Key collector
Содержание:
- Сбор семантики
- Редактирование ячеек
- Выделение и отметка фраз
- Сбор частот
- Удаление и сокрытие групп
- Переименование и цветовая маркировка
- Процесс парсинга в Кей Коллекторе
- Как установить программу на компьютер
- Что собой представляет key collector?
- Остальные настройки Кей Коллектора
- Что может Key Collector
- Что такое Key Collector?
- Быстрая работа с программой.
- Поиск конкурентов и их объявлений
- Общая настройка Кей Коллектора
- Неявные дубли
- Сбор частотностей
- Заключение
Сбор семантики
Допустим, вам нужно собрать семантическое ядро для рекламы в Яндекс.Директ. Запустите Key Collector и откройте настройки кликом по шестеренке:
Настройки парсинга
Перейдите в раздел «Парсинг» и здесь внесите следующие изменения:
1) На вкладке «Общие» уберите знак плюс в поле «Удалять символы» – в Директе плюсы мы не используем.
2) На вкладке «Yandex.Direct» впишите данные по аккаунту, который нужно предварительно создать специально для парсинга.
Дело в том, что Яндекс лоялен к парсерам, так как с помощью них рекламодатели могут настроить более качественные рекламные объявления. Это с одной стороны.
С другой – рабочий аккаунт использовать ни в коем случае нельзя. Яндекс может его забанить за нарушение правил пользования сервисом (из-за автоматических запросов)
Лучше рискнуть потерять доступ к «фейковому» аккаунту, а не к настоящему.
Важно! Несмотря на то, что аккаунты «фейковые», задавайте им читабельные имена пользователей, чтобы впредь процесс не тормозили капчи Яндекса.
Также обратите внимание на настройки:
- Автоматически перезапускать процесс при ошибке «Сервис недоступен» через 120 секунд. Иногда Yandex.Direct становится временно недоступен. Эта галочка включает повторную попытку собрать статистику.
- Валюта. По умолчанию цены, бюджеты, стоимость клика в рублях. После изменения типа необходимо переоткрыть проект.
3) На вкладке Yandex Wordstat ничего не меняйте – подойдут настройки по умолчанию.
Кратко скажем об основных.
Глубина парсинга – это количество обходов списка слов, которое делает программа для одного ключевика. Соответственно, чем больше раз – тем больше слов и времени идет на обработку. Рекомендованная глубина 2 – так вы сразу получаете результаты парсинга + дополнительную выдачу по каждому из них.
Парсить страниц – сколько страниц в выдаче будет просматривать программа. Максимум в Wordstat – 40, на каждой – до 50 фраз, то есть 2 тысячи результатов по одной фразе. Сервис предлагает такое количество лишь для ВЧ-запросов.
Добавлять в таблицу фразы с частотностями … – задаем диапазон частотностей. Чтобы избежать потери важных ключевиков, используйте фильтрацию в таблицах данных.
Не снимать частотности для фраз с базовой частотностью равной или ниже, чем … – это экономит время, трафик, а также позволяет снизить вероятность получения капчи, исключая из проверки заведомо не интересующие фразы.
Не добавлять фразы для глубинного исследования с базовой частотностью равной или ниже, чем … – это сокращает время на сбор информации за счет игнорирования недостаточно популярных фраз с низкой базовой частотностью.
Считать медиану за последние … месяцев. Программа вычисляет значение по указанному периоду при сборе данных о сезонности.
Принудительно очищать знак + из запросов для частотностей « » и «!». При снятии частотностей вида « » и «!», запрос заключается в кавычки. При этом знак +, если это оператор, теряет смысл – его нужно отфильтровать, что и позволяет эта опция. Если это часть запроса, фильтрация не нужна.
Получать статистику через Yandex.Direct. Данная опция позволяет снимать статистику Yandex.Wordstat (кроме данных сезонности) через интерфейс Yandex.Direct. Это резервный режим на случай, если заблокирован доступ к Yandex.Wordstat. Для его запуска нужно прописать доступ к аккаунтам Яндекс.Директа во вкладке «Yandex.Direct».
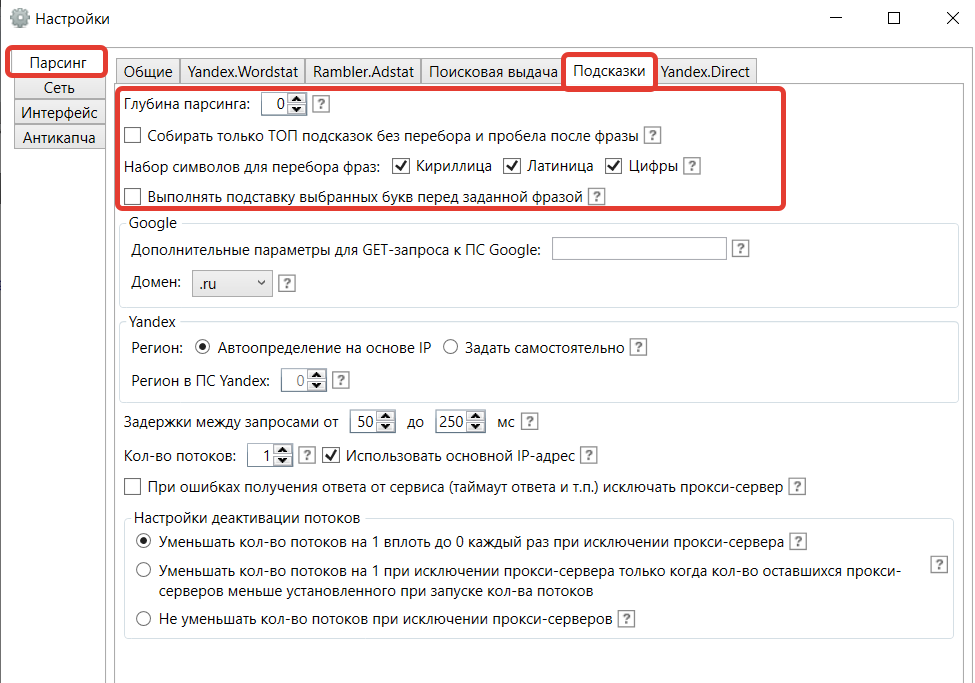
4) На вкладке «Подсказки» – аналогично.
Внизу окна программы также не забудьте настроить целевые регионы для Вордстата и Яндекс.Директа (или другой системы, для которой собираете семантическое ядро).
На этом настройки парсинга готовы.
С чего начать парсинг
Кликните иконку «Добавить фразы»:
В окно вставьте исходные фразы (маски / базисы ключевых слов):
Рекомендуем подключить автораспознавание капчи, чтобы она не мешала работе Key Collector. Особенно если вы планируете парсить большие объемы ключей. Актуальные цифры по стоимости смотрите в разделе «Антикапча» по ссылкам.
Нажмите кнопку «Начать сбор» в этом окне – и процесс запустится!
Кстати, найти еще больше целевых ключей помогут поисковые подсказки. Собрать их в Key Collector можно нажатием следующей кнопке в верхнем меню:
Затем остается скопировать сюда список маркеров и отметить галочкой поисковую систему, из которой хотите получить подсказки – и сервис начнет сбор.
Редактирование ячеек
Вы можете изменять значения ячеек в таблице. При этом редактировать можно как сами фразы, так и данные в колонках статистики (если они не заблокированы для редактирования).
Перед редактированием фраз убедитесь, что это разрешено в «Настройках — Интерфейс — Таблица данных — Управление таблицей».
Для редактирования фразы нажмите клавишу F2 или совершите двойной клик мышкой по фразе. Ячейка перейдет в режим редактирования.
В силу ограничения уникальности фраз в пределах одной группы допускается ввод только уникальных фраз (в случае нахождения полного дубликата операция редактирования будет отменена).
Для редактирования ячеек в остальных колонках можно поступить аналогичным образом. Однако в дополнение к этому также становится доступной контекстная вкладка«Таблица данных», где вы можете найти дополнительные инструменты для редактирования значений.
Вы можете изменить значения нескольких ячеек в одно действие. Для этого выделите ячейки и нажмите кнопку «Редактировать». В открывшемся диалоговом окне задайте желаемое значение и нажмите кнопку «OK».
Выделение и отметка фраз
Большинство активных функций в программе выполняют операцию либо для выделенных, либо для отмеченных фраз. Выделение удобней использовать для мелких операций, а отметку — для сложных или комплексных процессов.
Выделение фраз выполнятся путем протяжки курсора с зажатой левой кнопкой мыши в области ячеек или зоны нумерации строк. Поддерживается использование выделения с Ctrl и Shift.
В отличие от обычного выделения статус отметки строк сохранятся в проекте и не меняется даже после перезапуска программы.
Например, вы можете продвигаться по таблице вниз, отмечать запросы, не рискуя при этом случайно сбросить выделение. Выделение запросов может использоваться как вспомогательный функционал (можно массово изменить статус отметки для выделенных фраз).
Сбор частот
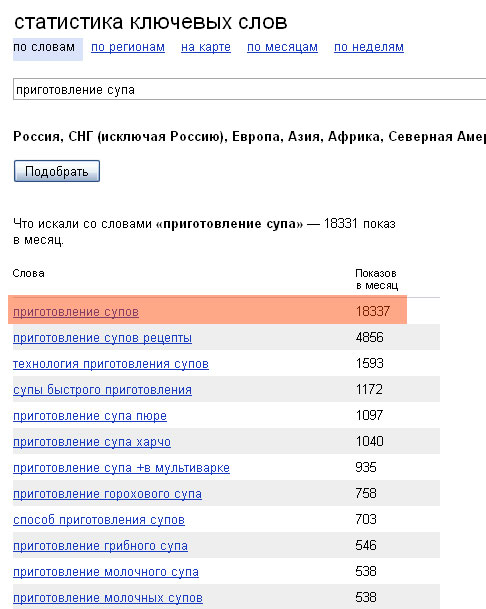
Сбор частот позволяет оценить популярность запросов.
Сервис выдает кол-во показов запроса за последние 30 дней.
Статистика обновляется не ежедневно, поэтому не воспринимайте этот период буквально.
Сервис поддерживает различные операторы поиска, поэтому программа способна получать несколько видов частот.
Программа автоматически добавляет нужные операторы при сборе того или иного вида частот (добавлять операторы вручную к текст запросов не требуется).
Базовая частота
Базовая частота соответствует широкому типу вхождения слов. Для выполнения запроса достаточно отправить сам запрос в исходном виде:
- свежий хлеб
- условная вероятность
- теорема Байеса
В результатах могут быть учтены и другие фразы, косвенно относящиеся к запросу «свежий хлеб» в широком соответствии: купить свежий хлеб, свежий ржаной хлеб, рецепт хлеба, свежая выпечка и др.
Фразовая частота
Фразовая частота фиксирует состав слов в искомом запросе, и показы считаются для словосочетания целиком. Для выполнения запроса необходимо добавить двойные кавычки:
- «свежий хлеб»
- «теорема Байеса»
- «плотность распределения»
В результатах к запросу «свежий хлеб» будут учтены только фразы с тем же набором слов:: свежий хлеб, хлеба свежего и др.
Точная фразовая частота
Точная фразовая частота фиксирует не только состав, но и словоформы слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе и взять его в двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе: свежий хлеб, хлеб свежий (порядок не фиксируется).
Точная фразовая частота с порядком
Точная фразовая с порядком частота фиксирует состав, словоформы и порядок следования слов в искомом запросе. Для выполнения запроса необходимо добавить оператор ! перед каждым словом в запросе, взять его в и двойные кавычки:
- «!свежий !хлеб»
- «!теорема !Байеса»
- «!плотность !распределения»
В результатах к запросу «!свежий хлеб!» будут учтены только фразы с тем же набором слов в той же словоформе и том же порядке следования: свежий хлеб.
Частота по маске
Вы можете самостоятельно определить маску запроса, используя поддерживаемые сервисом операторы.
Маска запроса должна содержать фрагмент QUERY, который при сборе частот будет заменяться на текст исследуемого запроса.
Удаление и сокрытие групп
Вы можете удалять или скрывать ненужные группы с фразами через контекстное меню или горячими клавишами.
При добавлении фраз (вручную или в процессе парсинга) при использовании режима добавления с пропуском существующих фраз в других группах фразы в скрытых группах будут считаться существующими (несмотря на то, что сама группа скрыта и не отображается в дереве групп), т.е. такие фразы будут пропущены как дубликаты, а фразы в помеченных на удаление группах будут считаться отсутствующими, т.к. такие фразы будут добавлены в таблицу.
Отличие помеченной на удаление группы от скрытой состоит также в том, что при закрытии проекта программа запросит подтверждение на безвозвратное удаление помеченных на удаление групп, когда как скрытые группы так и продолжат существовать в проекте.
Для удаления или сокрытия групп сперва необходимо выделить группы.
Для выделения подряд идущих групп удобно воспользоваться зажатой клавишей Shift и кликнуть сперва по первой, а затем по последней группе в требуемом диапазоне. При необходимости выделить подгруппы некоторых групп воспользуйтесь соответствующей кнопкой в контекстном меню заголовка группы или же на вкладке инструментов «Управление группами».
Восстановление групп
Для восстановления скрытых или помеченных на удаление групп нажмите кнопку в нижнем правом углу панели управления группами, отметьте нужные группы и нажмите «Восстановить».
Переименование и цветовая маркировка
Для переименования группы дважды кликните по ее заголовку или воспользуйтесь соответствующим пунктом в контекстном меню.
Для массового редактирования заголовков можно воспользоваться функциями в меню «Формат заголовков» на вкладке «Управление группами».
Вы также можете помечать цветами заголовки групп. Для пометки нескольких выделенных групп зажмите клавишу Ctrl.
В «Настройках — Интерфейс — Управление группами» можно задать список цветов в формате цветов HTML (HEX ARGB).
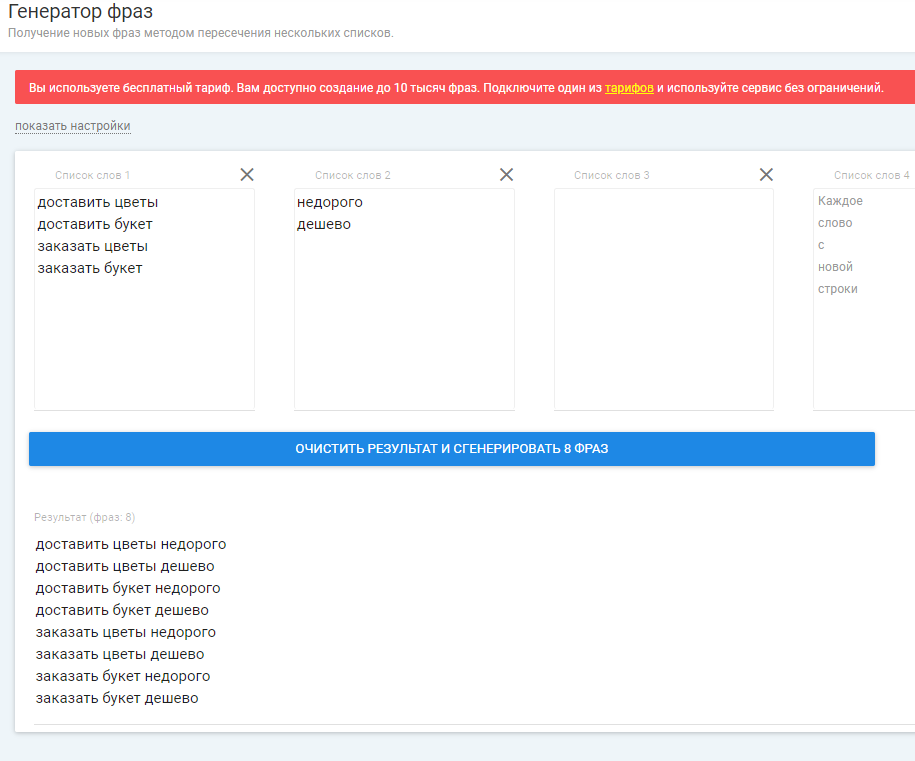
Массовое переименование групп по маске
Функция изменения выделенных групп позволяет массово изменить заголовки выделенных групп по заданному пользователем шаблону. Например, можно не только назначить нескольким группам новый единый заголовок, но и сохранить в нем значения прошлых заголовков.
Группы «кастрюли», «сковородки», «чашки» могут быть переименованы в «кастрюли Москва», «сковородки Москва», «чашки Москва» (в существующему заголовку добавлено слово «Москва»). Или же можно выполнить замену части заголовка: «кабель 2.5», «провод 2.5» на «кабель 1.75», «провод 1.75» (выполнена замена 2.5 на 1.75).
Простые замены
Простая замена может использовать в маске макрос {HEADER}, который вставит на место {HEADER} прошлое значение заголовка группы.
Например, маска «купить {HEADER} Москва» превратит группы «носки», «колготки» в «купить носки Москва», «купить колготки Москва».
Слайсинг в стиле numpy
Помимо простой замены с сохранением полного прошлого заголовка иногда требуется модифицировать прошлый заголовок: отрезать какую-то его часть с начали или конца, использовать какую-то информацию из середины и т.п.
Для этих нужд используется широко известный синтаксис слайсинга в numpy (библиотека Python), поэтому если вы его освоите, то это пригодится не только при работе с Key Collector, но и для решения других задач.
Вы можете извлекать наборы символов (подстроки), задавая границы и длину строк с начала или с конца. Приведем несколько примеров.
Отрезать начало строки — {HEADER}N:
Можно указать индекс начала строки N с начала или с конца.
- {HEADER}4: — взять подстроку, начиная с 4-го символа с начала и до конца
- мск интернет —> интернет
- {HEADER}-5: — взять подстроку, начиная с 5-го символа с конца и до конца
-
блин 25 кг
—> 25 кг
Отрезать конец строки — {HEADER}:M
Можно указать индекс конца строки M с начала или с конца.
- {HEADER}:8 — взять подстроку, начиная с начала и до 8-го символа
- интернет мск —> интернет
- {HEADER}:-6 — взять подстроку, начиная с начала и заканчивая 6-м символом с конца
- саженцы москва —> саженцы
Взять из середины строки — {HEADER}N:M
Здесь можно указать индекс начала N и конца M подстроки. Аналогично можно указывать индексацию с начала или с конца строки, но индекс конца M должен быть расположен в абсолютном значении дальше индекса начала N.
- {HEADER}4:6 — взять подстроку, начиная с 4-го символа и заканчивая 6-м символом
- 122.65 частота —> 65
Функции замены
Поддерживается функция замены значения в заголовке на новое значение REPLACE(«old»;»new»). Использовать дополнительную индексацию или маску в параметрах функции не допускается (т.е. в кавычках должны быть заданы обычные слова или части слов.
- REPLACE(«мск»;»спб») — заменить в заголовке «мск» на «спб»
- ворота мск —> ворота спб
Также поддерживается расширенная функция замены по регулярному выражению REPLACERG(«pattern»;»replacement»). Опытные пользователи могут выполнять более сложные замены, используя синтаксис регулярных выражений.
Процесс парсинга в Кей Коллекторе
Сам процесс достаточно прост и не является чем-то сложным и выполняется в автоматическом режиме.
Первоначально нужно сразу же выставить нужное гео для парсинга, это делается в самом низу программы:
После этого нужно создать папки, куда будут помещаться спарсенные ключевые слова, папки создаются в левой колонке программы. Конечно можно парсить все в одну папку и потом делать группировку ключей, но логичнее и удобнее заранее поделить маски ключей по смыслу и парсить маски по папкам. Например: есть две маски ключей, которые хотим спарсить — вызов такси и заказать такси, для удобства дальнейшей работы с ключами, парсим маски не в общую папку, а в соответствующие две папки, чтобы ключи уже были отсортированы.
Кроме этого, если масок не много, то можно каждую папку назвать маской и тогда программа сделает парсинг по названию папки, что является очень удобным функционалом.
Для этого заранее создаем нужные папки и нажимаем на парсинг с вордстата. По умолчанию стоит галочка «Добавить в текущую группу», но нужно поставить галочку «Распределить по группам» и нажать на красную стрелочку, как показано на картинке. Здесь можно в каждую папку поместить нужные маски (т.е. не каждую маску парсить отдельно, а чтобы в одной папке были распарсено сразу несколько масок ключей); можно убрать не нужные папки и стоит заметить, что названия папок тоже будут распарсены (если этого вам не нужно просто убираем не нужное ключевое слово). Далее нажимаем на «Начать сбор» и происходит парсинг, после которого идет следующая работа — сбор минус слов, чистка ключей и их группировка:
Как установить программу на компьютер
Оплатите и скачайте программу на официальном сайте. Цена одной лицензии 1 800 рублей.
Запустите установочный файл скачанной программы и следуйте инструкции.
После установки нужно активировать лицензию:
- При запуске установленной программы появится окно с уникальным идентификатором (HID).
- Лицензия (файл lic.license) придет на почтовый ящик после оплаты, ее нужно положить в папку с программой. По умолчанию Кей Коллектор устанавливается в «Мои документы/Key Collector».
- Можно запускать программу и пользоваться.
Если возникли трудности, ищите всю информацию по инсталляции на сайте программы.
Что собой представляет key collector?
Из слов в названии — кей коллектор — становится понятно: это сборщик ключей. В понимании SEO-шников смыслом программы является собирание ключевых слов для продвижения сайта вверх по списку в поиске
Еще одна особенность «кей», на которую стоит обратить внимание — помощь с определением стоимости сайта и соответствием содержимого ядра. Это приятная, простая и сильная программа для продвижения порталов
- Основные функции программы:
- Подбор ключевой фразы – запроса/запросов;
- Определение стоимости и ценности содержащихся фраз;
- Выявление страницы по релевантности;
- Съем по позициям;
- Советы по перелинковке сайта.
Знакомство с программой Кей коллектор:
Итак, вам для сайта нужна SEO-оптимизация, и вы начали работу. Прежде, чем вы запустите программу и приступите к полномасштабной работе с «кей», разбирая ядро, необходимо узнать и понять ключевые моменты, имеющие отношение к seo и сопутствующим моментам. Без знакомства с ними невозможно работать не только в программе, но и в области SEO в принципе.Для начала знакомства открываем вкладку «Быстрое знакомство с Key Collector».Пункт 1 рассказывает, что система не любит наглые методы продвижения. За это аккаунты, привязанные к Key Collector могут подвергнуться блокировки со стороны поисковых систем.
- Чтобы избежать этих проблем, не следует применять:
- слишком большой поток данных из ядра;
- малые задержки, когда запросы обрабатываются;
- не делать лишние запросы.
Последним правилом нередко пренебрегают люди, только недавно начавшие заниматься продвижением по ключевым словам из семантического ядра. Излишне собирать статистику не стоит: это не только не даст продвижения сайта, но и разрушит всю затею на корню. Подходите к статистике грамотно. Тщательно и внимательно составляйте ее, и вы без труда найдете всю нужную информацию.
Первым шагом будет снять запросы с пустыми и лишними фразами
Также важно убрать такие элементы, как частотность в Wordstat на Яндекс, причем все, что есть. Для этого используют 4-ый метод скоростного сбора на Яндекс.Директ и Google Adwords
В последнем отображается информация о конкурентности запросов, также снятие сезонности у него шустрее, чем у Яндекса.С особым трепетом отнеситесь к пакетам статистики, их надо собирать с двойной осторожностью
- К таковым относят:
- пакетный сбор фраз из различных платформ;
- подсказки с применением перебора;
- статистика агрегаторов ссылок.
Причин такой осторожности достаточно. Зачастую информация из ядра собирается медленно, лимит на запросы маленький, а длится все это мучительно долго из-за большой кучи переходов
Это основные причины важности такой операции
Поэтому делом совести будет дать пару советов начинающему пользователю для наиболее успешного продвижения своего сайта:
- Перебирайте семантическое ядро вручную как можно меньше;
- Создавайте много групп;
- Работайте с ними по несколько сразу;
- Работайте с мультигруппами;
- Почаще применяйте фильтры.
- Удаляйте запросы со стоп-словами, а если без них не получается — сводите к минимуму.
Остальные настройки Кей Коллектора
Если ротация подключена, а вы полагаете, что ваши прокси приходят в негодность, то в соответствующей вкладке для Wordstat или для Яндекс.Директ подключите опцию «При ошибках получения запроса от сервиса удалять прокси-сервер», а после отметьте пункт, отличающийся от «Каждый раз снижать количество потоков при исключении…», если используются потоки. Тогда, при условии удаления из кучи низкосортных серверов хотя бы одного, ни один поток не прервется.Отрегулируйте настройку «Количество повторных попыток» в настройках парсинга (Вкладка «Общие») до 90. Опыт работы пользователей с большими проектами наталкивает на то, чтобы дать совет: в подобных проектах могут использоваться различные ключевые фразы, и естественно они подбираются пакетами
Если у вас такой проект, то обратите свое внимание на выбор функции «Не обновлять содержимое таблицы…» (вкладка «Прочее» в настройках программного интерфейса)
Не гнушайтесь ключевых слов по конкретному региону, сбором частотностей и сезонности, исходя из тематики сайта. Все это можно отыскать в соответствующих вкладках. Аналогично работа проходит при работе и с другими системами. Подробно можно прочесть в указанных разделах, в которых достаточно полно описаны все моменты касательно работы в каждом виде сбора информации.
Итог:
Программа Key Collector поможет выполнять работу посредством сбора информации. Ее легче легкого освоить любому пользователю, чтобы помочь обрабатывать большие и маленькие объемы запросов и улучшить распространение информации со своего сайта или сайта компании среди поисковиков.Применяйте программу Key Collector со всей ответственностью и аккуратностью. Только так ваша организация быстро продвинется среди прочих. Успехов в продвижении!
Купить программу можно тут: https://www.key-collector.ru/
Заказывайте профессиональное Seo продвижение и ведение контекстной рекламы и получите бесплатный проект развития вашего ресурса на год!
Что может Key Collector
Возможности программы просто поражают воображение. На выходе она дает не просто список ключей, а ключей:
- Из самых разных популярных источников (среди них – рекламные сервисы Yandex Wordstat, Google Ads, Rambler Adstat) и поисковых подсказок систем
- Вместе со статистикой из Liveinternet, Google Analytics, Яндекс.Метрики, Яндекс.Вебмастер, Serpstat и других сервисов
- С учетом конкретного региона и сезонности
- По нужной глубине поиска
- С оценками стоимости продвижения, популярности, конкуренции, трафика и других параметров
- Со значениями частотности
- С возможностью последующей группировки (кластеризации)
- С возможностью составления минус-списков.
Так выглядит интерфейс программы:
Далее мы отдельно рассмотрим весь функционал по блокам – как поможет вам Key Collector при сборе и анализе семантики, при группировке запросов и изучении конкурентов.
Что такое Key Collector?
Кей Коллектор – это платная утилита, которая повсеместно используется сеошниками и маркетологами. Суть ее состоит в почти полной автоматизации сбора семантического ядра. Приложение тесно интегрировано с Яндекс Директом, Вордстатом, гугловскими сервисами и прочими инструментами, которые поодиночке не выглядят такими практичными.
То есть Key Collector объединяет в себе несколько сервисов, интегрируя их возможности. Это позволяет людям легко и просто парсить запросы с того же Вордстата или Директа, в последствии превращая их во вполне себе обоснованное семантическое ядро.
Как я уже сказал, чтобы пользоваться программой, ее придется купить. Разработчики очень сильно заботятся о сохранении лицензии, поэтому каждая отдельная программа привязывается к одному персональному компьютеру с помощью идентификатора жесткого диска. Следовательно, вы не сможете скачать приложение, чтобы использовать его на нескольких машинах – 1 лицензия для 1 компьютера.
В интернете, конечно, есть взломанные версии, которые якобы предоставляют те же возможности, что и оригинал. Однако стоит учитывать, что через пиратское ПО очень часто распространяются вирусы
Если уж вы не хотите покупать Коллектор, то я бы рекомендовал вам обратить внимание на СловоЁб. Это бесплатное приложение от тех же разработчиков, которое представляет собой урезанный вариант Коллектора
Теперь давайте более подробно рассмотрим возможности программы. Итак, как заявляют разработчики, с помощью Key Collector мы сможем составить более точное семантическое ядро, не прибегая к помощи сторонних специалистов. Нам лишь нужно правильно настроить все параметры и познать некоторые азы.
Надо сказать, что Key Collector не работает с готовыми базами данных, которые требуют постоянные обновления. Он парсит всю информацию в реальном времени через интернет, подключаясь ко все тем же сервисам: Вордстат, Яндекс Директ, Гугл Адвордс и прочим. Такой подход гарантирует вам актуальность всех ключей, которые вы получите на выходе.
Эта программа поможет вам увидеть наиболее популярные страницы вашего сайта, определить верную стратегию продвижения, основываясь на статистических данных. В конечном итоге вы можете выгрузить всю информацию в удобный формат, например, в таблицу Excel.
Я уверен, что купить программу определенно стоит. Если понять, как работать, то это может сэкономить существенную часть финансов и времени. Да и проекты с качественной семантикой будут давать больше отдачи, что также является плюсом.
Быстрая работа с программой.
Чтобы работа с Key Collector была удобнее, в программе имеются функции, призванные эту работу облегчить. Это и горячие клавиши и контекстное меню, и даже колонки комментариев. Пример: для создания новой группы можно зажать Ctrl+T вместо кучи наведении мышью и кликов. А если нужно создать новую группу внутри текущей, то просто зажмите Ctrl+Shift+T.
Узнать о том или ином компоненте довольно удобно: просто нажмите на ячейку, и вы попадете в браузер, показывающий нужные сведения. Контекстное меню вам поможет с такими монотонными мелочами, как цветовые маркеры по фразам и группам, или быстрое копирование. Через соответствующие вкладки для ваших работ можно назначать цветные ярлыки и комментарии. Можно создать иерархию и привести группы в надлежащий вид: просто выберите нужные и перетащите.Кто-то может найти удобным возможность выгрузки нескольких групп в один файл. Для этого необходимо начать работу с несколькими группами. Разгрузку на разные листы лучше проделать, выполнив последовательность «Настройки — Интерфейс — Экспорт», выбрав формат электронных таблиц XLSX. Необходимые функции могут быть доступны быстро, если пользователь использует панель быстрого доступа.Для получения дополнительной информации вы можете нажать на вкладку «Инструкция».
Поиск конкурентов и их объявлений
И напоследок – фича сервиса, не связанная напрямую со сбором семантики, но полезная при создании рекламных объявлений. Вы можете посмотреть, кто ваши прямые конкуренты и какая у них реклама.
Выберите инструмент «Анализ SERP».
Нажмите «Получить все данные» – «Поиск конкурентов».
Появитсяокно с настройками, где вы указываете порог совпадений (входа в список конкурентов)
По умолчанию стоит 5 – то есть система считает рекламодателя вашим конкурентом, если его сайт появляется в выдаче по тем же ключевым фразам от 5 раз и выше.
После клика по кнопке «Искать» вы увидите список прямых конкурентов, ключевые слова, по которым у них настроена реклама.
Обратите особое внимание на тех рекламодателей, кто входит в Топ-10 выдачи нужной вам поисковой системы. Агрегаторы игнорируйте – они будут всегда по любому товарному запросу.
Теперь про объявления
Их можно собрать в Key Collector сразу по нескольким поисковым запросам, но в общем виде – без расширений. Для этого нажмите иконку «Сбор статистики Yandex.Direct» и активируйте галочку «Собирать информацию о конкурентах (объявления)».
Общая настройка Кей Коллектора
Для работы с вордстатом понадобиться: здесь все просто, нужно отдельно зарегистрировать яндекс почту и создать там тестовую рекламную кампанию, можно с одним объявлением, можно просто черновую (без прохождения модерации и пополнения бюджета). В программе просто прописываем логин и пароль от почты и все работает.
Для работы с гугл планером понадобиться: зарегистрировать новый аккаунт в гугл адвордс. В обязательном порядке скачать последнюю версию браузера internet explorer и зайдя исключительно через данный браузер, также создать тестовую рекламную кампанию (без бюджета и активности). Главное заполнить все настройки пользователя — указать язык и местоположение. Фокус заключается в том, что без данных манипуляций, использовать гугл планер не получиться.
Переходим непосредственно к настройкам:
Заходим в настройки программы во вкладку Яндекс Вордстат», где выставляем следующие параметры:
— глубина парсинга — 0. Выставляя такое значение, вы будите получать обычный парсинг, но программа может автоматом парсить и в глубину, т.е. спарсив ключевые слова, она может парсить то, что уже спарсила, разбивая ключевые слова на более конкретные ключевые слова. Смысла глубокого парсинга нет, так как система будет парсить дубли, а не уникальные ключевые слова, и даже без глубокого парсинга мы все равно будем по нему показываться, так как используем основную маску. Если просто — глубокий парсинг делать не надо, выставляем значение ноль.
— парсить страницы, здесь выставляем стандартное значение — 40.
— добавлять в таблицу фразы с частотами от 1 до 99999999999. Здесь вы указываете какую частотность вы хотите видеть с парсенных ключевых слов. Есть директологи, которые не парсят все доскональна, а работают с ключевыми словами, которые имеют частотность от 10 и выше. Я же советую вам парсить все и начинать с 1. При таком подходе у вас будет самое полное семантическое ядро, а если вы решите, что такие ключевые слова вам не нужно, то уже после парсинга, можно при помощи фильтра выделить такие ключи и удалить.
— не снимать частоты для фраз меньше или равной 0. Логика проста, нам не нужно пустые ключевые слова, которые не будут приносить трафик, поэтому такие не ищем.
— количество потоков. Если вы используете одну почту от яндекс директа, то можете смело выставлять сразу 2 потока, и таким образом программа будет работать в два раза быстрее. И если вы не используете прокси сервера, то не убираем галочку «Использовать основной IP адрес».
Далее заходим во вкладку «Яндекс Директ», где указываем адреса свои электронных почт от яндекса и пароли от них. Достаточно указать 1-2 почты.
Во вкладке «Гугл Адвордс» указываем доступы от гугл адвордс (что логично).
Собственно, это все стандартные настройки, после которых заработает кей коллектор.
Неявные дубли
Съем данных Гугл Адвордс полезен для быстрого сравнения и удаления менее частотных неявных дублей с перестановкой слов.
Для этого нужно настроить аккаунт Гугл в программе. Для вызова функции нажмите на иконку, как это показано на скриншоте:
После парсинга Адвордс перейдите во вкладку «Данные» в меню «Анализ неявных дублей».
- Чтобы оставить все многообразие словоформ, снимите галочку с пункта «Не учитывать словоформы при поиске неявных дублей». Если нужна только одна морфологическая словоформа, самая частотная, то, наоборот, поставьте галочку в чекбокс.
- Выберите, где искать дубли.
- Чтобы оставить одну и исключить случайное удаление фраз со снявшейся частотой, выберите такие же параметры, как на скриншоте выше.
- Нажмите кнопку «Выполнить поиск дублей повторно».
- Отметьте дубли с наименьшей частотностью с помощью кнопки «Умная отметка».
Таким образом все неявные дубли будут отмечены в таблице и их можно удалить.
Сбор частотностей
После получения данных из Вордстата или других источников нужно собрать частотности, чтобы оценить спрос. На его основе будем делать группировку и составлять ТЗ.
Для этого есть 2 основных варианта.
- Можно собирать частотности с помощью кнопки «Сбор частотности из сервиса Yandex Wordstat». Это медленный вариант, он подходит для сбора частотностей фраз состоящих из 8 слов и более. В других случаях используйте следующий вариант.
- Лучше всего собирать частотность с помощью Yandex Direct. Программа будет обрабатывать слова не по одному, а целой пачкой зараз.
При сборе частотностей Директ можно указать, какие снимать и за какой период.
- Рекомендуется снимать частотности за последние 30 дней, если это не сезонные запросы. При съеме за другой период могут получиться не совсем адекватные цифры – видимо, Яндекс не хранит точные данные за более длительные периоды или выдает их в округленном виде.
- Съем фраз разных частотностей можно разбить на 2 или 3 этапа. Например, сначала снять базовую частотность (если добавлены запросы из других источников), отфильтровать по частотности и удалить запросы ниже определенного порога. Далее снять частотность в кавычках, снова отфильтровать запросы с неподходящей частотой и удалить их. И только потом снять самую точную частотность. Таким образом, процесс съема будет дешевле и быстрее.
Заключение
Key Collector – сложная, многофункциональная утилита, которую вот так вот просто не освоить. Для более полного понимания чаще всего проходят специальное обучение. На курсах получают уроки по работе с семантикой и навыки по Кей Коллектору или аналогам. Поэтому сразу изучить эту программу полностью не получится.
Необходимый минимум в этой небольшой статье я вам дал. При помощи модуля Яндекс Вордстат вы сможете осуществлять съем семантического ядра, получать все виды частотностей и использовать это для составления крутых материалов. Имейте в виду, что сбор семантического ядра – работа тяжелая. Она требует серьезного подхода, и ни один инструмент не будет делать за вас абсолютно всю работу.
В случае с Кей Коллектором вам определенно придется покопаться с настройками. Многие пользователи изначально уделяют не так много времени этому, за что впоследствии расплачиваются неправильно составленной семантикой
Не совершайте ошибок, старайтесь уделить должное внимание настройкам и изучению особенностей работы этой утилиты
Если вы хотите разбираться не только в сборе семантического ядра, но еще и в создании крутых сайтов и их монетизации, я могу предложить вам пройти курс Василия Блинова “Как создать блог”. В нем будут рассмотрены все нюансы работы вебмастера, в том числе и такого аспекта, как сбор семантического ядра. По программе Key Collector вы тоже пройдетесь, получив более полные знания о работе в нем. Доступ на первый уровень предоставляется абсолютно бесплатно, поэтому не упустите свой шанс.