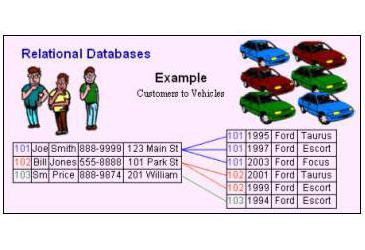
Postgresql субд
Содержание:
- Выполнение запросов с помощью psql
- Notes
- Общие параметры настройки Permalink
- Examples
- Преимущества и особенности СУБД PostgreSQL
- О продукте
- Установка и настройка
- Разработка
- Поддержка стандартов, возможности, особенности
- Open Source-лицензированная база данных
- Why use PostgreSQL?
- 2019
- 7.8.2. Data-Modifying Statements in WITH
Выполнение запросов с помощью psql
Для запуска SQL-запросов используют SQL Server Management Studio, также называемую SSMS или SqlWb. Если пользователь предпочитает интерфейс GUI для выполнения запросов, нужно попробовать pgAdmin III, расположенный в меню «Пуск-> Программы» в разделе PostgreSQL 8.3 на машинах Windows. После запуска PostgreSQL можно запустить psql, открыв оболочку PostgreSQL и набрав > psql my_database, где my_database имя базы данных.
Если опускается имя базы данных, psql по умолчанию, то получают доступ к базе данных с тем же именем, что и имя пользователя CSE. Когда psql откроется, появится сообщение следующего вида.
Строка michaelr=# представляет собой приглашение для операторов SQL, которые отправляются на сервер базы данных, или команды, отличные от SQL, интерпретируемые psql. Здесь michaelr — это имя базы данных, оно может отличаться в системе
Как следует из сообщения, пользователь выходит из psql, набрав \q и нажав Enter, при этом нужно обратить внимание на отсутствие точки с запятой, это необходимо, потому что \q — это не оператор SQL
Notes
See Chapter 11 for information
about when indexes can be used, when they are not used, and in
which particular situations they can be useful.
| Caution |
|
Hash index operations are not presently WAL-logged, so |
Currently, only the B-tree, GiST and GIN index methods support
multicolumn indexes. Up to 32 fields can be specified by default.
(This limit can be altered when building PostgreSQL.) Only B-tree currently supports
unique indexes.
An operator class can be specified
for each column of an index. The operator class identifies the
operators to be used by the index for that column. For example, a
B-tree index on four-byte integers would use the int4_ops class; this operator class includes
comparison functions for four-byte integers. In practice the
default operator class for the column’s data type is usually
sufficient. The main point of having operator classes is that for
some data types, there could be more than one meaningful
ordering. For example, we might want to sort a complex-number
data type either by absolute value or by real part. We could do
this by defining two operator classes for the data type and then
selecting the proper class when making an index. More information
about operator classes is in Section 11.9 and in Section 35.14.
For index methods that support ordered scans (currently, only
B-tree), the optional clauses ASC,
DESC, NULLS
FIRST, and/or NULLS LAST can be
specified to modify the sort ordering of the index. Since an
ordered index can be scanned either forward or backward, it is
not normally useful to create a single-column DESC index — that sort ordering is already
available with a regular index. The value of these options is
that multicolumn indexes can be created that match the sort
ordering requested by a mixed-ordering query, such as SELECT ... ORDER BY x ASC, y DESC. The NULLS options are useful if you need to support
«nulls sort low» behavior, rather than
the default «nulls sort high», in
queries that depend on indexes to avoid sorting steps.
For most index methods, the speed of creating an index is
dependent on the setting of .
Larger values will reduce the time needed for index creation, so
long as you don’t make it larger than the amount of memory really
available, which would drive the machine into swapping.
Use DROP INDEX to remove an
index.
Общие параметры настройки Permalink
Конфигурирование базы данных PostgreSQL может быть сложным процессом. Ниже приведены некоторые основные параметры конфигурации, рекомендуемые при использовании PostgreSQL в Linode. Все эти параметры более подробно описаны в руководстве по настройке PostgreSQL.
Директива Задача listen_addresses = ‘localhost’ По умолчанию Postgres прослушивает только localhost. Однако, редактируя этот раздел и заменяя localhostIP, можно заставить Postgres прослушивать другой IP-адрес. Используйте ‘*’ для прослушивания всех IP-адресов. max_connections = 50 Устанавливает точное максимальное количество подключений клиентов. Чем выше значение, тем больше ресурсов потребует Postgres. Необходимо отрегулировать это значение в зависимости от размера Linode и трафика, который ожидается от базы данных. shared_buffers = 128 МБ Как указано в официальной документации, эта директива изначально устанавливается на низкое значение. На платформе Linode это может быть 1/4 ОЗУ
wal_level При настройке экземпляра Postgres важно учитывать запись в журнале записи (WAL). WAL может сохранять базу данных в чрезвычайной ситуации, одновременно записывая и регистрируя
Поэтому изменения записываются, даже если машина теряет мощность. Перед настройкой рекомендуется прочитать руководство DSHL по пониманию WAL и официальную главу о надежности WAL . synchronous_commit = off При использовании Linode можно включить настоящую Директиву off. archive_mode = on Включение режима архивирования — это жизнеспособная стратегия увеличения избыточности ваших резервных копий.
Examples
To create a B-tree index on the column title in the table films:
CREATE UNIQUE INDEX title_idx ON films (title);
To create an index on the expression lower(title), allowing efficient case-insensitive
searches:
CREATE INDEX ON films ((lower(title)));
(In this example we have chosen to omit the index name, so the
system will choose a name, typically films_lower_idx.)
To create an index with non-default collation:
CREATE INDEX title_idx_german ON films (title COLLATE "de_DE");
To create an index with non-default sort ordering of
nulls:
CREATE INDEX title_idx_nulls_low ON films (title NULLS FIRST);
To create an index with non-default fill factor:
CREATE UNIQUE INDEX title_idx ON films (title) WITH (fillfactor = 70);
To create a GIN index with
fast updates disabled:
CREATE INDEX gin_idx ON documents_table USING gin (locations) WITH (fastupdate = off);
To create an index on the column code
in the table films and have the index
reside in the tablespace indexspace:
CREATE INDEX code_idx ON films (code) TABLESPACE indexspace;
To create a GiST index on a point attribute so that we can
efficiently use box operators on the result of the conversion
function:
CREATE INDEX pointloc
ON points USING gist (box(location,location));
SELECT * FROM points
WHERE box(location,location) && '(0,0),(1,1)'::box;
To create an index without locking out writes to the
table:
Преимущества и особенности СУБД PostgreSQL
СУБД PostgreSQL использует для своих баз данных реляционную модель, поддерживая стандартный язык запросов SQL. При этом PostgreSQL предоставляет широкий спектр возможностей. Можно сказать, что Postgres обладает почти всеми возможностями, существующими в других базах данных (как коммерческих, так и Open Source), а также рядом дополнительных.
Сегодня СУБД PostgreSQL работает почти на всех UNIX-платформах, в том числе и на UNIX-подобных системах (FreeBSD и Linux). Вы сможете использовать эту базу данных и на Windows NT Server, и на Windows 2000 Server, и для разработки рабочих станций ME.
Рассмотрим краткий перечень преимуществ и функциональных возможностей СУБД PostgreSQL:
1. Надежность. Надёжность СУБД PostgreSQL проверена и доказана. Она обеспечивается соответствием принципам ACID (атомарность, изолированность, непротиворечивость, сохранность данных), многоверсионностью, наличием Write Ahead Logging (WAL) — общепринятого механизма протоколирования всех существующих транзакций. Сюда же стоит отнести и возможность восстановления базы данных Point in Time Recovery (PITR), репликацию, поддержку целостности данных на уровне схемы.
2. Производительность. В СУБД PostgreSQL она основана на применении индексов, наличии гибкой системы блокировок и интеллектуального планировщика запросов, использовании системы управления буферами памяти и кэширования. Не стоит забывать и про отличную масштабируемость при конкурентной работе.
3. Расширяемость. Для СУБД PostgreSQL это означает, что пользователь может настроить систему посредством определения новых функций, типов, языков, агрегатов, индексов и операторов. А объектная ориентированность СУБД PostgreSQL даёт возможность переносить логику приложения на уровень базы данных, а это, в свою очередь, заметно упрощает разработку клиентов, ведь вся бизнес-логика находится в БД. При этом функции в Postgres однозначно определяются названием, типами и числом аргументов.
4. Поддержка SQL. Её уже упоминали, однако кроме главных возможностей, которые присущи любой SQL-базе, PostgreSQL поддерживает схемы, подзапросы, внешние связки, правила, курсоры, наследование таблиц, триггеры и много чего ещё.
5. Поддержка многочисленных типов данных. СУБД PostgreSQL поддерживает численные (целые, денежные, с фиксированной/плавающей точкой), булевые, символьные, составные, сетевые типы данных, а также перечисление, типы «дата/время», геометрические примитивы, массивы, XML- и JSON-данные. Плюс можно создавать свои типы данных.
Конечно, это далеко не всё, но для общего понимания возможностей СУБД PostgreSQL вполне достаточно. Естественно, база данных заслуживает внимания, особенно если учесть, что она имеет открытый исходный код и распространяется свободно. Освоить эту СУБД вы cможете на курсе в OTUS.
О продукте
PostgreSQL поддерживается на всех современных Unix системах (34 платформы), включая наиболее распространенные, такие как Linux, FreeBSD, NetBSD, OpenBSD, SunOS, Solaris, DUX, а также под macOS. Начиная с версии 8.X PostgreSQL работает в «native» режиме под MS Windows NT, Win2000, WinXP, Win2003. Известно, что есть успешные попытки работать с PostgreSQL под Novell Netware 6 и OS2.
PostgreSQL неоднократно признавалась базой года, например, Linux New Media AWARD 2004, 2003 Editors’ Choice Awards, 2004 Editors’ Choice Awards.
PostgreSQL используется как полигон для исследований нового типа баз данных, ориентированных на работу с потоками данных — это проект TelegraphCQ, стартовавший в 2002 году в Беркли после успешного проекта Telegraph (название главной улицы в Беркли).
Установка и настройка
В данном разделе представлена инструкция по установки и настройке PostgreSQL для разных ОС
Установка
Если установка происходит на macOS, то процесс установки можно запустить командой:
brew install postgresql
На Linux СУБД устанавливается так:
sudo apt-get install postgresql postgresql-contrib
После того, как все загружено и установлено, можно проверить, все ли в порядке, и какая стоит версия PostgreSQL. Для этого выполните следующую команду:
postgres --version
Инструкция по установке в цифровом формате
Настройка
Работа с PostgreSQL может быть произведена через командную строку (терминал) с использованием утилиты psql – инструмент командной строки PostgreSQL.
Необходимо ввести следующую команду:
psql postgres (для выхода из интерфейса используйте \q)
Этой командой запускается утилита psql. Хотя есть много сторонних инструментов для администрирования PostgreSQL, нет необходимости их устанавливать, т. к. psql удобен и отлично работает.
Если нужна помощь, введите (или ) в psql-терминале. Появится список всех доступных параметров справки. Вы можете ввести , если вам нужна помощь по конкретной команде. Например, если ввести в консоли psql, отобразится синтаксис команды .
1 Description update rows of a table
2 WITH RECURSIVE with_query [,
3 UPDATE ONLY table_name * AS alias
4 SET { column_name = { expression | DEFAULT } |
5 ( column_name [, ) = ( { expression | DEFAULT } [, ) |
6 ( column_name [, ) = ( sub-SELECT )
7 } [,
8 FROM from_list
9 WHERE condition | WHERE CURRENT OF cursor_name
10 RETURNING * | output_expression AS output_name [,
Для начала необходимо проверить наличие существующих пользователей и баз данных. Выполните следующую команду, чтобы вывести список всех баз данных:
\list или \l
Рисунок 1 — Результат выполнения операции \l
На рисунке выше вы видите три базы данных по умолчанию и суперпользователя postgres, которые создаются при установке PostgreSQL.
Чтобы вывести список всех пользователей, выполните команду . Атрибуты пользователя postgres говорят нам, что он суперпользователь.
Рисунок 2 — Результат выполнения операции \du
Разработка
PostgreSQL развивается силами международной группы разработчиков (PGDG), в которую входят как непосредственно программисты, так и те, кто отвечают за продвижение PostgreSQL (Public Relation), за поддержание серверов и сервисов, написание и перевод документации, всего на 2005 год насчитывается около 200 человек. Другими словами, PGDG — это сложившийся коллектив, который полностью самодостаточен и устойчив. Проект развивается по общепринятой среди открытых проектов схеме, когда приоритеты определяются реальными нуждами и возможностями. При этом, практикуется публичное обсуждение всех вопросов в списке рассылке, что практически исключает возможность неправильных и несогласованных решений.
Это относится и к тем предложениям, которые уже имеют или рассчитывают на финансовую поддержку коммерческих компаний.
Цикл работой над новой версией обычно длится 10-12 месяцев (сейчас ведется дискуссия о более коротком цикле 2-3 месяца) и состоит из нескольких этапов.
Поддержка стандартов, возможности, особенности
PostgreSQL
PostgreSQL поддерживает большинство возможностей стандарта SQL: 2011, ACID-совместимая и транзакционная (включая большинство DDL утверждения) избегает проблемы блокировки с помощью механизма Многоверсионное управление параллельным доступом (MVCC), обеспечивает иммунитет к «грязному» чтению и полую сериализационность; управляет комплексными SQL запросами используя множество индексированных методов, которые недоступны в других базах данных; имеет обновляемые представления и материализованные представления, триггеры, внешние ключи; поддерживает функции и хранимые процедуры, и другие возможности расширения, и имеет множество расширений, написанных третьими лицами. В дополнение к возможности работы с основными фирменными и с открытым исходным кодом базами данных, PostgreSQL поддерживает миграцию из них, путем своей обширной поддержки стандарта SQL и доступных инструментов миграции. Фирменные расширения в базах данных, таких как Oracle можно эмулировать с помощью встроенных и сторонних расширений совместимости с открытым исходным кодом. Последние версии также обеспечивают репликацию самой базы данных для доступности и масштабируемости.
PostgreSQL является кросплотформенной и работает на множестве операционных систем, включая Linux, FreeBSD, macOS, Solaris, и Microsoft Windows. Начиная с Mac OS X 10.7 Lion Server, PostgreSQL это стандартная база данных по умолчанию, и клиентские инструменты PostgreSQL идут в комплекте с настольной версией. Подавляющее большинство дистрибутивов Linux имеет PostgreSQL доступным в поддерживаемых пакетах.
PostgreSQL разработан PostgreSQL Global Development Group, разнообразной группой из многих компаний и отдельных вкладчиков. Это свободное и открытое программное обеспечение, распространяемое по условиям Лицензии PostgreSQL, разрешительной лицензии свободного программного обеспечения.
Поскольку СУБД PostgreSQL выпускается под либеральной лицензией, её можно бесплатно использовать, модифицировать и распространять для любых целей, включая личные, коммерческие или академические.
На данный момент (версия 9.4.5), в PostgreSQL имеются следующие ограничения:
| Максимальный размер базы данных | Нет ограничений |
| Максимальный размер таблицы | 32 Тбайт |
| Максимальный размер записи | 1,6 Тбайт |
| Максимальный размер поля | 1 Гбайт |
| Максимум записей в таблице | Нет ограничений |
| Максимум полей в записи | 250—1600, в зависимости от типов полей |
| Максимум индексов в таблице | Нет ограничений |
Сильными сторонами PostgreSQL считаются:
- высокопроизводительные и надёжные механизмы транзакций и репликации;
- расширяемая система встроенных языков программирования: в стандартной поставке поддерживаются PL/pgSQL, [PL/Perl, PL/Python и PL/Tcl; дополнительно можно использовать PL/Java, PL/PHP, PL/Py, PL/R, PL/Ruby, PL/Scheme, PL/sh и PL/V8, а также имеется поддержка загрузки C-совместимых модулей ;
- поддержка со стороны многих языков программирования: C\C++, Java, Perl, Python, Ruby, ECPG, Tcl, PHP и других.
- наследование;
- легкая расширяемость.
Open Source-лицензированная база данных
В начале XXI века многие компьютерные системы создаются на основе свободно распространяемых программ с открытыми исходными кодами. К их числу относится и PostgreSQL. Что же это означает в действительности?
Когда понятие Open Source применяется к программному обеспечению, оно приобретает специальный смысл. Такое программное обеспечение поставляется вместе с исходными кодами. Это не обязательно значит, что на его применение не налагаются никакие условия. Оно все-таки лицензируется в том смысле, что вы получаете право некоторым образом использовать это программное обеспечение.
Open Source-лицензия дает право на использование, модификацию и распространение программного обеспечения без лицензионных выплат. То есть вы можете работать с PostgreSQL в своей компании так, как это удобно в вашем случае.
Если с программным обеспечением Open Source возникают проблемы, пользователь может или исправить ошибки сам (поскольку у него есть исходные тексты), или же передать код кому-то другому для исправления. Сейчас многие коммерческие компании предлагают поддержку продуктов Open Source, поэтому, приобретая такой продукт, не стоит чувствовать себя «забытым».
Существует несколько разновидностей лицензий Open Source, некоторые из них имеют большее число ограничений на распространение, другие меньшее. Тем не менее все они придерживаются принципа доступности исходных кодов программ и разрешают дальнейшее их распространение.
Наиболее либеральной является лицензия Berkeley Software Distribution (BSD), разрешающая делать с программным обеспечением все что угодно, не предоставляя при этом никаких гарантий. Лицензия на использование PostgreSQL по сути своей аналогична лицензии BSD, она представляет собой заявление об авторских правах, в котором говорится: «Настоящим предоставляется право на использование, копирование, модификацию и распространение данного программного продукта и относящейся к нему документации в любых целях, без оплаты и без подписания соответствующих соглашений при условии, что во всех копиях будет присутствовать уведомление об авторских правах, указанное выше, данный абзац и два последующих». Два следующих абзаца посвящены отказу от каких бы то ни было обязательств и гарантий.
Ресурсы по обучению PostgreSQL
- Информация о базах данных в целом и о PostgreSQL в частности может быть получена из множества источников, как печатных, так и доступных через Интернет.
- Тем, кого интересует тема свободного распространения и открытости исходных кодов в отношении программного обеспечения (Open Source продукты), советуем посетить два следующих сайта:
Why use PostgreSQL?
PostgreSQL comes with many features aimed to help developers build applications, administrators to protect data integrity and build fault-tolerant environments, and help you manage your data no matter how big or small the dataset. In addition to being free and open source, PostgreSQL is highly extensible. For example, you can define your own data types, build out custom functions, even write code from different programming languages without recompiling your database!
PostgreSQL tries to conform with the SQL standard where such conformance does not contradict traditional features or could lead to poor architectural decisions. Many of the features required by the SQL standard are supported, though sometimes with slightly differing syntax or function. Further moves towards conformance can be expected over time. As of the version 13 release in September 2020, PostgreSQL conforms to at least 170 of the 179 mandatory features for SQL:2016 Core conformance. As of this writing, no relational database meets full conformance with this standard.
Below is an inexhaustive list of various features found in PostgreSQL, with more being added in every major release:
-
Data Types
- Primitives: Integer, Numeric, String, Boolean
- Structured: Date/Time, Array, Range, UUID
- Document: JSON/JSONB, XML, Key-value (Hstore)
- Geometry: Point, Line, Circle, Polygon
- Customizations: Composite, Custom Types
-
Data Integrity
- UNIQUE, NOT NULL
- Primary Keys
- Foreign Keys
- Exclusion Constraints
- Explicit Locks, Advisory Locks
-
Concurrency, Performance
- Indexing: B-tree, Multicolumn, Expressions, Partial
- Advanced Indexing: GiST, SP-Gist, KNN Gist, GIN, BRIN, Covering indexes, Bloom filters
- Sophisticated query planner / optimizer, index-only scans, multicolumn statistics
- Transactions, Nested Transactions (via savepoints)
- Multi-Version concurrency Control (MVCC)
- Parallelization of read queries and building B-tree indexes
- Table partitioning
- All transaction isolation levels defined in the SQL standard, including Serializable
- Just-in-time (JIT) compilation of expressions
-
Reliability, Disaster Recovery
- Write-ahead Logging (WAL)
- Replication: Asynchronous, Synchronous, Logical
- Point-in-time-recovery (PITR), active standbys
- Tablespaces
-
Security
- Authentication: GSSAPI, SSPI, LDAP, SCRAM-SHA-256, Certificate, and more
- Robust access-control system
- Column and row-level security
- Multi-factor authentication with certificates and an additional method
-
Extensibility
- Stored functions and procedures
- Procedural Languages: PL/PGSQL, Perl, Python (and many more)
- SQL/JSON path expressions
- Foreign data wrappers: connect to other databases or streams with a standard SQL interface
- Customizable storage interface for tables
- Many extensions that provide additional functionality, including PostGIS
-
Internationalisation, Text Search
- Support for international character sets, e.g. through ICU collations
- Case-insensitive and accent-insensitive collations
- Full-text search
There are many more features that you can discover in the PostgreSQL documentation. Additionally, PostgreSQL is highly extensible: many features, such as indexes, have defined APIs so that you can build out with PostgreSQL to solve your challenges.
PostgreSQL has been proven to be highly scalable both in the sheer quantity of data it can manage and in the number of concurrent users it can accommodate. There are active PostgreSQL clusters in production environments that manage many terabytes of data, and specialized systems that manage petabytes.
2019
Включение в продукты DeviceLock
22 октября 2019 года стало известно, что DeviceLock включил в свои продукты поддержку Postgres Pro и PostgreSQL. Подробнее .
Запуск программы сертификации специалистов по СУБД PostgreSQL
21 мая 2019 года Postgres Professional сообщил о запуске программы сертификации специалистов по СУБД PostgreSQL.
Программа сертификации предусматривает три уровня с возрастающей квалификацией:
- «Профессионал»
- «Эксперт»
- «Мастер»
Для получения сертификата необходимо пройти тестирование в офисе компании Postgres Professional и набрать проходной балл. Материалом для подготовки могут служить авторские курсы Postgres Professional, доступные на сайте, а также регулярно читаемые в сертифицированных учебных центрах. Ежегодно слушателями курсов становятся более 500 человек.
Тест для первого уровня — «Профессионал» — включает в себя 50 вопросов по основам администрирования PostgreSQL и длится 75 минут. Поскольку для каждого релиза PostgreSQL характерны свои особенности администрирования, сертификация соотносится с конкретной версией СУБД. Например, на май 2019 года доступен тест для 10-ой версии PostgreSQL DBA1-10. Для прошедших тестирование на знание PostgreSQL 10 и желающих в будущем подтвердить свои навыки для 11-ой версии достаточно будет пройти короткое дополнительное тестирование, сфокусированное на отличиях продуктов.
Для получения сертификата уровня «Эксперт» понадобится успешно пройти уже три теста:
- DBA2-10 (настройка и мониторинг PostgreSQL)
- DBA3-10 (резервное копирование и репликация PostgreSQL)
- QPT-10 (оптимизация запросов)
А переход на уровень «Мастер» предполагает выполнение практических заданий по работе с PostgreSQL. В дальнейших планах компании Postgres Professional – запуск программы сертификации для разработчиков приложений на PostgreSQL.
Иван Панченко прокомментировал запуск программы сертификации:
|
Специалисты по Postgres становятся все более востребованными на российском рынке, что подтверждают данные кадровых агентств. В такой ситуации необходимы единые стандарты и критерии для оценки уровня знаний. Во многом наша программа сертификации стала ответом на запросы заказчиков и партнеров, заинтересованных в независимом инструменте оценки и повышения квалификации своих сотрудников. Иван Панченко, заместитель генерального директора Postgres Professional |
Совместимость с Live Universal Interface
15 апреля 2019 года компания ФОРС Телеком сообщила о появлении в экосистеме программно-инструментальных средств, совместимых с открытой платформой Postgres Pro/PostgreSQL конструктора пользовательских веб-интерфейсов к базам данных — Live Universal Interface (LUI). Подробнее здесь.
Совместимость с TerraLink xDE
12 марта 2019 года TerraLink сообщил, что TerraLink xDE поддерживает OC семейства Linux и СУБД PostgreSQL. Подробнее .
7.8.2. Data-Modifying Statements in WITH
You can use data-modifying statements (INSERT, UPDATE, or
DELETE) in WITH. This allows you to perform several
different operations in the same query. An example is:
WITH moved_rows AS (
DELETE FROM products
WHERE
"date" >= '2010-10-01' AND
"date" < '2010-11-01'
RETURNING *
)
INSERT INTO products_log
SELECT * FROM moved_rows;
This query effectively moves rows from products to products_log. The DELETE in WITH deletes
the specified rows from products,
returning their contents by means of its RETURNING clause; and then the primary query
reads that output and inserts it into products_log.
A fine point of the above example is that the WITH clause is attached to the INSERT, not the sub-SELECT within the INSERT. This is necessary because data-modifying
statements are only allowed in WITH
clauses that are attached to the top-level statement. However,
normal WITH visibility rules apply, so
it is possible to refer to the WITH
statement’s output from the sub-SELECT.
Data-modifying statements in WITH
usually have RETURNING clauses, as
seen in the example above. It is the output of the RETURNING clause, not the target table of the
data-modifying statement, that forms the temporary table that
can be referred to by the rest of the query. If a
data-modifying statement in WITH lacks
a RETURNING clause, then it forms no
temporary table and cannot be referred to in the rest of the
query. Such a statement will be executed nonetheless. A
not-particularly-useful example is:
WITH t AS (
DELETE FROM foo
)
DELETE FROM bar;
This example would remove all rows from tables foo and bar. The
number of affected rows reported to the client would only
include rows removed from bar.
Recursive self-references in data-modifying statements are
not allowed. In some cases it is possible to work around this
limitation by referring to the output of a recursive WITH, for example:
WITH RECURSIVE included_parts(sub_part, part) AS (
SELECT sub_part, part FROM parts WHERE part = 'our_product'
UNION ALL
SELECT p.sub_part, p.part
FROM included_parts pr, parts p
WHERE p.part = pr.sub_part
)
DELETE FROM parts
WHERE part IN (SELECT part FROM included_parts);
This query would remove all direct and indirect subparts of
a product.
Data-modifying statements in WITH
are executed exactly once, and always to completion,
independently of whether the primary query reads all (or indeed
any) of their output. Notice that this is different from the
rule for SELECT in WITH: as stated in the previous section,
execution of a SELECT is carried only
as far as the primary query demands its output.
The sub-statements in WITH are
executed concurrently with each other and with the main query.
Therefore, when using data-modifying statements in WITH, the order in which the specified updates
actually happen is unpredictable. All the statements are
executed with the same snapshot (see
Chapter 13), so they cannot
«see» one another’s effects on the
target tables. This alleviates the effects of the
unpredictability of the actual order of row updates, and means
that RETURNING data is the only way to
communicate changes between different WITH sub-statements and the main query. An
example of this is that in
WITH t AS (
UPDATE products SET price = price * 1.05
RETURNING *
)
SELECT * FROM products;
the outer SELECT would return the
original prices before the action of the UPDATE, while in
WITH t AS (
UPDATE products SET price = price * 1.05
RETURNING *
)
SELECT * FROM t;
the outer SELECT would return the
updated data.
Trying to update the same row twice in a single statement is
not supported. Only one of the modifications takes place, but
it is not easy (and sometimes not possible) to reliably predict
which one. This also applies to deleting a row that was already
updated in the same statement: only the update is performed.
Therefore you should generally avoid trying to modify a single
row twice in a single statement. In particular avoid writing
WITH sub-statements that could affect
the same rows changed by the main statement or a sibling
sub-statement. The effects of such a statement will not be
predictable.
At present, any table used as the target of a data-modifying
statement in WITH must not have a
conditional rule, nor an ALSO rule,
nor an INSTEAD rule that expands to
multiple statements.