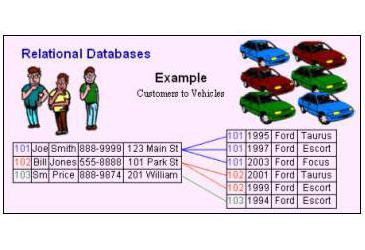
Реляционные субд: обзор базы данных, примеры
Содержание:
- Виды нереляционных баз данных
- Шаг 2. Избавляемся от дубликатов в столбцах
- [править] Основные понятия реляционной модели данных
- Ключи отношения в реляционной модели данных
- Применение реляционной модели данных
- Замкнутость реляционной алгебры
- Операция декартова произведения
- Операция выборки
- Проектирование реляционной базы данных. Преобразование модели в реляционную
- Хранилище пар «ключ — значение»Key/value data stores
- Реляционная модель данных: кем, когда и для чего создана
- Операция разности
- Процесс моделирования и составления основных элементов
- Основное понятие реляционной базы данных
Виды нереляционных баз данных
Базы NoSQL делятся на четыре основные категории (в зависимости от решаемых с их помощью задач).
Ключ-значение
Такую базу можно представить как огромную таблицу. В каждой её ячейке хранятся данные произвольного типа, а каждому значению присвоен уникальный ключ, по которому это значение можно найти.
Такая СУБД не поддерживает связи между объектами, выполняет лишь операции поиска значений по ключу, добавления и удаления записи.
Например:
| user1 | {Кузнецов В., отдел маркетинга} |
|---|---|
| user2 | {name:Лена, position:секретарь} |
| user3 | {ООО «Вектор»} |
| user4 | {Трофимова Таня, отд.2, дизайнер} |
| user5 | {Галина Николаевна, гл.бух.} |
| user6 | {65,84,236} |
Базы «ключ-значение» часто используют для кэширования данных и организации очередей.
Их достоинства: быстрый поиск и простое масштабирование.
Недостатки: нельзя производить операции со значениями. Например — сортировать их или анализировать.
Одна из самых популярных — Redis. Её используют Uber, Slack, Stack Overflow, сайты гостиниц и туристические, социальная сеть Twitter.
Документоориентированные СУБД
В таких данные хранятся в виде иерархических структур (документов) с произвольным набором полей и их значений. Документы объединяются в коллекции.
Если провести аналогию с реляционными СУБД, то коллекциям соответствуют таблицы, а документам — строки в них.
Например, фрагмент документа с информацией о фильмах:
Документоориентированные базы используют в системах управления содержимым (CMS) — для хранения каталогов и пользовательских профилей.
Одна из самых популярных — MongoDB (там можно создавать процедуры на JavaScript).
Колоночные
Эти базы отличаются от реляционных лишь способом хранения данных на накопителе.
Если реляционная база создаёт для каждой таблицы по файлу, то в колоночной отдельный файл создаётся для каждого столбца таблицы.
Например, если реляционная таблица выглядит так:
| name | color | property |
|---|---|---|
| волк | серый | зубастый |
| коза | белая | рогатая |
| капуста | зелёная |
То те же записи колоночной базы будут выглядеть примерно так:
Что это даёт? Представьте, что вам нужны только названия объектов, а их свойства вас не интересуют.
При выполнении запроса в реляционной таблице просматривается каждая запись и из неё выбираются нужные данные. В колоночной базе с диска будет считана только одна колонка с названиями. Это сокращает время выполнения запроса, причём намного.
Колоночные базы применяются в различных каталогах и архивах данных, работа с которыми основана на подобных выборках.
Одна из самых популярных СУБД такого типа — Apache Cassandra.
Графовые
В некоторых предметных областях данные удобно представлять в виде графов. Для их хранения лучше всего подходят графовые базы.
Вершины (или узлы графа) — это объекты (сущности), а рёбра графа — взаимосвязи между ними.
Шаг 2. Избавляемся от дубликатов в столбцах
Как было оговорено выше, столбцы “username” и “following_username” содержат дубликаты данных. Они возникли в результате того, что я хотел отобразить отношения между твиттами и пользователями. Давайте улучшим нашу структуру БД, разделив существующую таблицу на две: в одной будем хранить информацию, а в другой — отношения между записями.
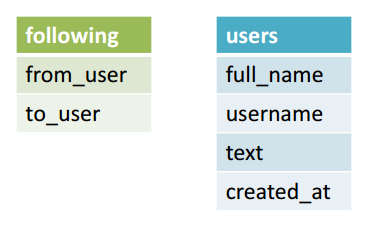
Поскольку @Brett_Englebert подписан на @RealSkipBayless, то в таблице “following” отобразим это следующим образом: имя @Brett_Englebert поместим в колонку “from_user”, а @RealSkipBayless в “to_user.” Давайте посмотрим, как будет выглядеть таблица “following” после разделения Таблицы 1:
Таблица 2. following
| from_user | to_user |
|---|---|
| _DreamLead | Scootmedia |
| _DreamLead | MetiersInternet |
| GunnarSvalander | klout |
| GunnarSvalander | zillow |
| GEsoftware | DayJobDoc |
| GEsoftware | byosko |
| adrianburch | CindyCrawford |
| adrianburch | Arjantim |
| AndyRyder | MichaelDell |
| AndyRyder | Yahoo |
| Brett_Englebert | RealSkipBayless |
| Brett_Englebert | stephenasmith |
| NimbusData | dellock6 |
| NimbusData | rohitkilam |
| SSWUGorg | drsql |
| SSWUGorg | steam_games |
Таблица 3. users
| full_name | username | text | created_at |
|---|---|---|---|
| Boris Hadjur | _DreamLead | What do you think about #emailing #campaigns #traffic in #USA? Is it a good market nowadays? do you have #databases? | Tue, 12 Feb 2013 08:43:09 +0000 |
| Gunnar Svalander | GunnarSvalander | Bill Gates Talks Databases, Free Software on Reddit http://t.co/ShX4hZlA #billgates #databases | Tue, 12 Feb 2013 07:31:06 +0000 |
| GE Software | GEsoftware | RT @KirkDBorne: Readings in #Databases: excellent reading list, many categories: http://t.co/S6RBUNxq via @rxin Fascinating. | Tue, 12 Feb 2013 07:30:24 +0000 |
| Adrian Burch | adrianburch | RT @tisakovich: @NimbusData at the @Barclays Big Data conference in San Francisco today, talking #virtualization, #databases, and #flash memory. | Tue, 12 Feb 2013 06:58:22 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/D3KOJIvF article about Madden 2013 using AI to prodict the super bowl #databases #bus311 | Tue, 12 Feb 2013 05:29:41 +0000 |
| Andy Ryder | AndyRyder5 | http://t.co/rBhBXjma an article about privacy settings and facebook #databases #bus311 | Tue, 12 Feb 2013 05:24:17 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 University of Minnesota’s NCFPD is creating #databases to prevent “food fraud.” http://t.co/0LsAbKqJ | Tue, 12 Feb 2013 01:49:19 +0000 |
| Brett Englebert | Brett_Englebert | #BUS311 companies might be protecting their production #databases, but what about their backup files? http://t.co/okJjV3Bm | Tue, 12 Feb 2013 01:31:52 +0000 |
| Nimbus Data Systems | NimbusData | @NimbusData CEO @tisakovich @BarclaysOnline Big Data conference in San Francisco today, talking #virtualization, #databases,& #flash memory | Mon, 11 Feb 2013 23:15:05 +0000 |
| SSWUG.ORG | SSWUGorg | Don’t forget to sign up for our FREE expo this Friday: #Databases, #BI, and #Sharepoint: What You Need to Know! http://t.co/Ijrqrz29 | Mon, 11 Feb 2013 22:15:37 +0000 |
Уже лучше. Теперь в таблице “users” (Таблица 3) у нас хранится только информация о твиттах, а в таблице following (Таблица 2) — зависимость пользователей.
Основатель теории реляционных баз данных, Эдгар Кодд, назвал бы этот процесс (удаления повторений из столбцов таблиц) приведением БД к первой нормальной форме.
[править] Основные понятия реляционной модели данных
Выделим следующие основные понятия реляционных баз данных:
- Тип данных — значения данных, хранимые в реляционной базе данных, являются типизированными.
- Домен определяется путем задания некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу этого типа данных.
- атрибут
- Кортежем tr, соответствующим заголовку Hr, называется множество упорядоченных триплетов вида <A, T, v>, по одному такому триплету для каждого атрибута в Hr.
- отношение r (Hr) называется конечное множество упорядоченных пар вида <A, T>, где A называется именем атрибута, а T обозначает имя некоторого базового типа или ранее определенного домена.
- первичный ключ переменной отношения является такое подмножество S множества атрибутов ее заголовка, что в любое время значение первичного ключа (составное, если в состав первичного ключа входит более одного атрибута) в любом кортеже тела отношения отличается от значения первичного ключа в любом другом кортеже тела этого отношения, а никакое собственное подмножество S этим свойством не обладает.
Ключи отношения в реляционной модели данных
Ключи отношения могут быть следующми:
- суперключ;
- потенциальный ключ;
- первичный ключ;
- внешний ключ;
- суррогатный ключ.
Ключ отношения — это подсхема исходной схемы отношения, состоящая из одного или
нескольких атрибутов, для которых декларируется условие уникальности значений в кортежах отношений.
При объявлении схемы базового отношения могут быть заданы объявления нескольких ключей.
Ключ отношения может быть простым или составным. Простой ключ – это ключ,
состоящий из одного и не более атрибута. Составной ключ -ключ, состоящий из двух и более атрибутов.
Суперключ — это атрибут или множество атрибутов, которое единственным
образом идентифицирует кортеж данного отношения. Он может включать дополнительные атрибуты. Суперключ
не обладает свойством неизбыточности.
Потенциальный ключ — это подмножество атрибутов отношения, удовлетворяющее требованиям
уникальности и неизбыточности. Он обладает следующими свойствами. Уникальность: в таблице нет двух разных
строк с одинаковыми значениями в нашем потенциальном ключе. Неизбыточность: нельзя убрать один из
столбцов из ключа, так, чтобы он не потерял уникальности. В отношении может быть больше одного
потенциального ключа.
Первичный ключ (primary key, PK) — это один из потенциальных ключей отношения,
выбранный в качестве основного ключа. Допустимо объявление одного и только одного первичного ключа.
Атрибуты первичного ключа не могут принимать значения Null.
Внешний ключ (foreign key, FK) — это ключ, объявленный в базовом отношении,
который при этом ссылается на первичный того же самого или какого-то другого базового отношения.
Суррогатный ключ — это служебный атрибут, добавленный к уже имеющимся информационным
атрибутам отношения. Предназначение суррогатного ключа — служить первичным ключом отношения. Значение
этого атрибута генерируется искусственно.
Пример 2. Есть база данных сети аптек. В ней есть таблица «Аптеки», в
которую занесены все аптеки сети, и есть таблица «Препараты». Кроме того, есть таблица «Наличие», в которую
заносятся данные о наличии препаратов в каждой аптеке. В таблице наличие есть поля: «Аптека» (в ней —
идентификаторы аптек), «Препарат» (в ней — идентификаторы препаратов), «Количество». Возникает проблема:
в случае поступления в аптеку некоторого количества препарата можно не заметить, что в той же аптеке тот
же препарат уже содержится в некотором количестве и сделать новую записись в таблице, в которой аптека и
препарат будут повторяться. Как на уровне ключей избежать этой проблемы?
Решение. Можно объявить первичным ключём таблицы «Наличие» составной ключ, состоящий
из идентификатора аптеки и идентификатора препарата. Тогда в таблице невозможно повторение в разных записях
сочетания аптеки и прапарата. Первичный ключ может быть не только простым, но и
составным.
Применение реляционной модели данных
Пример базы данных, содержащей сведения о подразделениях предприятия и работающих в них сотрудниках, применительно к реляционной модели будет иметь вид:
База данных о подразделениях и сотрудниках предприятия
Например, связь между отношениями ОТДЕЛ и СОТРУДНИК создается путем копирования первичного ключа «Номер_отдела» из первого отношения во второе. Таким образом:
- для того, чтобы получить список работников данного подразделения, необходимо:
- из таблицы ОТДЕЛ установить значение атрибута «Номер_отдела», соответствующее данному «Наименованию_отдела»
- выбрать из таблицы СОТРУДНИК все записи, значение атрибута «Номер_отдела» которых равно полученному на предыдущем шаге
- для того, чтобы узнать в каком отделе работает сотрудник, нужно выполнить обратную операцию:
- определяем «Номер_отдела» из таблицы СОТРУДНИК
- по полученному значению находим запись в таблице ОТДЕЛ
Атрибуты, представляющие собой копии ключей других отношений, называются внешними ключами.
Замкнутость реляционной алгебры
Реляционная алгебра представляет собой набор таких операций над отношениями, что результат каждой из операций также является отношением. Это свойство алгебры называется замкнутостью.
Операции над одним отношением называются унарными, над двумя отношениями — бинарными, над тремя — тернарными (таковые практически неизвестны).
Пример унарной операции — проекция, пример бинарной операции — объединение.
N-арную реляционную операцию f можно представить функцией, возвращающей отношение и имеющей n отношений в качестве аргументов:
- R=f(R1,R2,…,Rn){\displaystyle R=f(R_{1},R_{2},\dots ,R_{n})}
Поскольку реляционная алгебра является замкнутой, в качестве операндов в реляционные операции можно подставлять другие выражения реляционной алгебры (подходящие по типу):
- R=f(f1(R11,R12,…),f2(R21,R22,…),…){\displaystyle R=f(f_{1}(R_{11},R_{12},\dots ),f_{2}(R_{21},R_{22},\dots ),\dots )}
В реляционных выражениях можно использовать вложенные выражения сколь угодно сложной структуры.
Операция декартова произведения
Операция декартова произведения ()
определяет новое отношение R, которое является результатом конкатенации каждого кортежа
отношения R1 с каждым кортежем отношения R2.
Запрос SQL
SELECT * from R3, R4
Установим, что получится в результате выполнения этой операции
реляционной алгебры и соответствующего ей запроса SQL. Даны два отношения R3 и R4:
| R3 | R4 | ||||
| A1 | A2 | A3 | A4 | A5 | A6 |
| 3 | hh | yl | ms | 3 | hh |
| 4 | pp | a1 | sr | 4 | pp |
| 1 | rr | yl | ms |
В новом отношении должны присутствовать все атрибуты (столбцы) двух отношений.
Сначала первая строка отношения R3 сцепляется с каждой из двух строк отношения R4, затем вторая строка
отношения R3, затем третья. В результате должно получиться 3 Х 2 = 6 кортежей (строк). Получаем такое новое отношение:
| R | |||||
| A1 | A2 | A3 | A4 | A5 | A6 |
| 3 | hh | yl | ms | 3 | hh |
| 3 | hh | yl | ms | 4 | pp |
| 4 | pp | a1 | sr | 3 | hh |
| 4 | pp | a1 | sr | 4 | pp |
| 1 | rr | yl | ms | 3 | hh |
| 1 | rr | yl | ms | 4 | pp |
Операция выборки
О том, как работает оператор языка SQL SELECT, можно узнать на уроке
SQL SELECT — запрос на выборку из базы данных.
Операция выборки работает с одним отношением
и определяет результирующее отношение , которое
содержит только те кортежи (или строки, или записи), отношения ,
которые удовлетворяют заданному условию (предикату ).
Таким образом, операция выборки — унарная операция — и записывается следующим образом:
,
где — предикат (логическое условие).
Запрос SQL
SELECT * from R3 WHERE A3>’d0′
Теперь посмотрим, что получится в результате выполнения этой операции
реляционной алгебры и соответствующего ей запроса SQL. В таблице ниже дано одно отношение,
с которым работает эта операция.
| R3 | |||
| A1 | A2 | A3 | A4 |
| 3 | hh | yl | ms |
| 4 | pp | a1 | sr |
| 1 | rr | yl | ms |
Просматриваем столбец А3 и устанавливаем, что предикату A3>’d0′ удовлетворяют
записи в первой и третьей строках исходного отношения (так как номер буквы y в алфавите
больше номера буквы d). В результате получаем следующее новое отношение, в котором две строки:
| R | |||
| A1 | A2 | A3 | A4 |
| 3 | hh | yl | ms |
| 1 | rr | yl | ms |
Комбинировать всевозможные логические условия для выборок Вам поможет
материал «Булева алгебра (алгебра логики)».
А в материалах раздела «Программирование PHP/MySQL»
Вы найдёт немало примеров комбинаций различных логических условий для выборок из базы данных.
Проектирование реляционной базы данных. Преобразование модели в реляционную
Преобразование концептуальной модели данных в реляционную — важная часть проектирования БД. Процесс включает в себя:
— построение набора предварительных таблиц;
— указание РК;
— выполнение нормализации.
Из набора таблиц состоят наши объекты, а из полей таблиц — атрибуты объектов:
Итак, мы определились с таблицами, полями, РК и FK. Следует отметить, что в таблицах «Журнал покупок» и «Журнал поставок» РК составные, т. к. состоят из 2-х полей.
Что касается нормализации, то под ней понимают обратимый и пошаговый процесс, при котором исходная схема меняется другой схемой, в которой таблицы характеризуются более простой и логичной структурой. Это нужно по следующим причинам:
1. Устранение избыточности данных. Вспомним нашу таблицу:
Очевидно, что в поле «Темы» одни и те же названия встречаются регулярно. Для хранения таких данных нужны дополнительные ресурсы памяти. Кроме того, при дублировании данных можно допустить ошибку во время ввода значений атрибута, вследствие которой БД перейдёт в состояние несогласованности.
2. Устранение различных аномалий, связанных с обновлением, удалением, модификацией и пр. Пример аномалии модификации — чтобы поменять название темы, нам придётся смотреть все строки и менять название в каждой из них.
Нормализация бывает:
— 1-й нормальной формы (1НФ);
— 2НФ;
— 3НФ;
— НФБК (нормальной формы Бойса-Кодда);
— 4НФ;
— 5НФ.
Каждая форма накладывает определённые ограничения на данные разного уровня. В ходе нормализации база данных становится всё строже, подверженность аномалиям снижается.
Если говорить о реляционных базах данных, то минимум — это 1НФ. Однако в процессе проектирования специалисты по СУБД стремятся нормализовать базу хотя бы до уровня 3НФ, исключив тем самым избыточность данных и аномалии
Это важно, если мы стремимся получить качественный результат проектирования. Однако подробное описание нормализации данных выходит за рамки нашей статьи, поэтому давайте просто посмотрим, как будет выглядеть наша база на уровне 3НФ:
Итак, в процессе проектирования мы преобразовали концептуальную модель в реляционную. Следующий этап — реализация её в конкретной СУБД. Для этого потребуется как сама СУБД, так и знание языка SQL. Например, прекрасно подойдёт СУБД MySQL или какая-нибудь другая СУБД.
Хранилище пар «ключ — значение»Key/value data stores
Хранилище пар «ключ — значение» по сути представляет собой большую хэш-таблицу.A key/value store is essentially a large hash table. Каждое значение сопоставляется с уникальным ключом, и хранилище ключей использует этот ключ для хранения данных, применяя к нему некоторую функцию хэширования.You associate each data value with a unique key, and the key/value store uses this key to store the data by using an appropriate hashing function. Выбор функции хэширования должен обеспечить равномерное распределение хэшированных ключей по хранилищу данных.The hashing function is selected to provide an even distribution of hashed keys across the data storage.
Большинство хранилищ пар «ключ — значение» поддерживают только самые простые операции запроса, вставки и удаления.Most key/value stores only support simple query, insert, and delete operations. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком.To modify a value (either partially or completely), an application must overwrite the existing data for the entire value. В большинстве реализаций атомарной операцией считается чтение или запись одного значения.In most implementations, reading or writing a single value is an atomic operation. Запись больших значений занимает относительно долгое время.If the value is large, writing may take some time.
Приложение может хранить в наборе значений произвольные данные, но некоторые хранилища пар «ключ — значение» накладывают ограничения на максимальный размер значений.An application can store arbitrary data as a set of values, although some key/value stores impose limits on the maximum size of values. Программное обеспечение хранилища ничего не знает о значениях, которые в нем хранятся.The stored values are opaque to the storage system software. Все сведения о схеме поддерживаются и применяются на уровне приложения.Any schema information must be provided and interpreted by the application. Эти значения по существу являются большими двоичными объектами, которые хранилище извлекает и сохраняет по соответствующему ключу.Essentially, values are blobs and the key/value store simply retrieves or stores the value by key.
Хранилища пар «ключ — значение» рассчитаны на приложения, выполняющие простые операции поиска на основе значения ключа или диапазона ключей, но не очень подходят для систем, которым нужно запрашивать данные из нескольких таблиц хранилищ пар «ключ — значение», например присоединенные данные в нескольких таблицах.Key/value stores are highly optimized for applications performing simple lookups using the value of the key, or by a range of keys, but are less suitable for systems that need to query data across different tables of keys/values, such as joining data across multiple tables.
Кроме того, хранилища пар «ключ — значение» неудобны в сценариях, где могут выполняться запросы или фильтрация по значению, а не только по ключам.Key/value stores are also not optimized for scenarios where querying or filtering by non-key values is important, rather than performing lookups based only on keys. Например, с помощью реляционной базы данных можно найти запись, используя предложение WHERE для фильтрации неключевых столбцов, но в хранилищах «ключ-значение» обычно отсутствует возможность поиска в значениях, или, если они есть, требуется медленный Просмотр всех значений.For example, with a relational database, you can find a record by using a WHERE clause to filter the non-key columns, but key/values stores usually do not have this type of lookup capability for values, or if they do, it requires a slow scan of all values.
Одно хранилище пар «ключ — значение» очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.A single key/value store can be extremely scalable, as the data store can easily distribute data across multiple nodes on separate machines.
Соответствующие службы Azure:Relevant Azure services:
- API таблиц Azure Cosmos DBAzure Cosmos DB Table API
- Кэш Azure для RedisAzure Cache for Redis
- хранилище таблиц AzureAzure Table Storage
Реляционная модель данных: кем, когда и для чего создана
Реляционная модель данных — созданная Эдгаром Коддом логическая модель данных, описывающая:
- структуры данных в виде (изменяющихся во времени) наборов отношений;
- теоретико-множественные операции над данными: объединение, пересечение разность и декартово произведение;
- специальные реляционные операции: селекция, проекция, соединение и деление;
- специальные правила, обеспечивающие целостность данных.
Эдгар Франк «Тед» Кодд — (23 августа 1923 —18 апреля 2003) — британский учёный, работы которого заложили основы
теории реляционных баз данных. Работая в компании IBM, он создал реляционную модель данных. В 1970 издал работу «A Relational Model
of Data for Large Shared Data Banks», которая считается первой работой по реляционной модели данных.
Реляционная модель данных — это способ рассмотрения данных, то есть предписание для способа представления данных
(посредством таблиц) и для способа работы с таким представлением (посредством операторов). Она связана с тремя аспектами
данных: структурой (объекты), целостностью и обработкой данных (операторы).
В 2002 журнал Forbes поместил реляционную модель данных в список важнейших инноваций
последних 85 лет.
Цели создания реляционной модели данных:
- обеспечение более высокой степени независимости от данных;
- создание прочного фундамента для решения семантических вопросов и проблем непротиворечивости и избыточности данных;
- засширение языков управления данными за счёт включения операций над множествами.
Операция разности
Разность двух отношений R1 и R2 () состоит из кортежей (или записей, или строк),
которые имеются в отношении R1, но отсутствуют в отношении R2. Отношения R1 и R2 должны быть
совместимы по объединению. Операция разности реляционной алгебры идентична операции разности множеств,
которая также описана в материале «Множества и операции над множествами».
Запрос SQL
SELECT A1, A2, A3 from R2 EXCEPTSELECT A1, A2, A3 from R1
Установим, что получится в результате выполнения этой операции
реляционной алгебры и соответствующего ей запроса SQL. Вновь даны два отношения R1 и R2:
| R1 | R2 | ||||
| A1 | A2 | A3 | A1 | A2 | A3 |
| Z7 | aa | w11 | X8 | pp | k21 |
| B7 | hh | h15 | Q2 | ee | h15 |
| X8 | pp | w11 | X8 | pp | w11 |
Из отношения R2 исключаем строку, которая есть также в отношении R2 —
третью — и получаем новое отношение:
| R | ||
| A1 | A2 | A3 |
| X8 | pp | w11 |
| Q2 | ee | h15 |
В некоторых диалектах SQL отсутствует ключевое слово EXCEPT. Поэтому, например, в
MySQL и других, операция пересечения множеств может реализована с применением предиката NOT EXISTS.
Процесс моделирования и составления основных элементов
Для того чтобы создать собственную СУБД, следует воспользоваться одним из инструментов моделирования, продумать, с какой информацией вам необходимо работать, спроектировать таблицы и реляционные одно- и множественные связи между данными, заполнить ячейки сущностей и установить первичный, внешние ключи.
Моделирование таблиц и проектирование реляционных баз данных производится посредством бесплатных инструментов, таких как Workbench, PhpMyAdmin, Case Studio, dbForge Studio. После детальной проектировки следует сохранить графически готовую реляционную модель и перевести ее в готовый SQL-код. На этом этапе можно начинать работу с сортировкой данных, их обработку и систематизацию.
Основное понятие реляционной базы данных
Такая модель была разработана в 1970-х годах доктором науки Эдгаром Коддом. Она представляет собой логически структурированную таблицу с полями, описывающую данные, их отношения между собой, операции, произведенные над ними, а главное — правила, которые гарантируют их целостность. Почему модель называется реляционной? В ее основе лежат отношения (от лат. relatio) между данными. Существует множество определений этого типа базы данных. Реляционные таблицы с информацией гораздо проще систематизировать и придать обработке, нежели в сетевой или иерархической модели. Как же это сделать? Достаточно знать особенности, структуру модели и свойства реляционных таблиц.