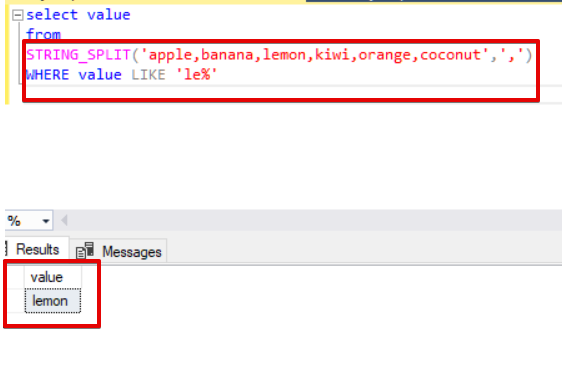
Javascript метод substring()
Содержание:
Строковые методы, поиск и замена
Следующие методы работают с регулярными выражениями из строк.
Все методы, кроме replace, можно вызывать как с объектами типа regexp в аргументах, так и со строками, которые автоматом преобразуются в объекты RegExp.
Так что вызовы эквивалентны:
var i = str.search(/\s/)
var i = str.search("\\s")
При использовании кавычек нужно дублировать \ и нет возможности указать флаги. Если регулярное выражение уже задано строкой, то бывает удобна и полная форма
var regText = "\\s" var i = str.search(new RegExp(regText, "g"))
Возвращает индекс регулярного выражения в строке, или -1.
Если Вы хотите знать, подходит ли строка под регулярное выражение, используйте метод (аналогично RegExp-методы ). Чтобы получить больше информации, используйте более медленный метод (аналогичный методу ).
Этот пример выводит сообщение, в зависимости от того, подходит ли строка под регулярное выражение.
function testinput(re, str){
if (str.search(re) != -1)
midstring = " contains ";
else
midstring = " does not contain ";
document.write (str + midstring + re.source);
}
Если в regexp нет флага , то возвращает тот же результат, что .
Если в regexp есть флаг , то возвращает массив со всеми совпадениями.
Чтобы просто узнать, подходит ли строка под регулярное выражение , используйте .
Если Вы хотите получить первый результат — попробуйте r.
В следующем примере используется, чтобы найти «Chapter», за которой следует 1 или более цифр, а затем цифры, разделенные точкой. В регулярном выражении есть флаг , так что регистр будет игнорироваться.
str = "For more information, see Chapter 3.4.5.1"; re = /chapter (\d+(\.\d)*)/i; found = str.match(re); alert(found);
Скрипт выдаст массив из совпадений:
- Chapter 3.4.5.1 — полностью совпавшая строка
- 3.4.5.1 — первая скобка
- .1 — внутренняя скобка
Следующий пример демонстрирует использование флагов глобального и регистронезависимого поиска с . Будут найдены все буквы от А до Е и от а до е, каждая — в отдельном элементе массива.
var str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; var regexp = //gi; var matches = str.match(regexp); document.write(matches); // matches =
Метод replace может заменять вхождения регулярного выражения не только на строку, но и на результат выполнения функции. Его полный синтаксис — такой:
var newString = str.replace(regexp/substr, newSubStr/function)
- Объект RegExp. Его вхождения будут заменены на значение, которое вернет параметр номер 2
- Строка, которая будет заменена на .
- Строка, которая заменяет подстроку из аргумента номер 1.
- Функция, которая может быть вызвана для генерации новой подстроки (чтобы подставить ее вместо подстроки, полученной из аргумента 1).
Метод не меняет строку, на которой вызван, а просто возвращает новую, измененную строку.
Чтобы осуществить глобальную замену, включите в регулярное выражение флаг .
Если первый аргумент — строка, то она не преобразуется в регулярное выражение, так что, например,
var ab = "a b".replace("\\s","..") // = "a b"
Вызов replace оставил строку без изменения, т.к искал не регулярное выражение , а строку «\s».
В строке замены могут быть такие спецсимволы:
| Pattern | Inserts |
| Вставляет «$». | |
| Вставляет найденную подстроку. | |
| Вставляет часть строки, которая предшествует найденному вхождению. | |
| Вставляет часть строки, которая идет после найденного вхождения. | |
| or | Где или — десятичные цифры, вставляет подстроку вхождения, запомненную -й вложенной скобкой, если первый аргумент — объект RegExp. |
Если Вы указываете вторым параметром функцию, то она выполняется при каждом совпадении.
В функции можно динамически генерировать и возвращать строку подстановки.
Первый параметр функции — найденная подстрока. Если первым аргументом является объект , то следующие параметров содержат совпадения из вложенных скобок. Последние два параметра — позиция в строке, на которой произошло совпадение и сама строка.
Например, следующий вызов возвратит XXzzzz — XX , zzzz.
function replacer(str, p1, p2, offset, s)
{
return str + " - " + p1 + " , " + p2;
}
var newString = "XXzzzz".replace(/(X*)(z*)/, replacer)
Как видите, тут две скобки в регулярном выражении, и потому в функции два параметра , .
Если бы были три скобки, то в функцию пришлось бы добавить параметр .
Следующая функция заменяет слова типа на :
function styleHyphenFormat(propertyName)
{
function upperToHyphenLower(match)
{
return '-' + match.toLowerCase();
}
return propertyName.replace(//, upperToHyphenLower);
}
Строки могут быть объектами
Обычно строки JavaScript являются примитивными значениями, созданными из литералов:
Но строки также могут быть определены как объекты с ключевым словом :
Пример
var x = «John»;
var y = new String(«John»);
// typeof x вернёт строку// typeof y вернёт объект
Не создавайте строки как объекты. Это замедляет скорость выполнения.
Ключевое слово усложняет код. Это может привести к неожиданным результатам:
При использовании оператора одинаковые строки равны:
Пример
var x = «John»;
var y = new String(«John»);
// (x == y) верно, потому что х и у имеют равные значения
При использовании оператора одинаковые строки не равны, поскольку оператор ожидает равенства как по типу, так и по значению.
Пример
var x = «John»;
var y = new String(«John»);
// (x === y) является false (неверно), потому что x и y имеют разные типы (строка и объект)
Или даже хуже. Объекты нельзя сравнивать:
Пример
var x = new String(«John»);
var y = new String(«John»);
// (x == y) является false (неверно), потому что х и у разные объекты
Пример
var x = new String(«John»);
var y = new String(«John»);
// (x === y) является false (неверно), потому что х и у разные объекты
Обратите внимание на разницу между и .Сравнение двух JavaScript объектов будет всегда возвращать
Улучшена поддержка юникода
Внутренняя кодировка строк в JavaScript – это UTF-16, то есть под каждый символ отводится ровно два байта.
Но под всевозможные символы всех языков мира 2 байт не хватает. Поэтому бывает так, что одному символу языка соответствует два юникодных символа (итого 4 байта). Такое сочетание называют «суррогатной парой».
Самый частый пример суррогатной пары, который можно встретить в литературе – это китайские иероглифы.
Заметим, однако, что не всякий китайский иероглиф – суррогатная пара. Существенная часть «основного» юникод-диапазона как раз отдана под китайский язык, поэтому некоторые иероглифы – которые в неё «влезли» – представляются одним юникод-символом, а те, которые не поместились (реже используемые) – двумя.
Например:
В тексте выше для первого иероглифа есть отдельный юникод-символ, и поэтому длина строки , а для второго используется суррогатная пара. Соответственно, длина – .
Китайскими иероглифами суррогатные пары, естественно, не ограничиваются.
Ими представлены редкие математические символы, а также некоторые символы для эмоций, к примеру:
В современный JavaScript добавлены методы String.fromCodePoint и str.codePointAt – аналоги и , корректно работающие с суррогатными парами.
Например, считает суррогатную пару двумя разными символами и возвращает код каждой:
…В то время как возвращает его Unicode-код суррогатной пары правильно:
Метод корректно создаёт строку из «длинного кода», в отличие от старого .
Например:
Более старый метод в последней строке дал неверный результат, так как он берёт только первые два байта от числа и создаёт символ из них, а остальные отбрасывает.
Есть и ещё синтаксическое улучшение для больших Unicode-кодов.
В JavaScript-строках давно можно вставлять символы по Unicode-коду, вот так:
Синтаксис: , где – четырёхзначный шестнадцатиричный код, причём он должен быть ровно четырёхзначным.
«Лишние» цифры уже не войдут в код, например:
Чтобы вводить более длинные коды символов, добавили запись , где – максимально восьмизначный (но можно и меньше цифр) код.
Например:
Во многих языках есть символы, которые получаются как сочетание основного символа и какого-то значка над ним или под ним.
Например, на основе обычного символа существуют символы: . Самые часто встречающиеся подобные сочетания имеют отдельный юникодный код. Но отнюдь не все.
Для генерации произвольных сочетаний используются несколько юникодных символов: основа и один или несколько значков.
Например, если после символа идёт символ «точка сверху» (код ), то показано это будет как «S с точкой сверху» .
Если нужен ещё значок над той же буквой (или под ней) – без проблем. Просто добавляем соответствующий символ.
К примеру, если добавить символ «точка снизу» (код ), то будет «S с двумя точками сверху и снизу» .
Пример этого символа в JavaScript-строке:
Такая возможность добавить произвольной букве нужные значки, с одной стороны, необходима, а с другой стороны – возникает проблемка: можно представить одинаковый с точки зрения визуального отображения и интерпретации символ – разными сочетаниями Unicode-кодов.
Вот пример:
В первой строке после основы идёт сначала значок «верхняя точка», а потом – нижняя, во второй – наоборот. По кодам строки не равны друг другу. Но символ задают один и тот же.
С целью разрешить эту ситуацию, существует юникодная нормализация, при которой строки приводятся к единому, «нормальному», виду.
В современном JavaScript это делает метод str.normalize().
Забавно, что в данной конкретной ситуации приведёт последовательность из трёх символов к одному: \u1e68 (S с двумя точками).
Это, конечно, не всегда так, просто в данном случае оказалось, что именно такой символ в юникоде уже есть. Если добавить значков, то нормализация уже даст несколько символов.
Для большинства практических задач информации, данной выше, должно быть вполне достаточно, но если хочется более подробно ознакомиться с вариантами и правилами нормализации – они описаны в приложении к стандарту юникод Unicode Normalization Forms.
Внутреннее устройство массива
Массив – это особый подвид объектов. Квадратные скобки, используемые для того, чтобы получить доступ к свойству – это по сути обычный синтаксис доступа по ключу, как , где в роли у нас , а в качестве ключа – числовой индекс.
Массивы расширяют объекты, так как предусматривают специальные методы для работы с упорядоченными коллекциями данных, а также свойство . Но в основе всё равно лежит объект.
Следует помнить, что в JavaScript существует 8 основных типов данных. Массив является объектом и, следовательно, ведёт себя как объект.
…Но то, что действительно делает массивы особенными – это их внутреннее представление. Движок JavaScript старается хранить элементы массива в непрерывной области памяти, один за другим, так, как это показано на иллюстрациях к этой главе. Существуют и другие способы оптимизации, благодаря которым массивы работают очень быстро.
Но все они утратят эффективность, если мы перестанем работать с массивом как с «упорядоченной коллекцией данных» и начнём использовать его как обычный объект.
Например, технически мы можем сделать следующее:
Это возможно, потому что в основе массива лежит объект. Мы можем присвоить ему любые свойства.
Но движок поймёт, что мы работаем с массивом, как с обычным объектом. Способы оптимизации, используемые для массивов, в этом случае не подходят, поэтому они будут отключены и никакой выгоды не принесут.
Варианты неправильного применения массива:
- Добавление нечислового свойства, например: .
- Создание «дыр», например: добавление , затем (между ними ничего нет).
- Заполнение массива в обратном порядке, например: , и т.д.
Массив следует считать особой структурой, позволяющей работать с упорядоченными данными. Для этого массивы предоставляют специальные методы. Массивы тщательно настроены в движках JavaScript для работы с однотипными упорядоченными данными, поэтому, пожалуйста, используйте их именно в таких случаях. Если вам нужны произвольные ключи, вполне возможно, лучше подойдёт обычный объект .
Использование методов и свойств строк
Для манипулирования строками в Javascript как и во многих других языках программирования предусмотрена возможность использования методов(объектных функций) , , , … и свойств , , … . Вызов методов и свойств осуществляется через оператор (точка). Вызов объектных функций может быть осуществлен не однократно, образуя тем самым цепочки методов.
var str = «Text»;
str.italics(); //Преобразование строки в курсив (<i>Text</i>)
//Цепочка методов (каждый метод вызывается из значения, которое возвратил предыдущий метод)
str.toUpperCase().big().bold() // Результат — <b><big>TEXT</big></b>
|
1 |
varstr=»Text»; str.italics();//Преобразование строки в курсив (<i>Text</i>) //Цепочка методов (каждый метод вызывается из значения, которое возвратил предыдущий метод) str.toUpperCase().big().bold()// Результат — <b><big>TEXT</big></b> |
Применение методов и свойств к простым строковым литералам невозможно, поэтому если интерпретатор видит вызов метода из строки, то он автоматически преобразует ее в объект и делает вызов метода или свойства уже из строки — объекта.
Важно заметить, что вызов метода не переопределяет строку, т.к. работает с ее копией и начальное значение строки остается неизменным
var str = » Random text written «; //удалим пробелы с начала и конца строки
str.trim(); //Результат — «Random text written»
str; //Само значение строки не изменилось — » Random text written »
|
1 |
varstr=» Random text written «;//удалим пробелы с начала и конца строки str.trim();//Результат — «Random text written» str;//Само значение строки не изменилось — » Random text written « |
Сравнение строк
Если оператор отношения применяется к двум строкам, то сравнение происходит побуквенно/посимвольно. То есть сравнение происходит так: каждый символ (буква) первой строки сравнивается с соответствующим символом второй строки и так, до того момента, пока символы не будут разными, и тогда какой символ больше – та строка и больше. Если же в одной из строк закончились символы, то считаем, что она меньше, а если закончились в обеих – строки равны.
Теперь разберем, как происходит сравнение каждого символа. Каждый символ переводится в числовое значение, согласно кодировке Unicode, и суть сравнения символов сводиться к сравнению двух чисел. Например, десятичные (Dec) значения символов кирилицы лежат в диапазоне от 1024 до 1280.
Пример:
Начинаем сравнивать первые символы: str1 (буква «А») и str2 (буква «а»).
В JavaScript, как и в других языках програмирования, есть метод для получения цифрового кода из символа:
Метод возвращает код символа расположенного на позиции в строке . Отсчет позиций символов в строке начинается с нуля.
Выполнить код »
Скрыть результаты
Если бы первые символы строк были равны, то дальше сравнивались бы следующие символы попарно.
В этом примере строка считается меньше, чем строка , потому что буква имеет код , а буква – . Причина в том, что коды прописных букв всегда меньше, чем строчных.
Чтобы правильно сравнить строки по алфавиту, необходимо перед сравнением преобразовать оба операнда в один регистр (например, в нижний):
Выполнить код »
Скрыть результаты
После преобразования в нижний регистр слово «апельсин» становится больше, чем слово «абрикос», потому что вторая буква имеет код , а вторая буква переменной – .
Примечание: Обычно, буква расположенная в алфавитном порядке раньше имеет меньший числовой код, чем буква (в том же регистре) расположенная в алфавитном порядке после неё.
Не менее интересная ситуация складывается при сравнении чисел, предствленных в строковой форме, например:
Выполнить код »
Скрыть результаты
В примере выше «15»
Если хотя бы один операнд изменить на число, то другой будет преобразован к числу:
Выполнить код »
Скрыть результаты
В этом примере строка «15» преобразуется в число 15, а затем производится сравнение полученных чисел.
Когда строка сравнивается с числом, она преобразуется в число и выполняется числовое сравнение операндов.
В случае, когда строку невозможно преобразовать в число, она преобразуется в . Как правило, в результате любой операции сравнения с операндом получается :
Выполнить код »
Скрыть результаты
Численное преобразование
Численное преобразование происходит в математических функциях и выражениях, а также при сравнении данных различных типов (кроме сравнений , ).
Для преобразования к числу в явном виде можно вызвать , либо, что короче, поставить перед выражением унарный плюс :
| Значение | Преобразуется в… |
|---|---|
| Строка | Пробельные символы по краям обрезаются.Далее, если остаётся пустая строка, то , иначе из непустой строки «считывается» число, при ошибке результат . |
Например:
Ещё примеры:
-
Логические значения:
-
Сравнение разных типов – значит численное преобразование:
При этом строка преобразуется к числу, как указано выше: начальные и конечные пробелы обрезаются, получается строка , которая равна .
-
С логическими значениями:
Здесь сравнение снова приводит обе части к числу. В первой строке слева и справа получается , во второй .
Посмотрим на поведение специальных значений более внимательно.
Интуитивно, значения ассоциируются с нулём, но при преобразованиях ведут себя иначе.
Специальные значения преобразуются к числу так:
| Значение | Преобразуется в… |
|---|---|
Это преобразование осуществляется при арифметических операциях и сравнениях , но не при проверке равенства . Алгоритм проверки равенства для этих значений в спецификации прописан отдельно (пункт ). В нём считается, что и равны между собой, но эти значения не равны никакому другому значению.
Это ведёт к забавным последствиям.
Например, не подчиняется законам математики – он «больше либо равен нулю»: , но не больше и не равен:
Значение вообще «несравнимо»:
Для более очевидной работы кода и во избежание ошибок лучше не давать специальным значениям участвовать в сравнениях .
Используйте в таких случаях переменные-числа или приводите к числу явно.
Примитив как объект
Вот парадокс, с которым столкнулся создатель JavaScript:
- Есть много всего, что хотелось бы сделать с примитивами, такими как строка или число. Было бы замечательно, если бы мы могли работать с ними через вызовы методов.
- Примитивы должны быть лёгкими и быстрыми.
Выбранное решение, хотя выглядит оно немного неуклюже:
- Примитивы остаются примитивами. Одно значение, как и хотелось.
- Язык позволяет осуществлять доступ к методам и свойствам строк, чисел, булевых значений и символов.
- Чтобы это работало, при таком доступе создаётся специальный «объект-обёртка», который предоставляет нужную функциональность, а после удаляется.
Каждый примитив имеет свой собственный «объект-обёртку», которые называются: , , и . Таким образом, они имеют разный набор методов.
К примеру, существует метод str.toUpperCase(), который возвращает строку в верхнем регистре.
Вот, как он работает:
Очень просто, не правда ли? Вот, что на самом деле происходит в :
- Строка – примитив. В момент обращения к его свойству, создаётся специальный объект, который знает значение строки и имеет такие полезные методы, как .
- Этот метод запускается и возвращает новую строку (показывается в ).
- Специальный объект удаляется, оставляя только примитив .
Получается, что примитивы могут предоставлять методы, и в то же время оставаться «лёгкими».
Движок JavaScript сильно оптимизирует этот процесс. Он даже может пропустить создание специального объекта. Однако, он всё же должен придерживаться спецификаций и работать так, как будто он его создаёт.
Число имеет собственный набор методов. Например, toFixed(n) округляет число до n знаков после запятой.
Более подробно с различными свойствами и методами мы познакомимся в главах Числа и Строки.
Конструкторы предназначены только для внутреннего пользования
Некоторые языки, такие как Java, позволяют явное создание «объектов-обёрток» для примитивов при помощи такого синтаксиса как или .
В JavaScript, это тоже возможно по историческим причинам, но очень не рекомендуется. В некоторых местах последствия могут быть катастрофическими.
Например:
Объекты в всегда дают , так что в нижеприведённом примере будет показан :
С другой стороны, использование функций без оператора – вполне разумно и полезно. Они превращают значение в соответствующий примитивный тип: в строку, в число, в булевый тип.
К примеру, следующее вполне допустимо:
null/undefined не имеют методов
Особенные примитивы и являются исключениями. У них нет соответствующих «объектов-обёрток», и они не имеют никаких методов. В некотором смысле, они «самые примитивные».
Попытка доступа к свойствам такого значения возвратит ошибку:
Синтаксис строчных переменных
При инициализации переменных значения могут быть обрамлены в двойные, одинарные, а начиная с 2015 года и в скошенные одинарные кавычки. Ниже я прикрепил примеры каждого способа объявления строк.
Хочу уделить особое внимание третьему способу. Он обладает рядом преимуществ
С его помощью можно спокойно осуществлять перенос строки и это будет выглядеть вот так:
А еще третий способ позволяет использовать конструкцию ${…}. Такой инструмент нужен для вставки интерполяции. Не пугайтесь, сейчас расскажу, что это такое.
Благодаря ${…} в строки можно вставлять не только значения переменных, а еще и выполнять с ними арифметические и логические операции, вызывать методы, функции и т.д. Все это называется одним терминов – интерполяция. Ознакомьтесь с примером реализации данного подхода.
1 2 3 |
var pen = 3;
var pencil = 1;
alert(`${pen} + ${pencil*5} = ${pen + pencil}`);
|
В результате на экран выведется выражение: «3 + 1*5 = 8».
Что касается первых двух способов объявления строк, то в них разницы никакой нет.
Управляющие последовательности
В строковых литералах можно использовать управляющие последовательности. Управляющая последовательность – это последовательность, состоящая из обычных символов, которая обозначает символ, не представимый внутри строки другими способами. Управляющие последовательности предназначены для форматирования вывода текстового содержимого.
В таблице ниже представлены управляющие последовательности:
| Последовательность | Значение |
|---|---|
| Символ NUL – пустой символ (). | |
| Горизонтальная табуляция (). | |
| Перевод на новую строку (). | |
| Возврат на одну позицию – то, что происходит при нажатии на клавишу backspace (). | |
| Возврат каретки (). | |
| Перевод страницы – очистка страницы (). | |
| Вертикальная табуляция (). | |
| Двойная кавычка (). | |
| Одинарная кавычка (). | |
| Обратный слэш (). | |
| Номер символа из набора символов ISO Latin-1, заданный двумя шестнадцатеричными цифрами ( – шестнадцатеричная цифра ). Например, (это код буквы ). | |
| Номер символа из набора символов Unicode, заданный четырьмя шестнадцатеричными цифрами ( – шестнадцатеричная цифра ). Например, (это код буквы ). |
Управляющие последовательности могут находиться в любом месте строки:
alert("Греческая буква сигма: \u03a3."); // Греческая буква сигма: Σ.
alert("Многострочная\nстрока") // Многострочная
// строка
alert("внутри используются \"двойные\" кавычки"); // внутри используются "двойные" кавычки
Если символ предшествует любому символу, отличному от приведённых в таблице, то он просто игнорируется интерпретатором:
alert("\k"); // "k"
Символы Unicode, указываемые с помощью управляющей последовательности, можно использовать не только внутри строковых литералов, но и в идентификаторах:
let a\u03a3 = 5; alert(a\u03a3); // 5
Итоги
- Операторы сравнения сравнивают значения операндов и возвращают логическое значение – или в зависимости от результатов проверки.
- При сравнении операнды, имеющие значения разных типов, приводятся к числовому значению, за исключением сравнения на идентичность и неидентичность .
- При сравнении строк, сравнение происходит побуквенно: каждый символ переводится в числовое значение, согласно кодировке Unicode, и суть сравнения символов сводиться к сравнению двух чисел.
- Код буквы в нижнем регистре всегда больше, чем код буквы в верхнем регистре.
- Код цифры находящейся в строке всегда меньше кода буквенного символа в любом регистре.
- Как правило, код буквы, расположенной в алфавитном порядке раньше имеет меньшее значение, чем код буквы (в том же регистре), расположенной в алфавитном порядке после неё.
- Операторы сравнения считают значение не равным никакому другому значению, включая само себя.
- Значения и НЕ СТРОГО равны друг другу.
- При преобразовании в число становится 0, а становится .