Модели баз данных — шпаргалка для начинающих
Содержание:
- Чем хороши и плохи нереляционные базы данных: главные достоинства и недостатки
- Реляционная база данных
- Стратегии работы с внешней памятью
- Стратегии работы с внешней памятью
- Термины и типы
- Установка ПО для работы
- В чём преимущества
- Состав СУБД
- Как это работает
- Сетевая модель данных
- MS Access: где скачать дополнительные шаблоны?
- Настройка и работа в Management Studio
- Виды СУБД
- Установка и настройка MS SQL Server Management Studio
- Проектирование баз данных
- Примеры реляционных СУБД
- Другие модели баз данных (ООСУБД)
- Какие бывают NoSQL-СУБД: основные типы нереляционных баз данных
Чем хороши и плохи нереляционные базы данных: главные достоинства и недостатки
По сравнению с классическими SQL-базами, нереляционные СУБД обладают следующими преимуществами:
- линейная масштабируемость – добавление новых узлов в кластер увеличивает общую производительность системы ;
- гибкость, позволяющая оперировать полуструктирированные данные, реализуя, в. т.ч. полнотекстовый поиск по базе ;
- возможность работать с разными представлениями информации, в т.ч. без задания схемы данных ;
- высокая доступность за счет репликации данных и других механизмов отказоустойчивости, в частности, шаринга – автоматического разделения данных по разным узлам сети, когда каждый сервер кластера отвечает только за определенный набор информации, обрабатывая запросы на его чтение и запись. Это увеличивает скорость обработки данных и пропускную способность приложения .
- производительность за счет оптимизации для конкретных видов моделей данных (документной, графовой, колоночной или «ключ‑значение») и шаблонов доступа ;
- широкие функциональные возможности – собственные SQL-подобные языки запросов, RESTful-интерфейсы, API и сложные типы данных, например, map, list и struct, позволяющие обрабатывать сразу множество значений .
Обратной стороной вышеуказанных достоинств являются следующие недостатки:
- ограниченная емкость встроенного языка запросов . Например, HBase предоставляет всего 4 функции работы с данными (Put, Get, Scan, Delete), в Cassandra отсутствуют операции Insert и Join, несмотря на наличие SQL-подобного языка запросов. Для решения этой проблемы используются сторонние средства трансляции классических SQL-выражений в исполнительный код для конкретной нереляционной базы. Например, Apache Phoenix для HBase или универсальный Drill.
- сложности в поддержке всех ACID-требований к транзакциям (атомарность, консистентность, изоляция, долговечность) из-за того, что NoSQL-СУБД вместо CAP-модели (согласованность, доступность, устойчивость к разделению) скорее соответствуют модели BASE (базовая доступность, гибкое состояние и итоговая согласованность) . Впрочем, некоторые нереляционные СУБД пытаются обойти это ограничение с помощью настраиваемых уровней согласованности, о чем мы рассказывали на примере Cassandra. Аналогичным образом Riak позволяет настраивать требуемые характеристики доступности-согласованности даже для отдельных запросов за счет задания количества узлов, необходимых для подтверждения успешного завершения транзакции . Подробнее о CAP-и BASE-моделях мы расскажем в отдельной статье.
- сильная привязка приложения к конкретной СУБД из-за специфики внутреннего языка запросов и гибкой модели данных, ориентированной на конкретный случай ;
- недостаток специалистов по NoSQL-базам по сравнению с реляционными аналогами .
Подводя итог описанию основных аспектов нереляционных СУБД, стоит отметить некоторую некорректность запроса «NoSQL vs SQL» в связи с разными архитектурными подходами и прикладными задачами, на которые ориентированы эти ИТ-средства. Традиционные SQL-базы отлично справляются с обработкой строго типизированной информации не слишком большого объема. Например, локальная ERP-система или облачная CRM. Однако, в случае обработки большого объема полуструктурированных и неструктурированных данных, т.е. Big Data, в распределенной системе следует выбирать из множества NoSQL-хранилищ, учитывая специфику самой задачи. В частности, для самостоятельных решений интернета вещей (Internet of Things), в т.ч. промышленного, отлично подходит Cassandra, о чем мы рассказывали здесь
А в случае многоуровневой ИТ-инфраструктуры на базе Apache Hadoop стоит обратить внимание на HBase, которая позволяет оперативно, практически в режиме реального времени, работать с данными, хранящимися в HDFS
Нереляционные СУБД находят больше областей приложений, чем традиционные SQL-решения
Источники
- https://ru.wikipedia.org/wiki/NoSQL
- https://aws.amazon.com/ru/nosql/
- https://ru.bmstu.wiki/NoSQL
- https://tproger.ru/translations/types-of-nosql-db/
- https://habr.com/ru/sandbox/113232/
Реляционная база данных
Под данным типом баз данных понимается их представление в рамках двумерной таблицы. Она имеет несколько столбцов, в которых устанавливаются такие параметры, как, например, тип вводимых данных (текст, число, дата и др.).
Таблица здесь является способом хранения введённых в неё данных и способна реагировать на любые обращения со стороны СУБД. Главная проблема в работе с реляционными базами данных состоит в их правильном проектировании.
Во время проектирования базы данных следует учесть следующие два фактора:
- база данных должна быть компактной и не содержать избыточных компонентов;
- обработка базы данных должны происходить просто.
Проблема в том, что эти факторы друг другу противоречат. А ведь проектирование — важнейший момент при составлении базы данных и дальнейшей работе с ней. Заниматься им рекомендуется администратору сервера, обладающему определённым опытом.
В крупных проектах задействовано множество таблиц, которых может быть более сотни. При этом обойтись без них невозможно, если человек имеет дело с важным и сложным проектом.
Перед составлением таблицы следует составить диаграмму или схему, в которой содержится информация о видах хранимой информации, а также о типе данных, который лучше всего подойдёт для таких целей.
Стратегии работы с внешней памятью
- СУБД с непосредственной записью
В таких СУБД все изменённые блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции. Такая стратегия используется только при высокой эффективности внешней памяти.
- СУБД с отложенной записью
В таких СУБД изменения аккумулируются в буферах внешней памяти до наступления любого из следующих событий:
- Контрольная точка.
- Нехватка пространства во внешней памяти, отведенного под журнал. СУБД создаёт контрольную точку и начинает писать журнал сначала, затирая предыдущую информацию.
- Останов. СУБД ждёт, когда всё содержимое всех буферов внешней памяти будет перенесено во внешнюю память, после чего делает отметки, что останов базы данных выполнен корректно.
- Нехватка оперативной памяти для буферов внешней памяти.
Такая стратегия позволяет избежать частого обмена с внешней памятью и значительно увеличить эффективность работы СУБД.
Стратегии работы с внешней памятью
- СУБД с непосредственной записью
В таких СУБД все изменённые блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции. Такая стратегия используется только при высокой эффективности внешней памяти.
- СУБД с отложенной записью
В таких СУБД изменения аккумулируются в буферах внешней памяти до наступления любого из следующих событий:
- Контрольная точка.
- Нехватка пространства во внешней памяти, отведенного под журнал. СУБД создаёт контрольную точку и начинает писать журнал сначала, затирая предыдущую информацию.
- Останов. СУБД ждёт, когда всё содержимое всех буферов внешней памяти будет перенесено во внешнюю память, после чего делает отметки, что останов базы данных выполнен корректно.
- Нехватка оперативной памяти для буферов внешней памяти.
Такая стратегия позволяет избежать частого обмена с внешней памятью и значительно увеличить эффективность работы СУБД.
Термины и типы
Реляционные СУБД включают таблицы, содержащие строки и столбцы. При создании РБД определяют область возможных значений в столбце данных и дополнительные ограничения, которые могут применяться к этому значению. Например, домен клиентов может разрешить до 10 возможных имен, но в одной таблице можно ограничить его указанием только трех из этих имен клиентов. Два ограничения касаются целостности данных, а также первичного и внешнего ключей. Целостность объекта гарантирует, что первичный ключ уникальный и что значение не равно нулю. Ссылочная целостность требует, чтобы каждое значение в столбце внешнего ключа было найдено в первичном ключе таблицы, из которой оно произошло.
Существует ряд категорий БД: от простых плоских файлов, не относящихся к NoSQL, до более новых графовых, которые считаются даже более реляционными, чем стандартные. База данных плоских файлов состоит из одной таблицы, которая не имеет взаимосвязи, обычно это текстовые файлы. Она позволяет пользователям указывать в реляционных СУБД атрибуты данных, такие как столбцы и типы.
Установка ПО для работы
В данном разделе рассказывается как установить и настроить SQL Server на примере SQL Server 2016 Enterprise – самой новой версии.
Для начала скачайте установочный пакет SQL Server 2016 Enterprise с официальной страницы: https://www.microsoft.com/en-us/sql-server/sql-server-editions-express. Версия, которую вы скачали будет работать .
Вместо нее можно использовать SQL Server 2016 Developer Edition, если у вас есть подписка MSDN. Станица для скачивания: https://www.microsoft.com/en-us/sql-server/sql-server-editions-developers.
Прежде чем запускать скаченный установщик, создайте учетную запись. Она потребуется чтобы авторизовываться вас на сервере с клиентского компьютера. Поскольку у вас это один и тот же компьютер, то авторизовываться будет SQL Server через Management Studio, его мы скачаем позже.
Создание учетной записи
Выполните следующие инструкции чтобы создать учетную запись в Windows. Способ работает во всех ОС этого семейства начиная с 2000 и заканчивая 10.
Инструкции:
- Кликните правой кнопкой мышки по значку «Мой компьютер» на рабочем столе и выберите из списка пункт «Управление». Откроется оснастка «Управление компьютером».
- В окне оснастке выберите пункт меню «локальные пользователи», затем выделите пункт «пользователи». Окно приобретёт вот такой вид:
- Кликните правой кнопкой мыши по пустому пространству папки или по названию папки и выберите пункт «новый пользователь». Откроется такое окно:
- Придумайте имя пользователя и пароль заполните их в формы и нажмите кнопку создать. Рекомендуем использовать латинские символы.
Установка SQL Server
- Запустите скачанный ранее пакет установки. Установщик проверит подходит ли ваш компьютер по производительности и есть ли на нем все необходимое для установки программное обеспечение. Если последнего не окажется, он его скачает. После этого откроется SQL Server Installation Server:
- Выберите пункт «Установка».
- После изменения экраны кликните на пункте «Новая установка изолированного экземпляра SQL Server». Запустится установка и установщик попытается обновиться до последней версии. Щелкните кнопку «Далее», чтобы перейти к следующему шагу:
- На этапе «правил установки» проследите чтобы в окне не было красных крестиков. Если они появились, то щелкайте по выделенным строкам предупреждений и следуйте инструкциям по устранениям. Затем, щелкните кнопку «Далее». Окно установки снова изменится:
- В появившемся окне выберите «Выполнить новую установку SQL Server 2016» и нажмите «Далее». Откроется окно регистрации продукта:
- Введите лицензионный ключ продукта, если он у вас есть. Либо выберите Evaluation для активации 180 дневной копии.
- В следующем окне прочтите лицензионное соглашение, и примите его, установив флажок в поле «Я принимаю…». И нажмите «Далее»
- Откроется окно компонентов. Выберите пункты, установив галочки напротив:
• Службы ядра СУБД;
• Соединение с клиентскими средствами;
• Компоненты документации.
Нажмите «Далее» - В следующем окне выберите «экземпляр по умолчанию» если уже есть установленная копия SQL Server или именованный экземпляр, если устанавливаете первый раз. Введите в поле имя Экземпляра и нажмите «Далее».
- В следующем окне проверьте, хватает ли места на диске. Если нет, освободите его и нажмите «Далее».
- На этапе «Настройка Ядра СУБД» убедитесь, что выбрана строка «Проверка подлинности Windows». Если нет, выберите его. Затем добавьте в поле внизу пользователя, которого создавали перед установкой, либо добавьте текущего с помощью соответствующей кнопки Нажмите «Далее»
- На следующем окне перепроверьте все настройки установки и нажмите «далее»
- Понаблюдайте за установкой и нажмите «Закрыть», когда появится сообщение о завершении установки.
В чём преимущества
Базы данных и их системы управления заточены на работу с большим объёмом данных и от лица большого числа пользователей. Сейчас вы поймёте.
Скорость — ещё одно преимущество базы данных. База данных устроена так, что она легко и быстро находит, записывает, переписывает и снова находит данные. Всё потому, что СУБД всегда знает, что где лежит и по какому критерию искать. Там не будет случайных данных в случайном месте.
Скорость важна ещё и потому, что СУБД обычно обслуживает сразу много потоков: одновременно ей могут пользоваться десятки и сотни тысяч человек, поэтому ей некогда копаться. В хорошо сделанных БД всё молниеносно.
Сложность. Базы данных нужны в числе прочего для хранения сложно структурированных данных. Мы привыкли думать, что база данных — это такая таблица, где есть строки и столбцы. Но база данных при правильной организации может намного больше:
- Связывать одну единицу данных с множеством других. Например, если один человек совершил много заказов со множеством товаров внутри каждого, база данных способна хранить и обрабатывать такие связи.
- База может хранить дерево данных — вроде того, о котором мы писали недавно. Попробуй в реальной жизни похранить дерево!
- В базах могут жить ссылки на другие фрагменты и отделы базы.
Базу можно представить как таблицу, но лишь в самом упрощённом виде. Для более сложных задач базу можно представить как очень сложное дерево, или огромный склад упорядоченных коробок, или даже как огромный завод по фасовке данных.
Состав СУБД
Обычно современная СУБД содержит следующие компоненты:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию,
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода,
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД
- сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы
Как это работает
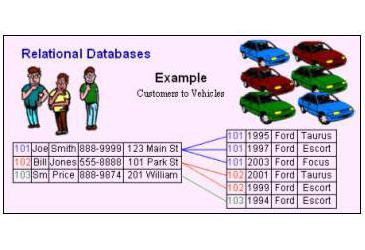
Возьмём простой пример реляционной базы данных (можно упрощённо сказать, что это база данных в виде таблицы).
Каждая запись в реляционной базе данных раскладывается в одну или несколько ячеек. Например, запись в телефонной книге может выглядеть так:
В нашем примере у базы есть поля — Имя, Фамилия, Телефон и Фото, в которых могут храниться данные. Одна строчка — одна запись с данными.
Если пользователю нужно будет найти телефон Михаила Максимова по фамилии, происходит следующее:
Запрос от пользователя: Выдай мне из базы «Контакты» все записи, где поле «Фамилия» равно «Максимов»Ответ от базы данных: ЛОЛ КЕК Ты кто такойЗапрос пользователя: Я хозяин этой базы Админ Админыч, пароль •••••. Выдай мне из базы «Контакты» все записи, где поле «Фамилия» равно «Максимов»Ответ от базы данных: Найдена одна запись:
Сетевая модель данных
Стандарт
сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference
of Data System Languages), которая определила базовые понятия модели и формальный
язык описания.
Базовыми
объектами модели являются:
- элемент данных;
- агрегат данных;
- запись;
- набор данных,
Элемент данных
—
то же, что и в иерархической модели, то есть минимальная информационная
единица, доступная пользователю с использованием СУБД.
Агрегат данных
—
соответствует следующему уровню обобщения в модели. В модели определены
агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа.
Агрегат данных
имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа
вектор соответствует линейному набору элементов данных. Например, агрегат Адрес
может быть представлен следующим образом:
|
Адрес |
|||
|
Город |
Улица |
дом |
квартира |
Агрегат типа
повторяющаяся группа соответствует совокупности векторов данных. Например, агрегат
Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
|
Зарплата |
|
|
Месяц |
Сумма |
Записью называется
совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов
реального мира. Понятие записи соответствует понятию «сегмент» в
иерархической модели. Для записи, так же как и для сегмента, вводятся понятия
типа записи и экземпляра записи.
Следующим
базовым понятием в сетевой модели является понятие «Набор».
Набор
—
это двухуровневый граф, связывающий отношением «один-ко-многим» два типа записи.
Набор фактически
отражает иерархическую связь между двумя типами записей. Родительский тип записи
в данном наборе называется владельцем набора, а дочерний тип записи — членом
того же набора.
Для любых
двух типов записей может быть задано любое количество наборов, которые их связывают.
Фактически наличие подобных возможностей позволяет промоделировать отношение
«многие-ко-многим» между двумя объектами реального мира, что выгодно
отличает сетевую модель от иерархической. В рамках набора возможен последовательный
просмотр экземпляров членов набора, связанных с одним экземпляром владельца
набора.
Между двумя
типами записей может быть определено любое количество наборов: например, можно
построить два взаимосвязанных набора. Существенным ограничением набора является
то, что один и тот же тип записи не может быть одновременно владельцем и членом
набора.
В качестве
примера рассмотрим таблицу, на основе которой организуем два набора и определим
связь между ними:
|
Преподаватель |
Группа |
День недели |
№ пары |
Аудитория |
Дисциплина |
||
|
Иванов |
4306 |
Понедельник |
1 |
22-13 |
КИД |
||
|
Иванов |
4307 |
Понедельник |
2 |
22-13 |
КИД |
||
|
Карпова |
4307 |
Вторник |
2 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
4309 |
Вторник |
4 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
84305 |
Вторник |
1 |
22-14 |
БД |
||
|
Смирнов |
4306 |
Вторник |
3 |
23-07 |
ГВП |
||
|
Смирнов |
4309 |
Вторник |
4 |
23-07 |
ГВП |
||
Экземпляров
набора Ведет занятия будет 3 (по числу преподавателей), экземпляром набора Занимается
у будет 4 (по числу групп). На рис. 3.6 представлены взаимосвязи экземпляров
данных наборов.
Рис.
3.6. Пример взаимосвязи экземпляров двух наборов
Среди всех
наборов выделяют специальный тип набора, называемый «Сингулярным набором»,
владельцем которого формально определена вся система. Сингулярный набор изображается
в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора,
но у которой не определен тип записи «Владелец набора». Например,
сингулярный набор М.
Сингулярные
наборы позволяют обеспечить доступ к экземплярам отдельных типов данных, поэтому
если в задаче алгоритм обработки информации предполагает обеспечение произвольного
доступа к некоторому типу записи, то для поддержки этой возможности необходимо
ввести соответствующий сингулярный набор.
В общем случае
сетевая база данных представляет совокупность взаимосвязанных наборов, которые
образуют на концептуальном уровне некоторый граф.
MS Access: где скачать дополнительные шаблоны?
Если вы не нашли подходящий шаблон среди предустановленных, то можете попробовать скачать шаблоны для Access из Интернета. К сожалению, количество загрузочных порталов, предоставляющих такие шаблоны, невелико, особенно в Рунете.
-
Для тех, кто владеет языками, существует сайт, Microsoft Templates. Он предлагает хорошую коллекцию бесплатных англоязычных шаблонов для любых продуктов Office, включая Access. Сайт содержит качественную подборку баз данных Access, разбитых по категориям — бизнес, нон-профит, для использования в образовании и так далее. Помимо этого, на сайте доступны шаблоны для Word, Excel, PowerPoint и других программ из офисного пакета MS.
- Существует огромная англоязычная коллекция шаблонов для Microsoft Access — Access Templates. Сайт предлагает солидное количество шаблонов баз данных Access для самых различных отраслей, от образования и медицины до бухучета и программирования. Шаблоны сорируются по версиям Access, дате, популярности. Однако, для полноценного скачивания требуется платная регистрация, которая стоит $88 и достаточно неудобна для России, так как работает через PayPal. В шаблонах, скачанных бесплатно, будут заблокированы таблицы (впрочем, разблокировка — вопрос умения).
- На русском языке существует неплохой проект Access Help. Несмотря на коммерческую направленность проекта, его создатели свободно выкладывают примеры созданных ими баз в Интернет, чтобы их мог использовать любой желающий. Для скачивания доступны готовые базы данных Access для самых разных организаций, особенно для бизнеса.
- Как создать календарь в MS Access
- Как обновить записи в формах MS Access
- Как задать первичный ключ базы данных Access
Фото: авторские, pixabay.com
Настройка и работа в Management Studio
- Найдите Management Studio в меню «ПУСК» и запустите.
- В открывшемся окне соединения с сервером выберите:
В поле тип сервиса – Ядро СУБД
В поле имя сервера – имя сервера, которое вы указали при установке
Проверка подлинности – Проверка подлинности Windows - Нажмите кнопку «соединить».
Management Studio подключится к SQL Server и откроется основное окно программы:
Настоятельно рекомендуем изучить элемент программы под названием обозреватель объектов. Он позволяет работать с всеми структурными элементами баз данных на сервере через интерфейс похожий на проводник Windows.
Создать новый запрос можно если кликнуть на кнопке «Создать запрос». Запрос будет создан для текущей таблицы, которая указана в выпадающем списке сверху, в данный момент master.
Если кликнуть по кнопке «создать запрос» несколько раз, то откроется несколько вкладок, как на скрине. Для каждого из них можно поменять текущую таблицу с помощью выпадающего списка.
Под полем редактора запросов располагается поле результатов. Там будут показываться результаты выполнения запроса:
Вот и все. Остальному можно научиться самостоятельно в процессе работы.
Виды СУБД
Базы данных различаются между собой тем, как внутри них связаны данные. Соответственно различаются и СУБД, которые эти БД поддерживают. Внутренние связи данных внутри БД называются моделями данных.
По поддержке баз данных различных моделей данных СУБД различаются на:
- Иерархические;
- Сетевые;
- Реляционные;
- Объектно-ориентированные;
- Объектно-реляционные.
Иерархические БД – это деревья данных, где каждый вышерасположенный объект имеет в подчинении несколько нижерасположенных. Доступ к данным осуществляется посредством движения по объектам сверху-вниз.
Сетевые отличаются от иерархических тем. Что каждый потомок в них может иметь несколько предков (множественное наследование).
Реляционные – безусловный лидер среди СУБД (93% всего рынка). Основаны на поддержке реляционных БД, то есть наборов таблиц и их отношений с возможность изменения обеих.
Объектно-ориентированные (ООСУБД) управляют абстрактными объектами, которые наделены свойствами и наделены методами для выполнения действий.
Объектно-реляционные (ОРСУБД) – реляционные СУБД, поддерживающие обьекты свойства и методы из объектно-ориентированной СУБД.
По способу доступа к БД:
- Файл серверные.
- Клиент-серверные;
- Встраиваемые.
В файл серверных базы данных располагаются на сервере, а СУБД на клиенте. В клиент – серверных базы данных и СУБД располагаются на сервере. Встраиваемые – мини СУБД, обычно встроенные внутри приложения.
По степени распределённой данных:
- Локальные: клиент и сервер – один компьютер;
- Распределенные – клиент и сервер разные компьютеры.
Установка и настройка MS SQL Server Management Studio
После того, как мы настроили сервер. Нужно настроить клиент. MS SQL Server Management Studio предоставляет удобный визуальный интерфейс для клиента и позволяет удобно разрабатывать и отправлять серверу запросы.
Установка его не сложнее плеера, поэтому останавливаться на этом не будем. Скачайте его с официального сайта Microsoft по одной из ссылок ниже.
- Скачать SQL Server Management Studio (16.5.1) https://download.microsoft.com/download/3/1/D/31D734E0-BFE8-4C33-A9DE-2392808ADEE6/SSMS-Setup-RUS.exe
- Скачать SQL Server Management Studio (17.0, версия-кандидат https://download.microsoft.com/download/B/2/3/B234198E-747D-4F89-9008-F39A7E4702D3/SSMS-Setup-RUS.exe
И установите. Программа сама определит, где у вас сервер. Просто следуйте инструкциям.
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
Примеры реляционных СУБД
SQLite — это популярная БД SQL с открытым исходным кодом. ПО может хранить всю БД в одном файле. Самым значительным преимуществом, которое она обеспечивает, является то, что все данные могут храниться локально без подключения к серверу. SQLite стала популярной для БД в мобильных телефонах, КПК, MP3-плеерах, телевизионных приставках и других электронных гаджетах.
MySQL — еще одна популярная реляционная модель СУБД SQL с открытым исходным кодом. Обычно она применяется в веб-приложениях и часто доступна с помощью PHP. Главные преимущества ее — простота использования, ценовая доступность, надежность. Некоторые из недостатков проявляются в том, что при масштабировании она страдает от низкой производительности, разработка с применением открытого исходного кода отстает с тех пор, как Oracle установил контроль над MySQL и не включает в себя некоторые расширенные функции.
PostgreSQL — это реляционная модель данных СУБД SQL с использованием открытого исходного кода, которая не контролируется какой-либо корпорацией. Обычно ее используют для разработки веб-приложений. PostgreSQL — простая, надежная и бюджетная программа с большим сообществом разработчиков. Имеет дополнительные функции в виде поддержки внешнего ключа, не требуя сложной настройки. Главный ее недостаток — она работает медленнее, чем иные БД, такие как MySQL. Она также менее популярна, чем MySQL, что затрудняет доступ хостов или поставщиков услуг, которые предлагают управляемые экземпляры PostgreSQL.
Другие модели баз данных (ООСУБД)
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Данная публикация является переводом статьи «Types of Database Models | Database Management System» , подготовленная редакцией проекта.
Какие бывают NoSQL-СУБД: основные типы нереляционных баз данных
Все NoSQL решения принято делить на 4 типа:
- Ключ-значение (Key-value) – наиболее простой вариант хранилища данных, использующий ключ для доступа к значению в рамках большой хэш-таблицы . Такие СУБД применяются для хранения изображений, создания специализированных файловых систем, в качестве кэшей для объектов, а также в масштабируемых Big Data системах, включая игровые и рекламные приложения, а также проекты интернета вещей (Internet of Things, IoT), в т.ч. индустриального (Industrial IoT, IIoT). Наиболее известными представителями нереляционных СУБД типа key-value считаются Oracle NoSQL Database, Berkeley DB, MemcacheDB, Redis, Riak, Amazon DynamoDB, которые поддерживают высокую разделяемость, обеспечивая беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов БД .
- Документно-ориентированное хранилище, в котором данные, представленные парами ключ-значение, сжимаются в виде полуструктурированного документа из тегированных элементов, подобно JSON, XML, BSON и другим подобным форматам . Такая модель хорошо подходит для каталогов, пользовательские профилей и систем управления контентом, где каждый документ уникален и изменяется со временем . Поэтому чаще всего документные NoSQL-СУБД используются в CMS-системах, издательском деле и документальном поиске. Самые яркие примеры документно-ориентированных нереляционных баз данных – это CouchDB, Couchbase, MongoDB, eXist, Berkeley DB XML .
- Колоночное хранилище, которое хранит информацию в виде разреженной матрицы, строки и столбцы которой используются как ключи. В мире Big Data к колоночным хранилищам относятся базы типа «семейство столбцов» (Column Family). В таких системах сами значения хранятся в столбцах (колонках), представленных в отдельных файлах. Благодаря такой модели данных можно хранить большое количество атрибутов в сжатом виде, что ускоряет выполнение запросов к базе, особенно операции поиска и агрегации данных . Наличие временных меток (timestamp) позволяет использовать такие СУБД для организации счётчиков, регистрации и обработки событий, связанных со временем: системы биржевой аналитики, IoT/IIoT-приложения, систему управления содержимым и т.д. Самой известной колоночной базой данных является Google Big Table, а также основанные на ней Apache HBase и Cassandra. Также к этому типу относятся менее популярные ScyllaDB, Apache Accumulo и Hypertable .
- Графовое хранилище представляют собой сетевую базу, которая использует узлы и рёбра для отображения и хранения данных . Поскольку рёбра графа являются хранимыми, его обход не требует дополнительных вычислений (как соединение в SQL). При этом для нахождения начальной вершины обхода необходимы индексы. Обычно графовые СУБД поддерживают ACID-требования и специализированные языки запросов (Gremlin, Cypher, SPARQL, GraphQL и т.д.) . Такие СУБД используются в задачах, ориентированных на связи: социальные сети, выявление мошенничества, маршруты общественного транспорта, дорожные карты, сетевые топологии . Примеры графовых баз: InfoGrid, Neo4j, Amazon Neptune, OrientDB, AllegroGraph, Blazegraph, InfiniteGraph, FlockDB, Titan, ArangoDB.
Виды NoSQL-СУБД