Javascript string split: how to split string in javascript
Содержание:
- Python F-Строки: Детали
- Строки байтов — bytes и bytearray
- Daemon потоки non-daemon
- СинтаксисSyntax
- ПараметрыSettings
- Split ( )
- Поиск в массиве
- Контроль доступа к ресурсам
- String Pool
- STRING_SPLIT and WHERE clause:
- preg_match()
- Как обрезать строку по символу
- Специфичные для потока данные
- Класс StringTokenizer
- Блокировки как менеджеры контекста
- ОПЕРАТОРЫ УНАРного и БИНАРного разделенияUNARY and BINARY SPLIT OPERATORS
- Заключение
Python F-Строки: Детали
На данный момент мы узнали почему f-строки так хороши, так что вам уже может быть интересно их попробовать в работе. Рассмотрим несколько деталей, которые нужно учитывать:
Кавычки
Вы можете использовать несколько типов кавычек внутри выражений. Убедитесь в том, что вы не используете один и тот же тип кавычек внутри и снаружи f-строки.
Этот код будет работать:
Python
print(f»{‘Eric Idle’}»)
# Вывод: ‘Eric Idle’
|
1 2 |
print(f»{‘Eric Idle’}») # Вывод: ‘Eric Idle’ |
И этот тоже:
Python
print(f'{«Eric Idle»}’)
# Вывод: ‘Eric Idle’
|
1 2 |
print(f'{«Eric Idle»}’) # Вывод: ‘Eric Idle’ |
Вы также можете использовать тройные кавычки:
Python
print(f»»»Eric Idle»»»)
# Вывод: ‘Eric Idle’
|
1 2 |
print(f»»»Eric Idle»»») # Вывод: ‘Eric Idle’ |
Python
print(f»’Eric Idle»’)
# Вывод: ‘Eric Idle’
|
1 2 |
print(f»’Eric Idle»’) # Вывод: ‘Eric Idle’ |
Если вам понадобиться использовать один и тот же тип кавычек внутри и снаружи строки, вам может помочь :
Python
print(f»The \»comedian\» is {name}, aged {age}.»)
# Вывод: ‘The «comedian» is Eric Idle, aged 74.’
|
1 2 |
print(f»The \»comedian\» is {name}, aged {age}.») # Вывод: ‘The «comedian» is Eric Idle, aged 74.’ |
Словари
Говоря о кавычках, будьте внимательны при работе со . Вы можете вставить значение словаря по его ключу, но сам ключ нужно вставлять в одиночные кавычки внутри f-строки. Сама же f-строка должна иметь двойные кавычки.
Вот так:
Python
comedian = {‘name’: ‘Eric Idle’, ‘age’: 74}
print(f»The comedian is {comedian}, aged {comedian}.»)
# Вывод: The comedian is Eric Idle, aged 74.
|
1 2 3 4 |
comedian={‘name»Eric Idle’,’age’74} print(f»The comedian is {comedian}, aged {comedian}.») # Вывод: The comedian is Eric Idle, aged 74. |
Обратите внимание на количество возможных проблем, если допустить ошибку в синтаксисе SyntaxError:
Python
>>> comedian = {‘name’: ‘Eric Idle’, ‘age’: 74}
>>> f’The comedian is {comedian}, aged {comedian}.’
File «<stdin>», line 1
f’The comedian is {comedian}, aged {comedian}.’
^
SyntaxError: invalid syntax
|
1 2 3 4 5 6 |
>>>comedian={‘name»Eric Idle’,’age’74} >>>f’The comedian is {comedian}, aged {comedian}.’ File»<stdin>»,line1 f’The comedian is {comedian}, aged {comedian}.’ ^ SyntaxErrorinvalid syntax |
Если вы используете одиночные кавычки в ключах словаря и снаружи f-строк, тогда кавычка в начале ключа словаря будет интерпретирован как конец строки.
Скобки
Чтобы скобки появились в вашей строке, вам нужно использовать двойные скобки:
Python
print(f»`74`»)
# Вывод: ‘{ 74 }’
|
1 2 3 |
print(f»`74`») |
Обратите внимание на то, что использование тройных скобок приведет к тому, что в строке будут только одинарные:
Python
print( f»{`74`}» )
# Вывод: ‘{ 74 }’
|
1 2 3 |
print(f»{`74`}») |
Однако, вы можете получить больше отображаемых скобок, если вы используете больше, чем три скобки:
Python
print(f»{{`74`}}»)
# Вывод: ‘`74`’
|
1 2 3 |
print(f»{{`74`}}») |
Бэкслеши
Как вы видели ранее, вы можете использовать бэкслеши в части строки f-string. Однако, вы не можете использовать бэкслеши в части выражения f-string:
Python
>>> f»{\»Eric Idle\»}»
File «<stdin>», line 1
f»{\»Eric Idle\»}»
^
SyntaxError: f-string expression part cannot include a backslash
|
1 2 3 4 5 |
>>>f»{\»Eric Idle\»}» File»<stdin>»,line1 f»{\»Eric Idle\»}» ^ SyntaxErrorf-stringexpression part cannot includeabackslash |
Вы можете проработать это, оценивая выражение заранее и используя результат в f-строк:
Python
name = «Eric Idle»
print(f»{name}»)
# Вывод: ‘Eric Idle’
|
1 2 3 4 |
name=»Eric Idle» print(f»{name}») |
Междустрочные комментарии
Выражения не должны включать комментарии с использованием символа #. В противном случае, у вас будет ошибка синтаксиса SyntaxError:
Python
>>> f»Eric is {2 * 37 #Oh my!}.»
File «<stdin>», line 1
f»Eric is {2 * 37 #Oh my!}.»
^
SyntaxError: f-string expression part cannot include ‘#’
|
1 2 3 4 5 |
>>>f»Eric is {2 * 37 #Oh my!}.» File»<stdin>»,line1 f»Eric is {2 * 37 #Oh my!}.» ^ SyntaxErrorf-stringexpression part cannot include’#’ |
Строки байтов — bytes и bytearray
Определение которое мы дале в самом начале можно считать верным только для строк типа str. Но в Python имеется еще два дугих типа строк: bytes – неизменяемое строковое представление двоичных данных и bytearray – тоже что и bytes, только допускает непосредственное изменение.
Основное отличие типа str от bytes и bytearray заключается в том, что str всегда пытается превратить последовательность байтов в текст указанной кодировки. По умолчанию этой кодировкой является utf-8, но это очень большая кодировка и другие кодировки, например ASCII, Latin-1 и другие являются ее подмножествами
Одни символы кодируются одним байтом, другие двумя, а некоторые тремя и функция при декодировании последовательности байтов принимает это во внимание. А вот функциям и до этого нет дела, для них абсолютно все данные состоят только из последовательности одиночных байтов.
Такое поведение bytes и bytearray очень удобно, если вы работаете с изображениями, аудиофайлами или сетевым трафиком. В этом случае, вам следует знать, что ничего магического в этих типах нет, они поддерживоют все теже строковые методы, операции индексирования, а так же операторы и функции для работы с последовательностями. Единственное, что следует держать в уме, так это то, что вы имеете дело с последовательностью байтов, т.е. последовательностью чисел из интервала в шестнадцатеричном представлении, и что байтовые строки отличаются от обычных символом (реже) предваряющим все литералы обычных строк.
Например, что бы создать строку типа bytes или bytearray достаточно передать соответствующим функциям последовательности целых чисел:
Учитывая то, что для кодирования некоторых символов (например ASCII) достаточно всего одного байта, данные типы пытаются представить последовательности в виде символов если это возможно. Например, строка будет выведена как :
А это значит, что байтовые данные могут вполне обоснованно интерпретированться как ASCII символы и наоборот. Т.е. строки байтов могут быть созданы и так:
Но, следует помнить что это все-таки байты, в чем легко убедиться, если мы обратимся к какому-нибудь символу по его индексу в строке:
Так как строковые методы не изменяют сам объект, а создают новый, то при работе с очень длинными строками (а в мире двоичных данных это далеко не редкость) это может привести к большому расходу памяти. Собственно, по этой причине и существует тип bytearray, который позволяет менять байты прямо внутри строки:
Daemon потоки non-daemon
До этого момента примеры программ ожидали, пока все потоки не завершат свою работу. Иногда программы порождают такой поток, как демон. Он работает, не блокируя завершение основной программы.
Использование демона полезно, если не удается прервать поток или завершить его в середине работы, не потеряв и не повредив при этом данные.
Чтобы пометить поток как demon, вызовите метод setDaemon() с логическим аргументом. По умолчанию потоки не являются «демонами», поэтому передача в качестве аргумента значения True включает режим demon.
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def daemon():
logging.debug('Starting')
time.sleep(2)
logging.debug('Exiting')
d = threading.Thread(name='daemon', target=daemon)
d.setDaemon(True)
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
Обратите внимание, что в выводимых данных отсутствует сообщение «Exiting» от потока-демона. Все потоки, не являющиеся «демонами» (включая основной поток), завершают работу до того, как поток-демон выйдет из двухсекундного сна
$ python threading_daemon.py (daemon ) Starting (non-daemon) Starting (non-daemon) Exiting
Чтобы дождаться завершения работы потока-демона, используйте метод join().
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def daemon():
logging.debug('Starting')
time.sleep(2)
logging.debug('Exiting')
d = threading.Thread(name='daemon', target=daemon)
d.setDaemon(True)
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
d.join()
t.join()
Метод join() позволяет demon вывести сообщение «Exiting».
$ python threading_daemon_join.py (daemon ) Starting (non-daemon) Starting (non-daemon) Exiting (daemon ) Exiting
Также можно передать аргумент задержки (количество секунд, в течение которых поток будет неактивным).
import threading
import time
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def daemon():
logging.debug('Starting')
time.sleep(2)
logging.debug('Exiting')
d = threading.Thread(name='daemon', target=daemon)
d.setDaemon(True)
def non_daemon():
logging.debug('Starting')
logging.debug('Exiting')
t = threading.Thread(name='non-daemon', target=non_daemon)
d.start()
t.start()
d.join(1)
print 'd.isAlive()', d.isAlive()
t.join()
Истекшее время ожидания меньше, чем время, в течение которого поток-демон спит. Поэтому поток все еще «жив» после того, как метод join() продолжит свою работу.
$ python threading_daemon_join_timeout.py (daemon ) Starting (non-daemon) Starting (non-daemon) Exiting d.isAlive() True
СинтаксисSyntax
Split(выражение, ])Split(expression, ]])
Синтаксис функции Split включает следующие :The Split function syntax has these :
| ЧастьPart | ОписаниеDescription |
|---|---|
| выражениеexpression | Обязательная часть.Required. , содержащее подстроки и разделители. containing substrings and delimiters. Если аргумент expression является строкой нулевой длины («»), функция Split возвращает пустой массив — без элементов и данных.If expression is a zero-length string(«»), Split returns an empty array, that is, an array with no elements and no data. |
| delimiterdelimiter | Необязательное свойство.Optional. Строковый символ, используемый для разделения подстрок.String character used to identify substring limits. Если этот аргумент не указан, в качестве разделителя используется знак пробела (» «).If omitted, the space character (» «) is assumed to be the delimiter. Если аргумент delimiter является строкой нулевой длины, возвращается массив с одним элементом, содержащим всю строку из аргумента expression.If delimiter is a zero-length string, a single-element array containing the entire expression string is returned. |
| ограничениеlimit | Необязательное свойство.Optional. Количество возвращаемого подстройки; -1 указывает, что возвращаются все подстройки.Number of substrings to be returned; -1 indicates that all substrings are returned. |
| comparecompare | Необязательно.Optional. Представляет собой числовое значение, указывающее вид сравнения, которое выполняется при оценке подстрок.Numeric value indicating the kind of comparison to use when evaluating substrings. Значения см. в разделе «Параметры».See Settings section for values. |
ПараметрыSettings
Аргумент compare может принимать следующие значения:The compare argument can have the following values:
| КонстантаConstant | ЗначениеValue | ОписаниеDescription |
|---|---|---|
| vbUseCompareOptionvbUseCompareOption | –1-1 | Выполняет сравнение, используя параметр оператора Option Compare.Performs a comparison by using the setting of the Option Compare statement. |
| vbBinaryComparevbBinaryCompare | Выполняется двоичное сравнение.Performs a binary comparison. | |
| vbTextComparevbTextCompare | 11 | Выполняется текстовое сравнение.Performs a textual comparison. |
| vbDatabaseComparevbDatabaseCompare | 22 | Только Microsoft Access.Microsoft Access only. Выполняется сравнение на основе сведений из базы данных.Performs a comparison based on information in your database. |
Split ( )
Методы Slice( ) и splice( ) используются для массивов. Метод split( )используется для строк. Он разделяет строку на подстроки и возвращает их в виде массива. У этого метода 2 параметра, и оба из них не обязательно указывать.
string.split(separator, limit);
- Separator: определяет, как строка будет поделена на подстроки: запятой, знаком и т.д.
- Limit: ограничивает количество подстрок заданным числом
Метод split( ) не работает напрямую с массивами. Тем не менее, сначала можно преобразовать элементы массива в строки и уже после применить метод split( ).
Давайте посмотрим, как это работает.
Сначала преобразуем массив в строку с помощью метода toString( ):
let myString = array.toString();
Затем разделим строку myString запятыми и ограничим количество подстрок до трех. Затем преобразуем строки в массив:
let newArray = myString.split(",", 3);
В виде массива вернулись первые 3 элемента
Таким образом, элементы массива myString разделены запятыми. Мы поставили ограничение в 3 подстроки, поэтому в качестве массива вернулись первые 3 элемента.
Все символы разделены на подстроки
Поиск в массиве
Далее рассмотрим методы, которые помогут найти что-нибудь в массиве.
Методы arr.indexOf, arr.lastIndexOf и arr.includes имеют одинаковый синтаксис и делают по сути то же самое, что и их строковые аналоги, но работают с элементами вместо символов:
- ищет , начиная с индекса , и возвращает индекс, на котором был найден искомый элемент, в противном случае .
- – то же самое, но ищет справа налево.
- – ищет , начиная с индекса , и возвращает , если поиск успешен.
Например:
Обратите внимание, что методы используют строгое сравнение. Таким образом, если мы ищем , он находит именно , а не ноль
Если мы хотим проверить наличие элемента, и нет необходимости знать его точный индекс, тогда предпочтительным является .
Кроме того, очень незначительным отличием является то, что он правильно обрабатывает в отличие от :
Представьте, что у нас есть массив объектов. Как нам найти объект с определённым условием?
Здесь пригодится метод arr.find.
Его синтаксис таков:
Функция вызывается по очереди для каждого элемента массива:
- – очередной элемент.
- – его индекс.
- – сам массив.
Если функция возвращает , поиск прерывается и возвращается . Если ничего не найдено, возвращается .
Например, у нас есть массив пользователей, каждый из которых имеет поля и . Попробуем найти того, кто с :
В реальной жизни массивы объектов – обычное дело, поэтому метод крайне полезен.
Обратите внимание, что в данном примере мы передаём функцию , с одним аргументом. Это типично, дополнительные аргументы этой функции используются редко
Метод arr.findIndex – по сути, то же самое, но возвращает индекс, на котором был найден элемент, а не сам элемент, и , если ничего не найдено.
Метод ищет один (первый попавшийся) элемент, на котором функция-колбэк вернёт .
На тот случай, если найденных элементов может быть много, предусмотрен метод arr.filter(fn).
Синтаксис этого метода схож с , но возвращает массив из всех подходящих элементов:
Например:
Контроль доступа к ресурсам
Помимо синхронизации операций с потоками, также важно иметь возможность контролировать доступ к общим ресурсам, чтобы предотвратить повреждение данных. Встроенные в Python структуры данных (списки, словари и т
д.) являются поточно-ориентированными. Другие структуры данных, реализованные в Python, и более простые типы (целые числа и числа с плавающей запятой) имеют такой защиты. Для защиты от одновременного доступа к объекту используйте объект Lock
Встроенные в Python структуры данных (списки, словари и т. д.) являются поточно-ориентированными. Другие структуры данных, реализованные в Python, и более простые типы (целые числа и числа с плавающей запятой) имеют такой защиты. Для защиты от одновременного доступа к объекту используйте объект Lock.
import logging
import random
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
class Counter(object):
def __init__(self, start=0):
self.lock = threading.Lock()
self.value = start
def increment(self):
logging.debug('Waiting for lock')
self.lock.acquire()
try:
logging.debug('Acquired lock')
self.value = self.value + 1
finally:
self.lock.release()
def worker(c):
for i in range(2):
pause = random.random()
logging.debug('Sleeping %0.02f', pause)
time.sleep(pause)
c.increment()
logging.debug('Done')
counter = Counter()
for i in range(2):
t = threading.Thread(target=worker, args=(counter,))
t.start()
logging.debug('Waiting for worker threads')
main_thread = threading.currentThread()
for t in threading.enumerate():
if t is not main_thread:
t.join()
logging.debug('Counter: %d', counter.value)
В этом примере функция worker() увеличивает экземпляр Counter, который управляет Lock, чтобы два потока не могли одновременно изменить свое внутреннее состояние. Если Lock не использовался, можно пропустить изменение значения атрибута.
$ python threading_lock.py (Thread-1 ) Sleeping 0.47 (Thread-2 ) Sleeping 0.65 (MainThread) Waiting for worker threads (Thread-1 ) Waiting for lock (Thread-1 ) Acquired lock (Thread-1 ) Sleeping 0.90 (Thread-2 ) Waiting for lock (Thread-2 ) Acquired lock (Thread-2 ) Sleeping 0.11 (Thread-2 ) Waiting for lock (Thread-2 ) Acquired lock (Thread-2 ) Done (Thread-1 ) Waiting for lock (Thread-1 ) Acquired lock (Thread-1 ) Done (MainThread) Counter: 4
Чтобы выяснить, применил ли другой поток блокировку, не задерживая текущий поток, передайте значение False аргументу blocking функции acquire().
В следующем примере worker() пытается применить блокировку три раза и подсчитывает, сколько попыток нужно сделать. А lock_holder() выполняет циклическое переключение между снятием и запуском блокировки с короткими паузами в каждом состоянии, используемом для имитации загрузки.
import logging
import threading
import time
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def lock_holder(lock):
logging.debug('Starting')
while True:
lock.acquire()
try:
logging.debug('Holding')
time.sleep(0.5)
finally:
logging.debug('Not holding')
lock.release()
time.sleep(0.5)
return
def worker(lock):
logging.debug('Starting')
num_tries = 0
num_acquires = 0
while num_acquires < 3:
time.sleep(0.5)
logging.debug('Trying to acquire')
have_it = lock.acquire(0)
try:
num_tries += 1
if have_it:
logging.debug('Iteration %d: Acquired', num_tries)
num_acquires += 1
else:
logging.debug('Iteration %d: Not acquired', num_tries)
finally:
if have_it:
lock.release()
logging.debug('Done after %d iterations', num_tries)
lock = threading.Lock()
holder = threading.Thread(target=lock_holder, args=(lock,), name='LockHolder')
holder.setDaemon(True)
holder.start()
worker = threading.Thread(target=worker, args=(lock,), name='Worker')
worker.start()
worker() требуется более трех итераций, чтобы применить блокировку три раза.
$ python threading_lock_noblock.py (LockHolder) Starting (LockHolder) Holding (Worker ) Starting (LockHolder) Not holding (Worker ) Trying to acquire (Worker ) Iteration 1: Acquired (Worker ) Trying to acquire (LockHolder) Holding (Worker ) Iteration 2: Not acquired (LockHolder) Not holding (Worker ) Trying to acquire (Worker ) Iteration 3: Acquired (LockHolder) Holding (Worker ) Trying to acquire (Worker ) Iteration 4: Not acquired (LockHolder) Not holding (Worker ) Trying to acquire (Worker ) Iteration 5: Acquired (Worker ) Done after 5 iterations
String Pool
Все строки, которые были заданы в коде в , во время работы программы хранятся в памяти в так называемом . — это специальный массив для хранения строк. Цель его создания — оптимизация хранения строк:
Во-первых, строки, заданные в коде, нужно все-таки где-то хранить. Код — это команды, а данные (тем более такие большие как строки) нужно хранить в памяти отдельно от кода. В коде фигурируют только ссылки на объекты-строки.
Во-вторых, все одинаковые литералы можно хранить в памяти только один раз. Так оно и работает. Когда код вашего класса загружается Java-машиной, все строковые литералы добавляются в , если их там еще нет. Если уже есть, просто используется ссылка на строку из .
Поэтому если в своем коде вы присвоите нескольким -переменным одинаковые литералы, переменные будут содержать одинаковые ссылки. В литерал будет добавлен только один раз, во всех остальных случаях будет браться ссылка на уже загруженную в строку.
Как это примерно работает:
| Код | Работа с StringPool |
|---|---|
Именно поэтому переменные и будут хранить одинаковые ссылки.
Метод
Ну и самое интересное: вы можете программно добавить любую строку в . Для этого нужно просто вызвать метод у -переменной.
Метод добавит строку в , если ее еще там нет, и вернет ссылку на строку из .
| Код | Примечание |
|---|---|
Вряд ли вы будете часто пользоваться этим методом, однако о нем любят спрашивать на собеседованиях, поэтому лучше о нем знать, чем не знать.
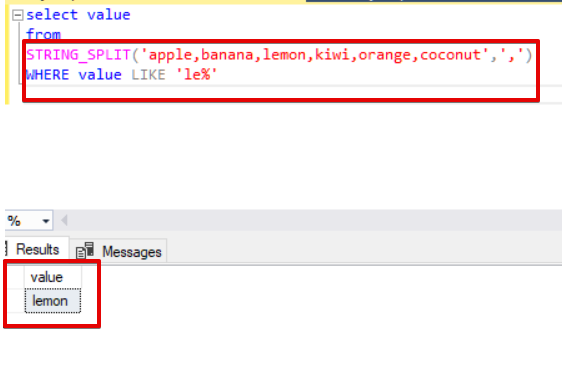
STRING_SPLIT and WHERE clause:
Through the WHERE clause, we can filter the result set of the STRING_SPLIT function. In the following select statement, the WHERE clause will filter the result set of the function and will only return the row or rows which start with “le”
|
1 |
selectvalue from STRING_SPLIT(‘apple,banana,lemon,kiwi,orange,coconut’,’,’) WHEREvalueLIKE’le%’ |
Also, we can use the function in this form:
|
1 |
USEAdventureWorks2014 GO select*fromHumanResources.Employee WHEREjobtitleIN (selectvaluefromstring_split(‘Chief Executive Officer , Design Engineer’,’,’)) |

Now, we will look at the execution plan with help of ApexSQL Plan. We can see the Table valued function operator in the execution plan.

When we hover over the table-valued function operator in the execution plan, we can find out all the details about this operator. Under the object label, the STRING_SPLIT function can be seen. These all details tell us that this function is a table-valued function.

preg_match()
Вы редко найдете тех, кто предпочитает использовать регулярные выражения, когда есть так много отличных функций PHP. Тем не менее, вот функция, которая обрезает строку до определенного символа в PHP, исходя из заданного количества знаков от начала. В отличие от других функций, описанных выше, эта функция обрезает строку до целого слова.
/* preg-match() http://php.net/manual/en/function.preg-match.php */ function internoetics_preg_string($string, $length, $trimmarker = '...') { $strlen = strlen($string); /* mb_substr добавляет принудительный разрыв в $length, если заданное количество символов не содержит окончания слова (пробела) */ $string = trim(mb_substr($string, 0, $strlen)); if ($strlen > $length) { preg_match('/^.{1,' . ($length - strlen($trimmarker)) . '}b/su', $string, $match); $string = trim($match) . $trimmarker; } else { $string = trim($string); } return $string; } /* Применение */ echo internoetics_preg_string($string, 100, $trimmarker = '...');
Описание функции
Функция принимает три параметра: $string, $length и $trimmarker (многоточие или другие символы, которые добавляются в конце строки).
Строка 7
$strlen = strlen($string);
Первое, что мы делаем, это проверяем длину PHP обрезанной строки после символа. Если строка короче, чем $length, то мы возвращаем эту строку.
Строка 9
$string = trim(mb_substr($string, 0, $strlen));
Функция mb_substr() прерывает строку в $length, если это количество символов не содержит окончания слова (пробела). Если мы передали строку длиною 500 символов и эта строка не содержит пробелов, то будет возвращена вся строка (так как функция preg_match не нашла окончания слова). На данный момент мы обрезаем строку таким образом, и возвращаем ее полностью.
Строки 10, 11, и 12
Если длина нашей строки превышает максимальную длину, определенную в качестве параметра функции, мы выполняем регулярное выражение функции preg_match(), чтобы вернуть часть строки до символа с номером $length, который определяется как конец слова (‘/^.{1,$length}b/s’). Знак периода означает любой символ, кроме символа новой строки (n). Фигурная скобка определяет диапазон, который задает, сколько символов должен PHP обрезать в строке. Таким образом {1,$length} означает от 1 до символа $length. Наконец, b означает, что шаблон будет соответствовать окончанию слова. Мы можем производить поиск только слов целиком по шаблону, который мы предоставили. И в конце s задает поиск всех пробелов.
Так как мы не хотим, чтобы возвращаемая строка превышала длину $length, максимальное количество символов в функции preg_match должно быть равно максимальной длине минус длина $trimmarke.r. Мы должны учитывать это.
Затем мы возвращаем либо усеченную строку, либо исходную строку, если она меньше заданной длины усечения.
Как обрезать строку по символу
- -> разбираемся в тезисе
- -> explode
- ->показать слева
- ->показать справа
- ->показать слева
- ->показать справа
- Скачать
PHP Обрезать строку по символу можно по разному….
Обрезать строку по символу в php -> можно понять, как -> что у нас есть в строке определенный заранее известный символ, и вот по нему и нужно обрезать строку! Будем использовать explode
Обрезать строку по символу в php -> есть вообще строка… любая и нам требуется отсчитать некое количество символов и вот поэтому количеству символов и обрезать строку!
Мы уже говорили об этой функции explode — сейчас будет использовать её для обрезки строки по символу!
Нам потребуется для иллюстрации обрезки строки по символу какая-то произвольная строка с каким-то наполнением:$string = «12345678910|10987654321»;
Для примера, возьмем символ, который расположен примерно посередине -> «|», создаем такую запись :
$new_array = explode(«|» , $string);
Если нам потребуется первая часть, то используем current: echo current($new_array);
Результат:
12345678910
Если вам потребуется вторая часть, то используем end. Здесь нужно дополнение — если символ 1, то end будет показывать второй элемент, если символ в строке повторяется несколько раз, то end покажет последнюю ячейку массива
В данном случае разделительный элемент сроки я единственном числе, поэтому нам предстанет вторая часть:
echo end($new_array);
Результат:
10987654321
Прежде чем продолжать нам потребуются какие-то условия, например, нам нужно обрезать строку по 5 символу, здесь число не важно, и нам опять…
понадобится строка :
$string = «12345678910|10987654321»;
Поскольку и дальше будем использовать это число для обрезки по символу, то присвоим это значение произвольной переменной: $num_elem = 5;
Длаее нам понадобится функция substr и вот такая конструкция:
$first = substr($string , 0, $num_elem);
Далее выводим с помощью echo
echo $first;
Результат:
12345
Можете посчитать … строка обрезана по 5 символу!И показана строка с начала!
Но, что если нам требуется обрезать строку по символу с начала и удалить эту часть оставив только часть справа…
Как мы уже сказали выше, что если нам требуется обрезать строку сначала по символу и выкинуть эту часть, отставив строку с конца..
если вы не обратили внимание на строку
то рекомендую сейчас на неё внимательность посмотреть и на первый результат тоже…
Опять брем всю ту же строку…:
$string = «12345678910|10987654321»;
Пишем такую конструкцию:
echo substr($string , 5 );
Результат:
678910|10987654321
Теперь предположим
что нам требуется обрезать строку по символу с конца и показать левую часть, выкинув обрезанную часть:
echo substr($string , 0, — 5 ); ?>
Результат:
12345678910|109876
Опять обрезаем строку справа, и эту часть обрезанной строки и покажем:
Обрезать строку по символу № 5 с конца строки — показать правую часть:
echo substr($string , — 5 ); ?>
Результат:
54321
Последняя дата редактирования : 27.02.2021 14:23
Название скрипта :Обрезать строку по символу.
Скрипт № 33.13Ссылка на скачивание : Все скрипты на
//dwweb.ru/comments_1_5/include/img/hand_no_foto.png
no
no
Специфичные для потока данные
Некоторые ресурсы должны быть заблокированы, чтобы их могли использовать сразу несколько потоков. А другие должны быть защищены от просмотра в потоках, которые не «владеют» ими. Функция local() создает объект, способный скрывать значения для отдельных потоков.
import random
import threading
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def show_value(data):
try:
val = data.value
except AttributeError:
logging.debug('No value yet')
else:
logging.debug('value=%s', val)
def worker(data):
show_value(data)
data.value = random.randint(1, 100)
show_value(data)
local_data = threading.local()
show_value(local_data)
local_data.value = 1000
show_value(local_data)
for i in range(2):
t = threading.Thread(target=worker, args=(local_data,))
t.start()
Обратите внимание, что значение local_data.value не доступно ни для одного потока, пока не будет установлено
$ python threading_local.py (MainThread) No value yet (MainThread) value=1000 (Thread-1 ) No value yet (Thread-1 ) value=34 (Thread-2 ) No value yet (Thread-2 ) value=7
Чтобы все потоки начинались с одного и того же значения, используйте подкласс и установите атрибуты с помощью метода __init __() .
import random
import threading
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def show_value(data):
try:
val = data.value
except AttributeError:
logging.debug('No value yet')
else:
logging.debug('value=%s', val)
def worker(data):
show_value(data)
data.value = random.randint(1, 100)
show_value(data)
class MyLocal(threading.local):
def __init__(self, value):
logging.debug('Initializing %r', self)
self.value = value
local_data = MyLocal(1000)
show_value(local_data)
for i in range(2):
t = threading.Thread(target=worker, args=(local_data,))
t.start()
__init __() вызывается для каждого объекта (обратите внимание на значение id()) один раз в каждом потоке
$ python threading_local_defaults.py (MainThread) Initializing <__main__.MyLocal object at 0x100514390> (MainThread) value=1000 (Thread-1 ) Initializing <__main__.MyLocal object at 0x100514390> (Thread-1 ) value=1000 (Thread-2 ) Initializing <__main__.MyLocal object at 0x100514390> (Thread-1 ) value=81 (Thread-2 ) value=1000 (Thread-2 ) value=54
Данная публикация является переводом статьи «threading – Manage concurrent threads» , подготовленная редакцией проекта.
Класс StringTokenizer
И еще несколько самых частых сценариев работы со строками. Как разбить строку на несколько частей? Для этого есть несколько способов.
Метод
Первый способ разбить строку на несколько частей — использовать метод . В него в качестве параметра нужно передать регулярное выражение: специальный шаблон строки-разделителя. Что такое регулярное выражение, вы узнаете в квесте Java Multithreading.
Пример:
| Код | Результат |
|---|---|
| Результатом будет массив из трех строк: |
Просто, но иногда такой подход избыточен. Если разделителей много, например, «пробел», «enter», «таб», «точка», приходится конструировать достаточно сложное регулярное выражение. Его сложно читать, а значит, в него сложно вносить изменения.
Класс
В Java есть специальный класс, вся работа которого — разделять строку на подстроки.
Этот класс не использует регулярные выражения: вместо этого в него просто передается строка, состоящая из символов-разделителей. Преимущества этого подхода в том, что он не разбивает сразу всю строку на кусочки, а потихоньку идет от начала к концу.
Класс состоит из конструктора и двух методов. В конструктор нужно передать строку, которую мы разбиваем на части, и строку — набор символов, используемых для разделения.
| Методы | Описание |
|---|---|
| Возвращает следующую подстроку | |
| Проверяет, есть ли еще подстроки. |
Этот класс чем-то напоминает класс , у которого тоже были методы и .
Создать объект можно командой:
Где строка — это , которую будем делить на части. А — это строка, каждый символ которой считается символом-разделителем. Пример:
| Код | Вывод на экран |
|---|---|
Обратите внимание, что разделителем считается каждый символ строки, переданный второй строкой в конструктор
Блокировки как менеджеры контекста
Блокировки реализуют API context manager и совместимы с оператором with. Использование оператора with позволяет обойтись без блокировки.
import threading
import logging
logging.basicConfig(level=logging.DEBUG,
format='(%(threadName)-10s) %(message)s',
)
def worker_with(lock):
with lock:
logging.debug('Lock acquired via with')
def worker_no_with(lock):
lock.acquire()
try:
logging.debug('Lock acquired directly')
finally:
lock.release()
lock = threading.Lock()
w = threading.Thread(target=worker_with, args=(lock,))
nw = threading.Thread(target=worker_no_with, args=(lock,))
w.start()
nw.start()
Функции worker_with() и worker_no_with() управляют блокировкой эквивалентными способами.
$ python threading_lock_with.py (Thread-1 ) Lock acquired via with (Thread-2 ) Lock acquired directly
ОПЕРАТОРЫ УНАРного и БИНАРного разделенияUNARY and BINARY SPLIT OPERATORS
Оператор унарного разбиения ( ) имеет более высокий приоритет, чем запятая.The unary split operator () has higher precedence than a comma. В результате, если отправить разделенный запятыми список строк в оператор унарного разбиения, то разбиение выполняется только на первую строку (перед первой запятой).As a result, if you submit a comma-separated list of strings to the unary split operator, only the first string (before the first comma) is split.
Чтобы разделить более одной строки, используйте один из следующих шаблонов:Use one of the following patterns to split more than one string:
- Использование оператора двоичного разделения ( <string[]> -Split <delimiter> )Use the binary split operator (<string[]> -split <delimiter>)
- Заключите все строки в круглые скобкиEnclose all the strings in parentheses
- Сохранить строки в переменной, а затем отправить переменную оператору SplitStore the strings in a variable then submit the variable to the split operator
Рассмотрим следующий пример.Consider the following example:
Заключение
Мы могли бы написать еще сотни примеров PHP обрезки строк, но когда-то нужно остановиться. Функции, приведенные в этой статье, являются частью ядра PHP, и вы можете использовать их для усечения строк. Хотя чаще всего программисты стараются избегать регулярных выражений, если другого выхода нет, вы можете прибегнуть и к их помощи.
В ряде примеров мы вернули $trimmarker, представляющий собой многоточие. При необходимости вы можете вернуть HTML-объект Ellipsis, для этого используется код …. Но лично я предпочитаю многоточие.
Скачать примеры
Скачать примеры из этой статьи вы можете здесь.
Данная публикация является переводом статьи «Truncate (Shorten) Strings to the Nearest Whole Word or Character Count with Trailing Dots using PHP Functions» , подготовленная редакцией проекта.







