно получать в поисковой выдаче на разных позициях.
Сделать это можно так:
1. Соберите целевую семантику (список ключевиков, по которым вам нужно получать поисковой трафик). Собрать семантику можно с помощью медиапланера от Click.ru.
2. Спарсите частотность ключевых слов. Для примера мы возьмем ключевик «купить Samsung Galaxy в Москве» и проверим его частотность непосредственно в Вордстате. Итого, по данному запросу – 11757 показов в месяц.
3. Найдите в интернете средние значения CTR для каждой из позиций первой страницы поисковой выдачи.
Если ваш сайт добавлен в Яндекс.Вебмастер и работает как минимум несколько месяцев, данные по CTR будут доступны в отчете «Поисковые запросы» → «Все запросы и группы».
К примеру, CTR для второй позиции – 18%. Теперь мы можем посчитать примерный уровень трафика, который можем получить. Формула для расчета:
(Частотность * CTR)/100
Подставляем в формулу наши данные: (11 757 * 18)/100 = 2116.
Конечно, нет гарантии, что мы получим точно такое количество посещений, но для примерной оценки потенциала запроса такие расчеты будут очень полезными.
Еще одна причина для сбора частотности ключей – фильтрация запросов с околонулевой частотностью
Фразы, по которым нет показов (или показов совсем мало – от 1 до 10), лучше убрать из семантического ядра и не тратить время на оптимизацию страниц под такие запросы.
По ним практически не будет трафика, а если запускать контекстную рекламу, объявления получат статус «мало показов» и не будут показываться.
Обратите внимание! Иногда семантику с низкой частотностью не нужно исключать из ядра. Это касается узкоспециализированных тематик, например дорогого медицинского или производственного оборудования
Там ключевые запросы с указанием точной спецификации оборудования могут иметь всего пару запросов в месяц, но приводить максимально целевую и горячую аудиторию.
На что ориентироваться
В зависимости от ниши и типа сайта нижний порог частотности, по которому нужно отсекать бесперспективные запросы, отличается. Для ориентира можете использовать следующие данные:
|
Ниша |
Отсеиваем запросы с частотностью |
|
Узкие тематики |
|
|
Масс-маркет |
до 5 |
|
Информационные ресурсы |
до 30–35 |
При удалении низкочастотных фраз будьте внимательны: НЧ-запросы приводят качественный трафик, поэтому удаляйте фразы аккуратно, оставляя целевые.
Этап второй. Сбор поисковых подсказок
Уверены, все не раз видели, что когда начинаешь вводить какой-то запрос в поисковике, он сам подписывает самые популярные варианты.
Выглядит это так. Google:
Или так. Яндекс:
Кстати, внимательный читатель может увидеть, что в достаточно популярном запросе среди реально важных подсказок затесалась подсказка, скорее всего, накрученная. Какая именно? А подумайте сами. Это тоже часть стратегии продвижения бренда, но совершенно из другой оперы. Просто наблюдение.
Вернемся к ключам. Все, что вы видите на скриншотах – поисковые подсказки. Вверху – более популярные, внизу – менее. Этакий ТОП-10. Реально их, конечно, больше. Мы с вами будем собирать поисковые подсказки, поскольку они тоже хорошо отражают интересы пользователей и это тоже ключи.
Для быстрого сбора подсказок мы идем на сайт и скачиваем там в самом низу малюсенькую программку «Словодёр». Работать с ней крайне просто:
Для справки:
Цифра 1. Вводим ключ
Цифра 2. Выбираем, из каких поисковиков будем собирать подсказки
Цифра 3. Если хотим, указываем «стоп-слова»
Цифра 4. Запускам
Цифра 5. Результат перед нами
Копируем наши подсказки в тот же .txt файл, где и хранятся наши остальные ключи, которые мы собрали ранее на сайте FastKeywords.