Что такое кэш-память и история браузера. как посмотреть-удалить историю, очистить и увеличить кэш браузера
Содержание:
- Что такое кэш сайта?
- Что такое кэш браузера
- Вариант 2: копии страниц в поисковых системах
- Просмотр удаленной страницы ВКонтакте в вебархиве
- Создание бэкапа
- Кэширование с прогнозируемым обновлением
- Просмотр удаленной страницы ВКонтакте в кеше браузера
- Почему закрытые и удаленные страницы есть в поиске
- Как читать кэшированные файлы
- Как просмотреть копию страницы?
- Для чего нужны сохраненные страницы?
- Как удалить свои данные и историю транзакций
- Шаг 1. Удалите способы оплаты
- Шаг 2. Очистите кеш
- Как экспортировать данные из Google Pay
- Как восстановить закладки в Яндексе – защита и надежное сохранение данных
- Http заголовки для управления клиентским кэшированием
- Архивы веб-страниц, постоянные
- Как восстановить закладки в Яндексе – синхронизация через Яндекс-аккаунт
- Как удалить страницу из поисковой системы Google
- Механический метод удаления
Что такое кэш сайта?
Ответить на вопрос, что такое кэш сайта довольно просто. Это наиболее используемые элементы в работе: изображения, html-шаблонов, файлов js, css и т.д. Суть заключается в том, что с помощью сохраненной информации вэб-ресурс, программы, сервисы значительно ускоряются в работе.
Скорость обуславливается тем, что извлечение обработанных данных из кэша гораздо проще и занимает меньше времени, чем запрос из основного хранилища. Стоит отметить, что показатель CR сможет Вас порадовать, если решитесь на данную процедуру для своего сайта.
Существует четкая схема взаимодействия приложений с кэшом:
- Во время первого запроса все данные заносятся в кэш;
- При повторном запросе материалы берутся из кэша;
- Когда кэш пуст или его информация устарела, то алгоритм перезапускается;
- Настройки хранения находятся в файлах конфигурации вэб-ресурсов и самого сервера.
Данный термин очень универсален и встретить его можно в различных сферах жизнедеятельности. Например, в мобильных дэкстопных приложениях, аппаратном обеспечении и т.д. Даже на сайтах, посвященных тому, что такое сторителлинг можно увидеть успешное использование кэширования.
Что такое кэш браузера
Кэш (Cache) — это специально отведенное место (хранилище) в памяти жесткого диска для хранения копий данных с посещенных страниц сайтов, например таких как: картинки, текст, файлы и т.д.
Кэш позволяет сайтам загружаться намного быстрее и уменьшает размер расходуемого интернет-трафика. Работает это так: когда вы посещаете какой-либо сайт в интернете, браузер сохраняет в определенное место на компьютере данные с его посещенных страниц. При следующем его посещении, перед тем как начать загружать страничку, браузер в начале, проверит, изменялись ли на ней какие-либо элементы и если нет, то будут загружены, как раз таки сохраненные ранее данные.
Каждый веб-браузер имеет функцию кэширования, файлы которого, как правило хранятся в определенной папке на компьютере. Они, обычно не занимают много места на компьютере и автоматически очищаются сами. Также, стоит отметить, что вебмастер, на своем сайте может сам определить, какие элементы попадут в cache память браузера пользователя, а какие нет. Как и сам пользователь может полностью отключить запись кэша на свой компьютер.
Зачем нужен кэш?
Кэширование значительно упрощает нам жизнь, благодаря ему у нас нет необходимости каждый раз ждать, когда с сайта подгрузятся какие-либо элементы, которые мы уже видели и соответственно загружали. Это сильно экономит время, ваш интернет трафик и скорость загрузки страниц. Ниже приведен весь список преимуществ:
- Быстрая повторная загрузка страниц сайтов
- Уменьшение размера загружаемого интернет-трафика
- Быстрая повторная загрузка музыки, картинок, видео, например, с YouTube
- Возможность достать информацию из кэша и сохранить к себе на ПК
- Если поместить cache в оперативную память, то страницы будут грузиться еще быстрее
- Возможность посмотреть страницы сайта из кеша даже при отключенном интернете
Где находится кэш браузера
Каждый браузер хранит кэшированные файлы в своей определенной папке. Но расположение этой папки может меняться от версии к версии самой программы или от установленной на компьютере операционной системы, например, в Windows, файлы будут лежать в одном месте, а в Linux или Mac OS в другом.
У каждого — своя индивидуальная папка
Размер этой папки является фиксированным, но его конечно же можно отрегулировать в настройках программы. Также, браузер сам очищает cache файлы, когда места остается совсем мало, переписывая старые и неиспользуемые новые.
О том, в каких местах самые популярные веб-браузеры хранят свои кэшированные файлы и как их очистить — вы узнаете в следующих подробных статьях данной рубрики.
Зачем нужно очищать кэш
Функция кэширования в некоторых случаях может не правильно работать и кэш-файлы будут занимать намного больше места на винчестере, чем нужно. Из-за этого браузер начинает сильно тормозить в процессе своей работы. Кроме этого, бывает так, что информация на сайте уже давно обновилась, но данные все равно загружаются из кэша. К тому же его необходимо очищать сразу после удаления различных вирусов с компьютера.
Периодически
Если вы хотите очистить cache память определенной странички, когда находитесь на ней, нажмите на клавиатуре синхронно две клавиши «CTRL + F5», после этого она должна загрузиться с новыми данными.
В заключение
Надеюсь эта статья помогла вам разобраться в данной теме и вы поняли, что это такое. Добавляйте сайт в закладки, будет еще много чего нового и познавательного!
Вариант 2: копии страниц в поисковых системах
Я уже как-то отмечал , что пользователям поисковых систем нет смысла заходить на сайты, ведь можно просматривать копии их страниц в самой поисковой системе. Так или иначе, но это хороший способ просмотреть удалённую страницу.
, Вы можете использовать оператор поискового запроса info: , с указанием нужного URL-адреса, например:
В случае с поисковой системой Яндекс
, Вы можете использовать оператор поискового запроса url: , с указанием нужного URL-адреса, например:
Здесь нам нужно навести курсор мыши на (зелёный)
URL-адресс в сниппете, а потом кликнуть появившуюся ссылку «копия
» и мы получим последнюю сохранённую в Яндекс версию удалённой страницы.
Проблема в том, что поисковые системы хранят только последние проиндексированные копии страниц. В том случае если страница была удалена, со временем она может стать недоступной и в кэше поисковых систем.
Просмотр удаленной страницы ВКонтакте в вебархиве
В интернете каждый день сотни сайтов меняются, удаляются, на их месте появляются новые и происходят другие подобные манипуляции. Есть несколько сервисов, которые следят за этими действиями, сохраняя копии сайтов и отдельных страниц. Используя такой сервис, можно посмотреть информацию, которая была размещена на удаленной странице ВКонтакте. Делается это следующим образом:
- Первым делом откройте сайт сервиса вебархива: https://web.archive.org;
- Далее в адресную строку нужно ввести линк на страницу, информацию о которой вы хотите узнать;
Стоит отметить, что сервис вебархив не лучшим образом работает с сохранением информации о страницах пользователей ВКонтакте, и если аккаунт был зарегистрирован недавно, велика вероятность, что информация о нем в базе данных сервиса не будет найдена.
Создание бэкапа
Резервирование истории исключает всевозможные неприятности, связанные со случайным удалением журнала (по ошибке, в результате вирусной атаки или программного сбоя). Но, разумеется, о создании копии нужно побеспокоиться заранее. Создать бэкап и выполнить восстановление при помощи него можно различными методами.
Способ №1: копирование файла
1. Откройте профиль в директории браузера:C: → Users → → AppData → Local → Yandex → YandexBrowser → User Data → Default
2. Кликните правой кнопкой по файлу History. В списке клацните «Копировать».
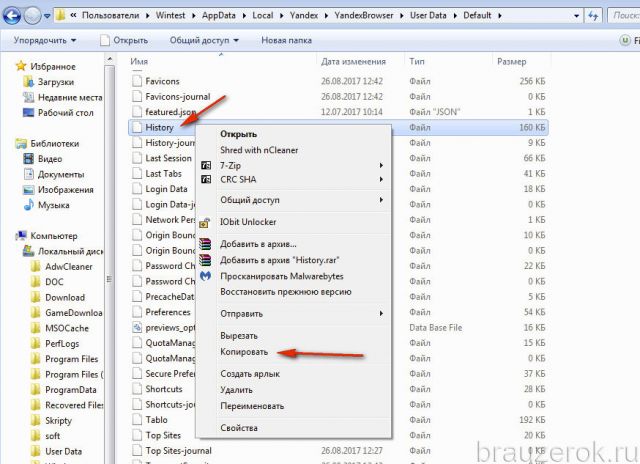
3. Вставьте файл в другую папку. Желательно, чтобы она находилась в другом разделе диска (не системном!).
4. Это и будет ваш бэкап. При необходимости вы можете его снова вставить в профиль Яндекса — заменить текущий файл History.
Способ №2: резервирование утилитой hc.Historian
hc.Historian — достойная альтернатива штатному инструменту браузеров для просмотра журнала посещений. В автоматическом режиме она создаёт отдельный бэкап истории, который в любой момент можно просмотреть и использовать для восстановления. Даже в случае полного удаления браузера.
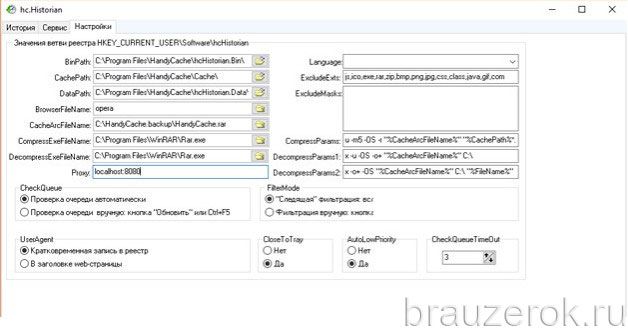
В интерфейсе утилиты можно задавать настройки резервирования (указывать директорию, архиватор для компрессии копии, а также браузер, данные которого нужно обрабатывать).
Способ №3: синхронизация
Синхронизация подразумевает сохранение всех настроек пользовательского профиля с возможностью последующего его восстановления (загрузки) в браузере не только на компьютере, но и на мобильных устройствах (например, на Андроиде).
Примечание.
Чтобы воспользоваться этим способом, вам понадобится учётная запись в системе Yandex.
1. Кликните «Меню». В списке нажмите «Синхронизация».
2. Введите логин и пароль для входа в аккаунт.
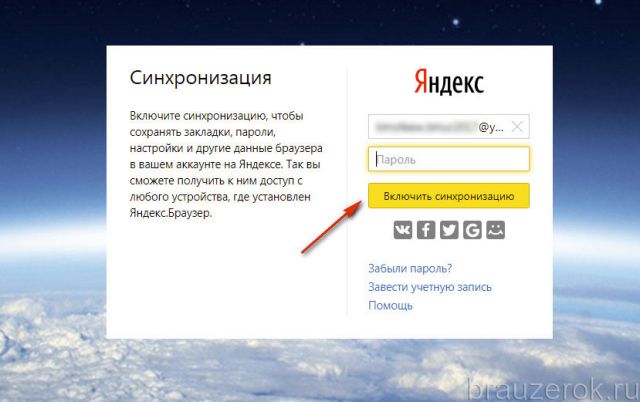
3. Клацните «Включить синхронизацию».
4. Теперь, когда вам нужно будет восстановить историю и другие пользовательские данные, снова откройте раздел «Синхронизация» и выполните авторизацию в профиле.
Выберите наиболее действенный способ восстановления конкретно для вашего случая. Восстановление файла утилитой Recuva, безусловно, выполнить проще и безопасней. Но если она не смогла обнаружить ранее удалённый журнал, можно выполнить откат настроек системы. Не забывайте периодически создавать бэкапы истории, если в ней хранятся важные, ценные для вас ссылки.
Когда случайно пропала одна закладка из архива браузера – это уже неприятно, но что делать, если после запуска “Яндекса” исчезли они все? Восстановить букмарки легко, если знать правильный подход к настройкам и горячим клавишам программы.
Кэширование с прогнозируемым обновлением
Рассмотрим пример — прайс лист обновляемый именно по понедельникам. Вы знаете заранее о том, что содержание странички можно хранить в кэш до наступления следующей недели, что и нужно указать в заголовке ответа, обеспечивая необходимое поведение странички в кэш.
Главной задачей здесь является получить дату следующего понедельника в виде RFC-1123.
$dt_tmp=getdate(date("U"));
header("Expires: " . gmdate("D, d M Y H:i:s",
date("U")-(86400*($dt_tmp-8))) . " GMT");
header("Cache-control: public");
Данным способом можно очень эффективно управлять поведением странички в кэш. Можно выделить особые временные интервалы в течении которых содержание определенной странички остается постоянным.
Другой подход, который применяется при более оперативном обновлении данных и одновременной большой посещаемости сервера (в другом случае кэширование эффективным не будет) состоит в использовании специального заголовка Cache-control: max-age=секунды, который определяет время, по истечении которого документ уже считается устаревшим и имеющий гораздо больший приоритет при вычислении свежести конкретного документа.
Если Вы публикуете новости с интервалом в 60 минут:
header("Cache-control: public");
header("Cache-control: max-age=3600");
Просмотр удаленной страницы ВКонтакте в кеше браузера
Важно: Данный способ могут использовать только те пользователи, которые захотят посмотреть страницу человека, к которому они ранее заходили, но после он ее удалил. Метод основывается на том, что браузеры хранят копии сайтов, что необходимо для их более быстрой загрузки при необходимости
Если вы некоторое время назад заходили на страницу к пользователю, после чего он ее удалил, у вас есть возможность посмотреть ее сохраненную копию в браузере. Сделать это можно практически в любом браузере, рассмотрим на примере Opera
Метод основывается на том, что браузеры хранят копии сайтов, что необходимо для их более быстрой загрузки при необходимости. Если вы некоторое время назад заходили на страницу к пользователю, после чего он ее удалил, у вас есть возможность посмотреть ее сохраненную копию в браузере. Сделать это можно практически в любом браузере, рассмотрим на примере Opera
- Первым делом потребуется активировать в самом браузере автономный режим работы. Для этого необходимо раскрыть меню и выбрать пункт «Настройки», после чего отметить галочкой вариант «Работать автономно»;
- Скопируйте в адресную строку браузера адрес страницы, информацию о которой вы хотите посмотреть, и перейдите на нее. Если копия данной страницы сохранилась в браузере, то она загрузится.
Это все способы, позволяющие посмотреть информацию, которая ранее была расположена на удаленной странице ВКонтакте.
Почему закрытые и удаленные страницы есть в поиске
Причин может быть несколько и некоторые из них я постараюсь выделить в виде небольшого списка с пояснениями. Перед началом дам пояснение что подразумеваю под «лишними» (закрытыми) страницами: служебные или иные страницы, запрещенные к индексации правилами или мета-тегом.
Несуществующие страницы находятся в поиске по следующим причинам:
Самое банальное — страница удалена и больше не существует.
Ручное редактирование адреса web-страницы, вследствие чего документ который уже находится в поиске становится не доступным для просмотра
Особое внимание этому моменту нужно уделить новичкам, которые в силу своих небольших знаний пренебрежительно относятся к функционированию ресурса.
Продолжая мысль о структуре напомню, что по-умолчанию после установки WordPress на хостинг она не удовлетворяет требованиям внутренней оптимизации и состоит из буквенно-цифровых идентификаторов. Приходится на ЧПУ, при этом появляется масса нерабочих адресов, которые еще долго будут оставаться в индексе поисковых систем
Поэтому применяйте основное правило: надумали менять структуру — используйте 301 редирект со старых адресов на новые. Идеальный вариант — выполнить все настройки сайта ДО его открытия, в этом может пригодиться локальный сервер.
Не правильно настроена работа сервера. Несуществующая страница должна отдавать код ошибки 404 или с кодом 3хх.
Лишние страницы появляются в индексе при следующих условиях:
- Страницы, как Вам кажется, закрыты, но на самом деле они открыты для поисковых роботов и находятся в поиске без ограничений (или не правильно написан robots.txt). Для проверки прав доступа ПС к страницам воспользуйтесь соответствующими инструментами для .
- Они были проиндексированы до того как были закрыты доступными способа.
- На данные страницы ссылаются другие сайты или внутренние страницы в пределах одного домена.
Итак, с причинами разобрались. Стоит отметить, что после устранения причины несуществующие или лишние страницы еще долгое время могут оставаться в поисковой базе — все зависит от или частоты посещения сайта роботом.
Как читать кэшированные файлы
Внутри папки Cache вы найдете файлы с различными расширениями и случайными именами файлов. Трудность в том, что вы не будете точно знать, на что вы смотрите. Большинство имен случайны, и нет никакого способа определить формат файла или откуда он взялся.
Вы можете нажать на каждый файл, чтобы открыть его, или декодировать кэшированные файлы, используя специальное программное обеспечение или расширение браузера. Один из лучших вариантов является использование одного из инструментов веб — браузера по NirSoft. Для Google Chrome это ChromeCacheView.
После загрузки средства просмотра кэша дважды щелкните, чтобы открыть главное окно. Вы найдете полный список файлов, хранящихся в кеше вашего браузера.
Помимо имени файла, вы увидите URL, тип и размер файла и другие свойства. Вы можете экспортировать один файл или полный список, скопировать URL-адреса ваших кэшированных файлов и извлечь файлы из кэша, если вы хотите сохранить их в другой папке.
К сожалению, утилиты Nirsoft работают исключительно на Windows. Поэтому, если вы хотите использовать его для декодирования ваших кэшированных файлов на Mac, вам придется перенести всю вашу папку кэшей на компьютер с Windows, а затем использовать программное обеспечение для чтения ваших файлов.
Как просмотреть копию страницы?
Самый простой и доступный способ посмотреть копии сохраненной страницы — сделать это вручную. В этом помогает поисковая выдача Яндекса. Возле каждого пункта найденных страниц имеется небольшая зеленая стрелка, вызывающая контекстное меню. И среди пунктов есть «Сохраненная копия». Она моментально переведет пользователя на кэшированную страницу.
Более автоматизированный способ подразумевает использование разнообразных плагинов, показывающих последние сохраненные страницы поисковиков. Это может быть удобно при периодическом мониторинге продвижения ресурса в поисковой выдаче.
Для чего нужны сохраненные страницы?
Кэш-страницы сайта в поисковых системах позволяют увидеть, какую версию документа уже успели проиндексировать роботы поисковых систем и участвует ли страница в ранжировании. Грубо говоря, если страница начала сохраняться — это главный фактор пройденной индексации.
Бесплатный бэкап
В работе с сайтами, может возникнуть масса непредвиденных ситуаций. Особенно на стадии запуска проекта, на сайте частенько ведутся технические работы, предполагающие корректировку дизайна и текстовых блоков. В такие моменты не исключены ошибки, которые могут «положить» сайт или нарушить его работу, также могут пропасть тексты, изображения и так далее.
Большинству разработчиков знакомы такие ситуации и если не был проведен бэкап, а дешевый хостинг не позволяет сделать «откат», то все печально. Вот тут-то и приходит на помощь кэш сайтов — копия позволяет сохраниться и проверить, какие ошибки нужно исправить.
SEO-продвижение
Еще один случай, когда кеш придет на помощь, связан с текстами. Например, вы откорректировали текст, чтобы повысить его релевантность. Чтобы проверить, обновилась и проиндексировалась ли нужная страница, достаточно взглянуть на копию.
Технические проблемы, просрочка оплаты и так далее
Часто интернет-ресурсы бывают недоступны из-за технических проблем на сервере, истечения срока оплаты хостинга и т.п. В этом случае попасть на сайт можно также через копию, которая хранится в кэше.
Как удалить свои данные и историю транзакций
Как удалить данные о транзакциях Google Pay из аккаунта Google
Чтобы удалить сведения о транзакциях, связанных с конкретным способом оплаты, нужно удалить этот способ оплаты из Google Pay. Также вам может потребоваться удалить некоторые данные на странице myactivity.google.com.
Как удалить данные обо всех транзакциях
Примечание. Вы можете удалить информацию об отдельных операциях. При этом сведения о других транзакциях сохранятся, а запись истории будет продолжена. Чтобы стереть все данные, нужно полностью удалить профиль Google Pay.
- Откройте страницу удаления сервисов Google и войдите в свой аккаунт.
- Рядом с Google Pay нажмите на значок «Удалить» .
- Установите флажки.
- Нажмите Удалить данные Google Pay.
Как удалить данные об определенной транзакции
Примечание. Даже если вы удалите определенную информацию из профиля, Google может продолжить хранить ее из-за требований законодательства.
Чтобы удалить сведения о конкретной операции, например о полученном или отправленном платеже или о покупке в магазине, выполните следующие действия:
- Откройте страницу myactivity.google.com
При необходимости войдите в аккаунт Google.
.
- Найдите дату транзакции.
- Под транзакцией выберите Подробные сведения.
- Нажмите на значок «Ещё» Удалить.
Примечание. Данные будут удалены из вашего аккаунта Google. Транзакции, выполненные в магазинах, будут также удалены с вашего устройства. Чтобы удалить с устройства и другие сведения, следуйте инструкции из раздела ниже.
Как удалить с устройства приложение Google Pay и связанные с ним данные
Примечание. Если на вашем устройстве установлена устаревшая версия Android, инструкции могут быть другими. Подробнее о том, как обновить версию Android…
Шаг 1. Удалите способы оплаты
- Откройте приложение «Настройки».
- Нажмите .
- Выберите Google Pay.
- Нажмите на значок «Удалить» рядом с каждым способом оплаты.
Шаг 2. Очистите кеш
- Откройте приложение «Настройки».
- Нажмите Приложения и уведомления.
- Выберите Google Pay. Если приложения нет в списке, нажмите Все приложения Google Pay.
- Нажмите Хранилище Очистить хранилище.
- Нажмите Очистить кеш.
Как экспортировать данные из Google Pay
Выполните следующие действия:
- Откройте страницу takeout.google.com
При необходимости войдите в аккаунт Google.
на компьютере.
- Убедитесь, что экспорт данных из Google Pay включен. Если вы не хотите экспортировать данные из каких-либо сервисов Google, снимите флажки рядом с ними.
- Нажмите Далее.
- Выберите формат архива.
- Нажмите Создать архив.
Как восстановить закладки в Яндексе – защита и надежное сохранение данных
Чтобы закладки не пропали при сбое в браузере, либо после переустановки самой системы, следует воспользоваться функцией синхронизации, которая запишет их в облако. Также можно сохранить закладки в отдельном HTML-файле, при необходимости обновляя его перезаписью, а после подключив к новой программе. Чтобы перенести в HTML:
- нажимаем Alt+F;
- выбираем “Диспетчер закладок”;
- щелкаем по “Упорядочить”;
- выбираем пункт “Экспортировать”;
- сохраняем файл на жестком диске и запоминаем, где он лежит.
Чтоб восстановить закладки из HTML-файла, из меню “Упорядочить” выбираем строку “Скопировать из..” и указываем размещение бэкапа.
Http заголовки для управления клиентским кэшированием
Для начала давайте посмотрим, как сервер и браузер взаимодействуют при отсутствии какого-либо кэширования. Для наглядного понимания я попытался представить и визуализировать процесс общения между ними в виде текстового чата. Представьте на несколько минут, что сервер и браузер – это люди, которые переписываются друг с другом 🙂
Без кэша (при отсутствии кэширующих http-заголовков)
Как мы видим, каждый раз при отображении картинки cat.png браузер будет снова загружать ее с сервера. Думаю, не нужно объяснять, что это медленно и неэффективно.
Заголовок ответа и заголовок запроса .
Идея заключается в том, что сервер добавляет заголовок к файлу (ответу), который он отдает браузеру.
Теперь браузер знает, что файл был создан (или изменен) 1 декабря 2014. В следующий раз, когда браузеру понадобится тот же файл, он отправит запрос с заголовком .
Если файл не изменялся, сервер отправляет браузеру пустой ответ со статусом . В этом случае, браузер знает, что файл не обновлялся и может отобразить копию, которую он сохранил в прошлый раз.
Таким образом, используя мы экономим на загрузке большого файла, отделываясь пустым быстрым ответом от сервера.
Заголовок ответа и заголовок запроса .
Принцип работы очень схож с , но, в отличии от него, не привязан ко времени. Время – вещь относительная.
Идея заключается в том, что при создании и каждом изменении сервер помечает файл особой меткой, называемой , а также добавляет заголовок к файлу (ответу), который он отдает браузеру:
Теперь браузер знает, что файл актуальной версии имеет равный “686897696a7c876b7e”. В следующий раз, когда брузеру понадобится тот же файл, он отправит запрос с заголовком .
Сервер может сравнить метки и, в случае, если файл не изменялся, отправить браузеру пустой ответ со статусом . Как и в случае с браузер выяснит, что файл не обновлялся и сможет отобразить копию из кэша.
Заголовок
Принцип работы этого заголовка отличается от вышеописанных и . При помощи определяется “срок годности” (“срок акуальности”) файла. Т.е. при первой загрузке сервер дает браузеру знать, что он не планирует изменять файл до наступления даты, указанной в :
В следующий раз браузер, зная, что “дата истечения срока годности” еще не наступила, даже не будет пытаться делать запрос к серверу и отобразит файл из кэша.
Такой вид кэша особенно актуален для иллюстраций к статьям, иконкам, фавиконкам, некоторых css и js файлов и тп.
Заголовок с директивой .
Принцип работы очень схож с . Здесь тоже определяется “срок годности” файла, но он задается в секундах и не привязан к конкретному времени, что намного удобнее в большинстве случаев.
Для справки:
- 1 день = 86400 секунд
- 1 неделя = 604800 секунд
- 1 месяц = 2629000 секунд
- 1 год = 31536000 секунд
К примеру:
У заголовка , кроме , есть и другие директивы. Давайте коротко рассмотрим наиболее популярные:
public
Дело в том, что кэшировать запросы может не только конечный клиент пользователя (браузер), но и различные промежуточные прокси, CDN-сети и тп. Так вот, директива позволяет абсолютно любым прокси-серверам осуществлять кэширование наравне с браузером.
private
Директива говорит о том, что данный файл (ответ сервера) является специфическим для конечного пользователя и не должен кэшироваться различными промежуточными прокси. При этом она разрешает кэширование конечному клиенту (браузеру пользователя). К примеру, это актуально для внутренних страниц профиля пользователя, запросов внутри сессии и т.п.
no-cache
Позволяет указать, что клиент должен делать запрос на сервер каждый раз. Иногда используется с заголовком , описанным выше.
no-store
Указывает клиенту, что он не должен сохранять копию запроса или частей запроса при любых условиях. Это самый строгий заголовок, отменяющий любые кэши. Он был придуман специально для работы с конфиденциальной информацией.
must-revalidate
Эта директива предписывает браузеру делать обязательный запрос на сервер для ре-валидации контента (например, если вы используете eTag). Дело в том, что http в определенной конфигурации позволяет кэшу хранить контент, который уже устарел. обязывает браузер при любых условиях делать проверку свежести контента путем запроса к серверу.
proxy-revalidate
Это то же, что и , но касается только кэширующих прокси серверов.
s-maxage
Практически не отличается от , за исключением того, что эта директива учитывается только кэшем резличных прокси, но не самим браузером пользователя. Буква “s-” исходит из слова “shared” (например, CDN). Эта директива предназначена специально для CDN-ов и других посреднических кэшей. Ее указание отменяет значения директивы и заголовка . Впрочем, если вы не строите CDN-сети, то вам вряд ли когда-либо понадобится.
Архивы веб-страниц, постоянные
Если вы хотите сохранять текстовый контент, то для этих целей рекомендуются Pocket и Instapaper. Вы можете сохранять страницы через электронную почту, расширения для браузеров или через приложения. Эти сервисы извлекают текстовый контент из веб-страниц и делают его доступным на всех ваших устройствах. Но вы не можете загрузить сохраненные статьи, а только прочитать их на сайте Pocket или через мобильное приложение сервиса. Дальше мы расскажем, как полностью скопировать страницу сайта.
Evernote и OneNote — это инструменты для архивирования контента в подборки. Они предоставляют в распоряжение пользователей веб-клипперы (или расширения), которые позволяют легко сохранять полные веб-страницы в один клик.
Захваченные веб-страницы могут быть доступны с любого устройства, сохраняется оригинальный дизайн и возможность поиска по странице. Эти сервисы могут даже выполнять оптическое распознавание, чтобы найти текст на фотографиях. Evernote также позволяет экспортировать сохраненные страницы как HTML-файлы, которые можно загрузить в другом месте.
Если нужен быстрый и простой доступ к веб-страницам, то сохраняйте их в виде PDF-файлов. Перед тем, как скопировать страницу сайта в виде картинки, выберите правильный инструмент.
Google Chrome имеет встроенный PDF-конвертер. Также можно использовать Google Cloud Print. На сервис добавлен новый виртуальный принтер «Сохранить в Google Drive«. В следующий раз, когда вы будете печатать страницу на компьютере или мобильном устройстве через Cloud Print, вы сможете сохранить ее PDF-копию в Google Drive. Но это не лучший вариант сохранения страниц со сложным форматированием.
Когда важно сохранить дизайн, то лучше всего использовать скриншотер. Выбор подобных программ довольно велик, но я бы рекомендовал официальное дополнение Chrome от
Оно не только захватывает полные скриншоты веб-страниц, но также загружает полученное изображение на Google Drive. Дополнение может сохранять веб-страницы в формате веб-архива (MHT), который поддерживается в IE и Firefox.
Wayback Machine на Internet Archive — это идеальное место для поиска предыдущих версий веб-страницы. Но этот же инструмент можно использовать, чтобы скопировать страницу сайта и сохранить ее. Перейдите на archive.org/web и введите URL-адрес любой веб-страницы. Архиватор скачает на сервер ее полную копию, включая все изображения. Сервис создаст постоянный архив страницы, который выглядит так же, как оригинал. Он останется на сервере, даже если исходная страница была переведена в автономный режим.
Internet Archive не предоставляет возможности загрузки сохраненных страниц, но для этого можно использовать Archive.Is. Этот сервис очень похож на archive.org в том, что вы вводите URL-адрес страницы, и он создает на своем сервере точный ее снимок. Страница будет сохранена навсегда, но здесь есть возможность загрузить сохраненную страницу в виде ZIP-архива. Сервис также позволяет создавать архивы по дате. Благодаря чему вы можете получить несколько снимков одной и той же страницы для разных дат.
Все популярные браузеры предоставляют возможность загрузить полную версию веб-страницы на компьютер. Они загружают на ПК HTML страницы, а также связанные с ней изображения, CSS и JavaScript. Поэтому вы сможете прочитать ее позже в автономном режиме.
Теперь разберемся, как полностью скопировать страницу сайта на электронную читалку. Владельцы eReader могут использовать dotEPUB, чтобы загрузить любую веб-страницу в формате EPUB или MOBI. Данные форматы совместимы с большинством моделей электронных книг. Amazon также предлагает дополнение, с помощью которого можно сохранить любую веб-страницу на своем Kindle-устройстве, но этот инструмент в основном предназначен для архивирования текстового контента.
Большинство перечисленных инструментов позволяют загружать одну страницу, но если вы хотите сохранить набор URL-адресов, решением может стать Wget. Также существует Google Script для автоматической загрузки веб-страниц в Google Drive, но таким образом можно сохранить только HTML-контент.
Как восстановить закладки в Яндексе – синхронизация через Яндекс-аккаунт
Чтобы защитить важную информацию на случай поломки жесткого диска или переустановки операционной системы, удобно использовать функцию синхронизации. Она позволит вам распоряжаться закладками и другими настройками на любом компьютере, к которому вы подключили Яндекс-аккаунт. Чтобы применить эту функцию:
- жмем Alt+F;
- выбираем пункт “Синхронизация”;
- указываем логин и пароль от Яндекс-почты;
- ниже кликаем по желтой кнопке “Включить синхронизацию”;
- вы будете перенаправлены на страницу настроек, где можно указать, какие данные сохранять.
Чтобы вернуть закладки на другом компьютере либо после переустановки браузера\операционной системы, просто включите синхронизацию и укажите данные своей учетной записи Яндекс. Букмарки будут перенесены автоматически.
Браузер также поддерживает удобную функцию визуальных закладок – отображает на “Табло” сайты, которые часто посещаются. Если на веб-площадку долго не заходить, закладка исчезнет. Чтобы этого не произошло, кликните по ней правой кнопкой мыши и укажите “Закрепить”. Если в браузере включена синхронизация, она “запомнит” и состояние визуальных букмарков. В отдельных случаях, когда ни один способ не помогает вернуть закладку, можно попробовать отыскать ее в сохраненной истории посещенных страниц.
Как удалить страницу из поисковой системы Google
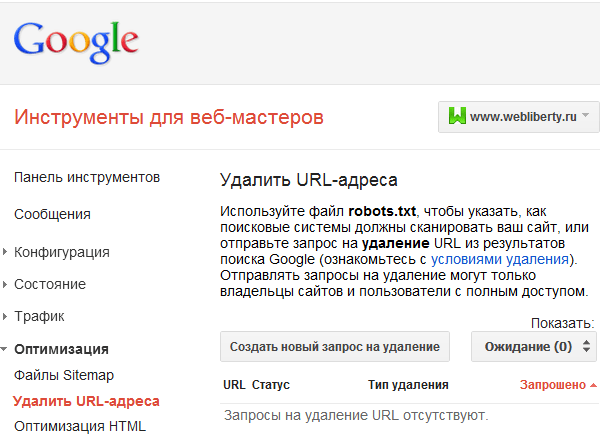
Перед нами специальная форма с помощью которой создаем новый запрос на удаление:
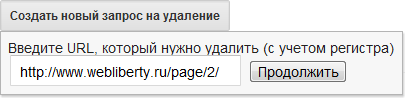
Нажимаем продолжить и следуя дальнейшим указаниям выбираем причину удаления. По-моему мнению слово «причина» не совсем подходит для этого, но это не суть…
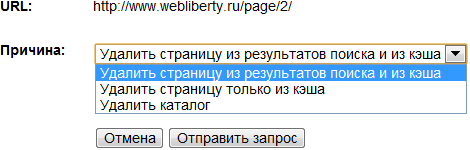
Из представленных вариантов нам доступно:
- удаление страницы страницы из результатов поиска Google и из кэша поисковой системы;
- удаление только страницы из кэша;
- удаление каталога со всеми входящими в него адресами.
Очень удобная функция удаления целого каталога, когда приходится удалять по несколько страниц, например из одной рубрики. Следить за статусом запроса на удаление можно на этой же странице инструментов с возможностью отмены. Для успешного удаления страниц из Google
необходимы те же условия, что и для . Запрос обычно выполняется в кратчайшие сроки и страница тут же исчезает из результатов поиска.
Сниппет — это блок с информацией о найденном документе. Он может состоять из следующих элементов:
«,»hasTopCallout»:true,»hasBottomCallout»:true,»areas»:,»alt»:»Заголовок»,»coords»:,»isNumeric»:false,»hasTopCallout»:true,»hasBottomCallout»:false},{«shape»:»circle»,»direction»:,»alt»:»Фавиконка»,»coords»:,»isNumeric»:false,»hasTopCallout»:false,»hasBottomCallout»:true},{«shape»:»circle»,»direction»:,»alt»:»Адрес документа»,»coords»:,»isNumeric»:false,»hasTopCallout»:true,»hasBottomCallout»:false},{«shape»:»circle»,»direction»:,»alt»:»Значки-подсказки»,»coords»:,»isNumeric»:false,»hasTopCallout»:true,»hasBottomCallout»:false},{«shape»:»circle»,»direction»:,»alt»:»Аннотация документа (сайта)»,»coords»:,»isNumeric»:false,»hasTopCallout»:false,»hasBottomCallout»:true},{«shape»:»circle»,»direction»:,»alt»:»Быстрые ссылки»,»coords»:,»isNumeric»:false,»hasTopCallout»:false,»hasBottomCallout»:true},{«shape»:»circle»,»direction»:,»alt»:»Дополнительная информация»,»coords»:,»isNumeric»:false,»hasTopCallout»:true,»hasBottomCallout»:false}]}}\»>
Механический метод удаления
Есть два основных типа особых приложений, предуготовленных для удаления программ. К первому типу относятся типовые деинсталляторы Windows, ко второму – деинсталляторы, которые установил сам пользователь. Дабы воспользоваться первым типом приложений, войдите в меню «Пуск», «Все программы», «Internet Explorer» и нажмите удалить либо в некоторых случаях деинсталлировать. Появится окно, жмите «Дальше» вплотную до происхождения прогресс-бара, тот, что свидетельствует о начале процедуры удаления. Примерно такой же алгорифм дозволено применять, если удалять браузер через «Панель управления». Войдите в панель, щелкните по иконке «Программы и компоненты». Откроется окно с перечнем программ, установленных на компьютере. Из них выберите «Internet Explorer», жмите удалить. Как и в предыдущем случае в правом нижнем углу клик мышкой по «Дальше» и обозреватель удалится. Перед тем как воспользоваться вторым типом деинсталляторов, установите один из них на ПК. Позже установки, перезагрузите девайс и откройте приложение. Оно выдаст все программы, которые устанавливались пользователем. Из них предпочтете, соответственно, «Internet Explorer» и щелкните «Деинсталлировать». Плюсом такой программы является то, что она не примитивно стирает приложение с компьютера, но и подчищает так называемые «хвосты» в реестре. От удаленного приложения не останется ни следа, как словно его и не устанавливали. Это, разумеется, правильно влияет на систему. Поменьше вероятности происхождения ошибок. Основной недочет – в основном все эти программы требую вступления лицензионного ключа и многие на английском языке. Если с языком хоть как то дозволено будет разобраться, то поиск бесплатного ключа в интернете – задачка трудоемкая, а его неимение вполовину уменьшает рабочий потенциал программы, либо просто делает ее неработоспособной.