Парсер wordstat для статистики запросов яндекса: зачем нужен, как пользоваться и сколько стоит
Содержание:
- Основные операторы Яндекс ВордСтат
- Что такое Wordstat, и что он показывает?
- Особенности использования Яндекс.Wordstat
- Базовые функции
- Другие сервисы и программы подбора ключей для Яндекс
- Для чего нужен парсинг частотности
- Другие особенности работы операторов
- Yandex Wordstat Assistant
- Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
- Парсеры Вордстата
- Другие возможности сервиса
- Маркерные запросы
- Обзор других функций программы
- Какие есть парсеры для Вордстата?
- Зачем нужен Вордстат?
- Исключаем из парсинга отдельные группы товаров/услуг
- Заключение
- Заключение
Основные операторы Яндекс ВордСтат
Существует два основных оператора:
- Восклицательный знак.
- Кавычки.
Также они могут использоваться вместе друг с другом. Рассмотрим суть применения каждого оператора на примере простейшего запроса.
Восклицательный знак
Прописав перед словом ! вы фиксируете окончание у слов, перед которым стоит знак !.
То есть, написав !купить !телефон, в отображаемые показы уже не будет входить склонения слов, например: телефоны, купил и другие измененные окончания и склонения слов перед которыми стоит !. Но сюда в эти показы входят все фразы которые имею точно написание купить телефон, например в эти показы входят такие запросы: как купить сотовый телефон, где купить телефон и т.д.
Восклицательный знак фиксирует только точное написание этих слов перед которыми он стоит.
Посредством базового оператора «Восклицательный знак» пользователь может посмотреть результаты по конкретному запросу без каких-либо склонений одного либо нескольких слов, содержащихся во фразе.
Кавычки
Введя фразу «купить телефон» в кавычках, вы увидите количество показов лишь данного запроса без других каких либо дополнительных слов, то есть в этот запрос могут входить фразы: купить телефоны, телефоны купить, купил телефон и т.д. Сюда уже не входят другие дополнительные слова, например: как купить телефон, где купить сотовый телефон и т.д.
Значение в кавычках называют фразовой частотностью.
Совместное применение операторов кавычки + восклицательный знак
Прописав «!купить !телефон», вы зафиксируете и сам запрос, и окончания у слов. Таким образом, вы узнаете точную частоту по конкретному запросу без дополнительных слов, позволяющую спрогнозировать число переходов по этому запросу. Но помним, число показов — это не число переходов, поэтому это лишь примерные данные, так же надо понимать что количество кликов уменьшается в зависимости от позиции сайта в выдаче поисковой системы по данному запросу.
Значение ковычки+восклицательный знак называют точной частотностью.
Что такое Wordstat, и что он показывает?
SEO-специалисту для сбора семантического ядра приходится работать с сервисом . Что же на самом деле означают цифры напротив вводимых фраз, и как они считаются?
Для начала посмотрим, что знает об этом сервисе поисковая система Google? На вопрос: «Что такое Вордстат?» — она выдает блок с быстрым ответом, суть которого состоит в следующем: Wordstat Yandex — это сервис статистики показов рекламных объявлений Яндекс.Директа по определенному поисковому запросу.
Само же описание Вордстата гласит: Подбор ключевых слов Яндекса — это сервис для оценки пользовательского интереса к конкретным тематикам и для подбора ключевых слов рекламодателями Яндекс.Директа. Сервис содержит подробную статистику запросов к Яндексу за последние 30 дней.
Получается, что в описании Вордстата не идет речь об показах объявлений Яндекс.Директа. В связи, с чем возникают следующие вопросы:
- Что на самом деле показывает Вордстат?
- Если считаются показы рекламных объявлений, то могут ли раздельно учитываться показы объявлений в блоках «Спецразмещение» и «Гарантия».
- Как считаются показы при переходе на вторую и следующие страницы результатов поиска? Если объявления повторяются на второй странице, будут ли засчитаны показы на ней?
- Если рекламных объявлений по поисковой фразе нет, означает ли это, что данная поисковая фраза не попадет в Wordstat?
- Какое количество запросов должно быть у фразы, и каким дополнительным требованиям она должна соответствовать, чтобы попасть в Wordstat?
- Если объявления показаны исключительно по синониму, будут ли засчитаны показы? Если да, то по поисковой фразе или по синониму?
С этими вопросами мы обратились к поддержке Яндекса и получили следующие ответы:
➔ Wordstat отображает статистику запросов, введенных в строку поиска, без привязки к объявлениям Директа и блокам «Спецразмещение» и «Гарантия».
➔ Запрос введенный в поисковую строку единожды, будет учтен 1 раз, независимо от того, сколько страниц вы просмотрите, сколько и какие объявления будут показаны. Запрос будет учтен, даже если по нему нет объявлений. Чтобы фраза попала в Вордстат, она должна пройти антиспам фильтр и набрать частотность не ниже 5.
Получается, что даже Google не дает верного определения сервису Wordstat. Хорошо, что на тему применения Вордстата разногласий не возникает:
Итак, этот сервис нужен для:
- Сбора поисковых фраз для SEO, контекста и др.;
- Анализа сезонности и географической зависимости запроса.
В следующей части статьи коснемся особенностей работы с операторами в Wordstat и рассмотрим другие полезные с точки зрения SEO возможности сервиса.
Особенности использования Яндекс.Wordstat
При использовании сервиса помните:
- Яндекс.Wordstat не показывает тренды. Здесь можно узнать статистику показов в течение последнего месяца.
- Есть возможность оценить сезонность запросов с помощью «Истории запросов».
- В «Истории запросов» операторы не используются.
- Данные в «Истории запросов» показывают в абсолютных и относительных цифрах. В первом случае количество показов по рассматриваемой фразе. Во втором — соотношение показов по этому слову и всех запросов в течение этого же времени.
- Существуют ограничения на результаты выдачи. На странице может быть представлено не более 50 запросов. При этом максимальное количество страниц — 40.
Базовые функции
Для начала приведем список действий, которые доступны во всех расширениях:
2) Помимо фраз из выдачи Wordstat есть возможность добавлять собственные ключевые фразы в интерфейсе расширений;
3) В каждый плагин встроены счетчики количества фраз и частотности – то есть можно посмотреть по получившемуся списку общее количество ключей и суммарную частотность;
4) Для удобства работы можно сортировать список по частотности, алфавиту и порядку добавления;
6) При закрытии Вордстата все данные сохраняются в аккаунте, под которым вы их добавляли.
Всеми плагинами можно пользоваться бесплатно.
Далее мы рассмотрим алгоритм установки и как пользоваться этими и другими функциями в каждом из расширений.
Другие сервисы и программы подбора ключей для Яндекс
- Key Collector. Самый популярный автоматизатор сбора семантического ядра. Собирает фразы, очищает от лишних, фильтрует по эффективности. Добротный инструмент с обилием функций. Платный.
- Slovoeb. Бесплатный аналог Key Collector для парсинга и формирования точного семантического ядра.
- Serpstat. Одна из крупнейших SEO-платформ, располагает широкими возможностями парсинга ключевых слов и анализа конкурентов.
- Semrush. Также мощный SEO-инструмент для всесторонней аналитики запросов.
- Яндекс.Директ. Провести первичный анализ ключевых слов рекламодатель может непосредственно в своём кабинете в Яндексе с помощью инструмента «Прогноз бюджета».
Для чего нужен парсинг частотности
Оценка объема трафика по определенным ключевым словам
Частотность в Яндекс.Вордстат отображает количество показов по выбранному ключевому слову за месяц в определенном регионе. С помощью этих данных можно примерно рассчитать потенциальный объем трафика, который можно получать в поисковой выдаче на разных позициях.
Сделать это можно так:
1. Соберите целевую семантику (список ключевиков, по которым вам нужно получать поисковой трафик). Собрать семантику можно с помощью медиапланера от Click.ru.
2. Спарсите частотность ключевых слов. Для примера мы возьмем ключевик «купить Samsung Galaxy в Москве» и проверим его частотность непосредственно в Вордстате. Итого, по данному запросу – 11757 показов в месяц.
3. Найдите в интернете средние значения CTR для каждой из позиций первой страницы поисковой выдачи.
Если ваш сайт добавлен в Яндекс.Вебмастер и работает как минимум несколько месяцев, данные по CTR будут доступны в отчете «Поисковые запросы» → «Все запросы и группы».
К примеру, CTR для второй позиции – 18%. Теперь мы можем посчитать примерный уровень трафика, который можем получить. Формула для расчета:
(Частотность * CTR)/100
Подставляем в формулу наши данные: (11 757 * 18)/100 = 2116.
Конечно, нет гарантии, что мы получим точно такое количество посещений, но для примерной оценки потенциала запроса такие расчеты будут очень полезными.
Еще одна причина для сбора частотности ключей – фильтрация запросов с околонулевой частотностью
Фразы, по которым нет показов (или показов совсем мало – от 1 до 10), лучше убрать из семантического ядра и не тратить время на оптимизацию страниц под такие запросы.
По ним практически не будет трафика, а если запускать контекстную рекламу, объявления получат статус «мало показов» и не будут показываться.
Обратите внимание! Иногда семантику с низкой частотностью не нужно исключать из ядра. Это касается узкоспециализированных тематик, например дорогого медицинского или производственного оборудования
Там ключевые запросы с указанием точной спецификации оборудования могут иметь всего пару запросов в месяц, но приводить максимально целевую и горячую аудиторию.
На что ориентироваться
В зависимости от ниши и типа сайта нижний порог частотности, по которому нужно отсекать бесперспективные запросы, отличается. Для ориентира можете использовать следующие данные:
|
Ниша |
Отсеиваем запросы с частотностью |
|
Узкие тематики |
|
|
Масс-маркет |
до 5 |
|
Информационные ресурсы |
до 30–35 |
При удалении низкочастотных фраз будьте внимательны: НЧ-запросы приводят качественный трафик, поэтому удаляйте фразы аккуратно, оставляя целевые.
Другие особенности работы операторов
Выше мы перечислили далеко не все возможности, которые способно предоставить оптимизатору применение операторов в Yandex Wordstat. Вот ещё несколько примеров и правил работы с ними:
В запросе в кавычках » » или прямых скобках местоимения, предлоги и союзы по умолчанию включены, поэтому не обязательно писать перед ними оператор «+».
Важно однако понимать, что операторы минус-слова «-», вертикальная черта «|», группировка запросов «()» не получится использовать внутри операторов кавычки » » или прямые скобки []
Но прямые скобки [] внутри круглых () использовать можно:
В квадратных скобках слова не объединяются:
Оператор » » нельзя применить к отдельной фразе:
Yandex Wordstat Assistant
Расширение устанавливается в 3 простых шага:
1) Скачайте актуальную версию расширения для браузера, в котором работаете с Яндекс Wordstat: Google Chrome, Mozilla Firefox, Opera или Яндекс Браузер.
Для всех браузеров алгоритм одинаковый. Мы покажем, как устанавливать и пользоваться возможностями Wordstat Assistant, на примере Google Chrome.
2) Нажмите кнопку для установки:
3) Подтвердите, что собираетесь установить расширение:
На этом всё готово, остается проверить, установилось ли расширение.
Если всё корректно, вы увидите:
Значок с таким уведомлением – теперь он всегда будет отображаться в вашем браузере.
Если такого значка нет, попробуйте перезапустить браузер.
Панель управления Wordstat Assistant в левой области страницы Яндекс Wordstat – в неё будут попадать все ключевые фразы, которые вы добавите.
На случай, если панель не появится, обновите страницу или также перезапустите браузер.
Знак «+» напротив каждого результата и в левой, и в правой колонке – нужен, чтобы добавлять фразы в список.
Чтобы его увидеть, введите нужную фразу, как обычно в Вордстате, например:
Рассмотрим все функции по порядку.
1) Добавление и удаление фраз из списка
Можно добавить в список отдельную ключевую фразу, нажав на плюс, или все фразы из таблицы (именно с той страницы, на которой вы находитесь, а не из всей выдачи), нажав ссылку «Добавить все»:
Например, мы хотим добавить все похожие фразы из левой колонки с первой страницы. Жмем «Добавить все», в окне подтверждения – «Добавить»:
Выглядит это так, в скобках указана частотность для каждого запроса:
Над списком отображается общее количество фраз, которые вы добавили, и суммарная частотность по ним:
В результатах поиска Yandex Wordstat фразы, которые вы выбрали, становятся серого цвета, со знаком минус вместо плюса.
Эти опции при необходимости можно отключить здесь:
По знаку «–» фразу можно в любой момент удалить из результатов поиска Яндекс Wordstat (1). Либо можно удалить прямо её из панели управления: для этого наведите на фразу курсор и кликните по минусу рядом с ней (2). Чтобы очистить весь список, нажмите крестик вверху панели управления (3).
При попытке добавить такой же ключ, какой уже есть в списке, Wordstat Assistant выдает сообщение:
2) Добавление собственных ключей
Для этого нажмите плюс на панели управления, введите запрос или список запросов, как на скриншоте:
Для добавленных вручную фраз вместо частотности показывается знак вопроса:
Если ваша фраза совпадает с фразой из результатов поиска Wordstat, последняя выделяется серым цветом. Но частотность при этом остается неизвестной (?), а не перетягивается из данных Wordstat.
3) Сортировка списка ключевых фраз
Её можно выполнять с помощью этой кнопки:
Она меняет свой вид в зависимости от того, по какому признаку вы сортируете фразы:
По возрастанию и убыванию частотности:
По алфавиту:
По порядку добавления (вновь добавленные в конец / в начало списка):
4) Копирование данных из Вордстата
Можно скопировать просто список фраз (1), либо список фраз вместе с фразами значения частотности (2), чтобы работать с ними дальше в любом формате – например, txt или Excel:
Чтобы автоматически удалить знак «+» из всех фраз, задайте эту настройку:
Если вы закроете вкладку с Wordstat или браузер, ничего не потеряется. Список сохранится под тем аккаунтом, в котором вы его сформировали.
Быстрый парсинг всех ключевых слов и объявлений для указанных доменов
Создайте аккаунт в системе PromoPult (или авторизуйтесь, если у вас уже есть аккаунт). Откройте инструмент «Слова и объявления конкурентов». В блоке «Добавить задачу» укажите домены конкурентов или загрузите их с помощью XLSX-файла.
Блок профессиональных настроек пока не трогаем (мы еще разберем его).
В блоке «Поисковые системы» можно выбрать, в какой поисковой системе проверять домены. По умолчанию это Яндекс и Google. Также по умолчанию стоит галочка на пункте «Результаты на едином листе XLS» — в таблице с результатами данные по всем доменам будут сведены на одном листе.
Если вы проверяете небольшое количество доменов (до 5), можете ничего не менять здесь. Если же доменов больше, уберите галочку с этого пункта. В результатах парсинга под каждый домен будет создан отдельный лист — это удобнее для анализа большого количества данных.
Жмем «Запустить проверку». Система начнет парсинг доменов (в нашем случае на это ушло 5 минут). Если у вас нет времени ждать, вы можете закрыть страницу с инструментом — все работы проводятся в фоновом режиме.
После окончания проверки вам на почту придет уведомление:
Раскройте блок «Список задач» и кликните по пиктограмме Excel-таблицы, чтобы скачать отчет. Также здесь можно удалить отчет или запустить повторный парсинг.
В настройках парсинга есть возможность выбрать отображение отчета: отдельный лист для каждого домена или все на одном листе.
В зависимости от этой настройки отчет будет выглядеть по-разному.
Отчет по каждому домену на разных листах
В нашем примере мы получили именно такой отчет. При скачивании загружается архив с файлами в формате CSV:
Что содержит архив:
Обратите внимание! При парсинге объявления собираются из результатов поисковой выдачи в таком виде, в котором они отображаются. Кроме основного текста и заголовка могут собираться уточнения, быстрые ссылки и другие расширения (если они есть в объявлении)
Данные по доменам на одном листе
При таком способе отображения отчета загружается один XLSX-файл с четырьмя листами. Даже если вы парсите 50 доменов, листов в файле все равно будет четыре. Какие это листы:
- «Слова и объявления». На этом листе собрана семантика по всем конкурентам и тексты объявлений. Данные указаны по каждому региону и поисковой системе. Если доменов много, работать с такой таблицей будет неудобно.
- «Слова». Собраны уникальные ключевики по всем доменам.
- «Исх. настройки». Указаны настройки парсинга.
Парсеры Вордстата
Для экономии времени при подборе ключевых слов часто пользуются специально предназначенными для этого автоматическими программами – парсерами, которые могут быть как платными, так и бесплатными.
Лучший платный парсер Wordstat – KeyCollector. Используют его в основном те, кто профессионально занимается составлением семантики. Бесплатным аналогом КейКоллектора является программа Словоеб. Функции его урезаны, но составлять небольшие ядра с его помощью вполне реально.
Магадан тоже достаточно популярный парсер Вордстат, который тоже можно бесплатно скачать. Подбирает и анализирует запросы, есть поддержка регионов, предназначен для парсинга фраз Яндекс Директа.
Под конец хочу отметить, что Вордстат дает только те данные, которыми располагает Яндекс. Поэтому например частотность в Гугле и других поисковиках может быть совсем другая.
Другие возможности сервиса
На всех вкладках Yandex Wordstat есть возможность выполнить сортировку по устройствам: «Десктопы», «Мобильные», «Только телефоны», «Только планшеты». Данный функционал будет полезен, например, при настройке рекламы мобильного приложения в Директе.
Возможность указания региона, в котором вы хотите посмотреть статистику:
С помощью Wordstat также можно посмотреть динамику изменения интереса к запросу на вкладке «История запросов» и количество запросов по регионам на вкладке «По регионам».
История запросов
Как уже говорилось, статистика на вкладке «По словам» отображается за последние 30 дней, поэтому для получения данных за более длительный период необходимо переключиться на вкладку «История запросов», где выводится количество показов по запросу за последние 2 года.
Данную вкладку можно использоваться для первичного анализа сезонности, определения «симптомов» накрутки и оценки динамики интереса к поисковым запросам.
По регионам
На вкладке «По регионам» можно оценить популярность запроса в регионе или городе относительно других, а также получить региональную популярность — долю, которую занимает регион по количеству показов результатов выдачи по данному слову. Другими словами, если популярность более 100%, это означает повышенный интерес к запросу. Чем интерес выше, тем больше процент. И наоборот.
Больше всего купить слона хотят в городе Калуга. Этому факту есть объяснение, попробуйте найти его и вы.
Информация с вкладки может быть использована при планировании контекстной рекламы для принятия решения о необходимости отдельных кампаний под определенный регион.
К сожалению, на этих вкладках не работают операторы Wordstat, поэтому посмотреть данные можно только по широкому типу соответствия.
Маркерные запросы
Маркерные запросы — это запросы, которые четко отвечают продвигаемой странице. Такие запросы обычно имеют значимую частотность ключевых слов по Wordstat и являются средне-частотными (СЧ), или «жирными» низкочастотниками (НЧ), и могут породить «хвост» запросов, например при добавлении слов «купить», «цена», «отзывы».
Примеры:
Платья
Красные платья
Красные платья в пол
Телевизоры
Телевизоры Samsung
Телевизоры Самсунг
LED телевизоры Samsung
Стиральные машины
Стиральные машины для дачи
Стиральные машины шириной 40 см
Другими словами, эти ключевые слова часто являются названием страниц/категорий/статей/карточек товара и прочих типов страниц, которые вообще можно продвигать в поисковых системах.
Часто задаваемые вопросы про маркеры:
Q: Могут ли для страницы быть несколько маркеров?
A: Да — конечно — это довольно частый случай.
Например, на одну страницу могут идти такие маркеры как:
Телевизоры Samsung
Телевизоры Samsung купить
Телевизоры Самсунг
Телевизоры Самсунг купить
Телевизоры самсунг цена
Все эти запросы четко отвечают одной странице
Так же на одну страницу могут идти два маркера-синонима, не связанных лингвистически:
Спецоджеда
Рабочая одежда
или
электроплита бош
электрическая плита bosch
Это вполне нормально и логично.
НЕ маркеры — облако запросов. Это все второстепенные запросы, которые уточняют маркерные запросы — т.е. по факту это маркеры + 1/2/3 слова или синонимы маркеров. Как правило запросы из облака — менее частотные и поэтому мы будем привязывать их к маркерам
Как найти маркерные запросы?
Вариант №1: можно получить поисковые запросы из Яндекс Метрики. Плюсы такого метода — что вы сразу будете знать релевантные URL для этих запросов.
Вариант №2: Берем названия категорий/услуг своего сайта и расширяем их логическими гипотезами:«Как, по каким запросам пользователи еще могут искать эту страницу моего сайта? Какие есть синонимы?»
NB!: Отличным подспорьем в определении маркеров является старый добрый Яндекс Wordstat, при всех его недостатках. Рекомендуем использовать браузерный плагин Yandex Wordstat Assistant от компании Semantica — очень удобный — выполняет роль своего рода «заметок на полях» — в него можно в один клик добавить интересующие слова.
Мы понимаем, что не у каждого оптимизатора/владельца бизнеса есть под рукой департамент разработки, который быстро сможет выгрузить для сайта связку URL — название категории/страницы.
Что такое связка URL-название категории/страницы?
Поэтому есть 3 варианта как получить связку URL — название категории/страницы:
Фактически маркеры для вашего сайта будут состоять из:
- Запросов, выгруженных из Яндекс Метрики
- Названий категорий/страниц, взятых с сайта
- Расширений названий категорий/страниц т.е. логических гипотез
Важно выполнить эту часть работы по подбору семантического ядра максимально тщательно т.к. если вы потеряете большую часть маркеров — вы потеряете большую часть семантического ядра
Часто задаваемые вопросы по подбору маркеров:
Q: У меня большой сайт и маркеров сотни или тысячи — как быть?!
Q: На сколько низкочастотное слово может быть маркером?
A: Здесь все зависит от тематики. В узких тематиках даже ключевые слова с частотностью 15 по кавычкам «» могут быть маркерными запросами. Главное правило — спросите себя — хотел бы мой пользователь видеть отдельную страницу под этот запрос (и связанные с ним?). Удобно ли ему будет пользоваться той структурой, что я создаю?
Q: Как мне держать маркеры в Excell, чтобы потом мне было удобно с ними работать?
A: Идеальный и единственно правильный вариант — всегда держать связку URL-маркер в Excel — так вы всегда сможете понимать какие маркеры идут на один URL, даже если ваш список перемешается.
В дальнейшем таким образом вы сможете фильтровать целые кластеры, которые идут на одну страницу — это может быть и 10 и 50 ключевых слов. Очень удобно.
Пример правильного оформления маркеров в Excel
Итак, после N времени работы мы собрали маркеры для всего сайта (или части сайта), что дальше?
Естественно, что маркеры, это далеко не полная семантика — теперь нам нужно собрать облако запросов — расширить наше семантическое ядро.
Обзор других функций программы
Помимо парсинга Вордстата, у Словоеба есть и другие функции.
Парсинг подсказок в Словоебе
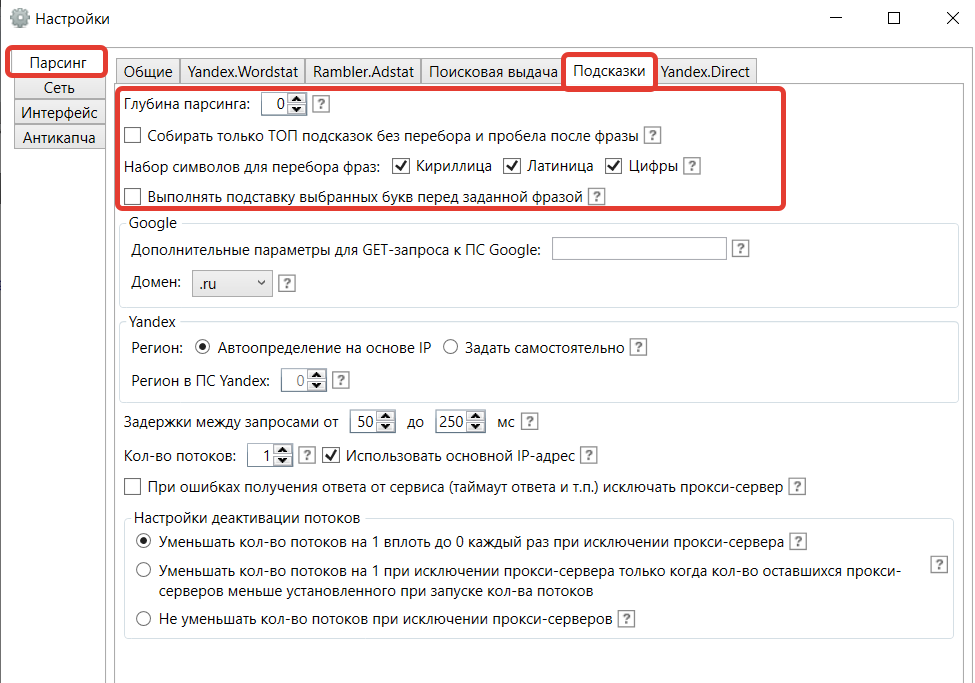
Для начала нужно проверить настройки подсказок и задать их под себя. Находятся они в разделе «Парсинг» во вкладке «Подсказки».
Настройки:
- Глубину парсинга лучше оставить 0 – при большем значении найденные подсказки будут парситься по второму кругу. Соберется много мусора.
- Чекбокс в пункте «Собирать только ТОП подсказок без перебора пробела после фразы» лучше оставить пустым. И выбрать все возможные символы для перебора, как на скриншоте ниже. Так, к заданной фразе соберуться все возможные подсказки.
- Если отметить «Выполнять подстановку выбранных групп перед заданной фразой», процесс затянется, а в итоге получится много мусора. Поэтому пользуйтесь функцией только тогда, когда без нее не обойтись.
- Остальные настройки можно оставить как есть, если не требуются подсказки из региональной выдачи.
Чтобы спарсить подсказки в программе, нажмите на соответствующий значок в панели инструментов и добавьте в открывшееся окно маркеры для парсинга.

Выберите, из каких поисковых систем нужны подсказки. Поставьте галочку, чтобы не добавлялись фразы, которые уже есть в других группах.
Теперь можно приступать к сбору подсказок.
Похожие фразы из Вордстата
В большинстве случаев нет смысла использовать эту функцию – для семантического ядра она может дать только мусор.

Но инструмент будет полезен, если нужны идеи первоначальных фраз для маркеров, которые в дальнейшем будут парситься.
Сезонность
Программа может проверить, является ли запрос сезонным. Словоеб анализирует историю запросов в Вордстате и выдает значение: да или нет.

Корректность словоформы
Функция проверяет, является ли словоформа корректной на основании поисковой выдачи.

Она пригодится, если в Словоеб добавлены ключевые слова из разных баз или выгрузки по конкурентам. С ее помощью можно избавиться от неправильных словоформ автоматически.
Опция для оценки конкурентности фразы в поисковых системах Яндекса и Гугла.

Позиции в Словоебе
Словоеб умеет определять, насколько страницы сайта релевантны запросам. За основу берутся данные поисковых систем Яндекса и Гугла. А также позиции сайта по этим ключам. Для проверки добавьте УРЛ сайта в строку меню.

Какие есть парсеры для Вордстата?
Обработка запросов в ВордСтат возможна только в ручном режиме. Это увеличивает время формирования семантического ядра (СЯ) даже для небольшого проекта. Для автоматизации разрабатывают программы и онлайн-сервисы – парсеры. Они собирают данные статистики Яндекс, используя технологию API и другие программные комплексы. В итоге пользователь может обрабатывать большой объем информации.
Цель работы парсеров – актуальная статистика ключевых фраз с возможностью углубленного анализа по параметрам. Это реализуется следующими способами:
- Программы. Сбор актуальной статистики WordStat, анализ по критериям пользователя. Условия использования – условно-бесплатное или платное.
- Онлайн-сервисы. По сравнению с программами обладают меньшим функционалом. Преимущества – экономия времени, не нужно устанавливать ПО.
- Специализированные программы. Разрабатываются для решения узконаправленных задач.
Выбор зависит от объема запросов и точности результатов. Онлайн-сервисы скачивают данные из Яндекса, чтобы уменьшить время формирования отчета. Поэтому информация не объективная. На это влияет частота обновления баз конкретного парсера.
Зачем нужен Вордстат?
Инструмент незаменим в таких случаях:
предстоит писать SEO-оптимизированные тексты, для которых важно определить состав ключевых фраз и частотность употребления;
необходимо составить структуру для новой страницы или для всего сайта;
нужно уточнить, какие слова в Вордстат вводят представители целевой аудитории, обращаясь к поисковой системе для решения проблемы, и как именно они формулируют мысли;
требуется выяснить, какие дополнительные интересы имеются у представителей целевой аудитории, чтобы грамотно составить ассортимент товаров и выкладывать максимально полезный контент.
Исключаем из парсинга отдельные группы товаров/услуг
Ассортимент товаров или услуг конкурентов не всегда совпадает с вашим. Например, конкуренты могут предлагать дополнительные услуги, которых нет у вас. Или охватывают более широкий ассортимент.
Соответственно, в рекламных кампаниях таких конкурентов будут ключевые слова и объявления, которые не подойдут вам.
Исключите нерелевантные ключи и объявления при парсинге, чтобы получить «чистые» результаты.
Перед запуском парсинга добавьте в поле «Минус-слова» перечень товаров или услуг, которые необходимо исключить из результатов. Также исключите сущности, которые не подходят для рекламы ваших товаров: «бесплатно», «подарок», «бу» и т. д.
Снимите галочку с пункта «Точное вхождение без учета морфологии».
В нашем примере система спарсит релевантные ключевые слова, исключив фразы типа «кухни на заказ», «офисная мебель недорого», «ремонт мебели» и т. д.
Заключение
Начинающему специалисту не обойтись без Wordstat Яндекса при сборе семантического ядра. Не стоит сразу автоматизировать этот процесс с помощью, например, программы Key Collector, следует разобраться с семантикой вручную.
Так, вы сможете понять, по каким словам пользователи ищут предложение, оценить эффективность синонимов, разных вариантов названия продукта, и разного написания. Подбор ключевых слов в Яндекс Вордстате позволяет изучить влияние семантики на продвижение: проанализировать сезонность бизнеса, популярность запросов в зависимости от региона показа и расширить список ключевых фраз.
Заключение
Аналитика поисковых запросов очень важна для продвижения сайтов. Причем не только информационных, но и коммерческих проектов, т. к. основная часть пользователей из СНГ любит искать информацию через Яндекс, использование Яндекс Вордстат – отличная возможность проверить частоту, а значит, и востребованность ключевой фразы.
Сервис полезен не только для интернет-маркетологов или СЕОшников, даже простым вебмастерам иногда стоит заходить и проверять состояние продвигаемых поисковых фраз. В курсе Василия Блинова “Как создать сайт” есть уроки, которые посвящены этому сервису.
Поэтому если вы хотите разобраться в анализе поисковых фраз и научиться продвигать информационные проекты под монетизацию, то я советую вам обязательно заглянуть. Помимо этого, там есть и другая полезная информация для вебмастеров.








