WordPress seo: создание файла robots.txt. использование тега meta robots. xml-карта сайта
Содержание:
- Дополнительные директивы robots.txt
- Understanding Robots Meta Tag Attributes and Directives
- Влияние внутренних ссылок на индексацию сайта
- Атрибуты¶
- Другие метатеги
- Как закрыть внешние ссылки от индексации
- Мета тег title
- Robots.txt & Meta Robots Tags Work Together
- Директивы Meta Robots, которые стоит использовать в SEO
- Which search engine supports which robots meta tag values?
- Метатеги для поисковых систем
- В чем разница rel=nofollow и
- NOFOLLOW в ссылках
Дополнительные директивы robots.txt
-
Clean-Param: указывается параметр URL (можно несколько), страницы с которым нужно исключить из индекса и не индексировать
Данная директива используется только для User-agent: Yandex ! В Google параметр URL можно указать в Search Console или же использовать канонические ссылки (rel=»canonical»).
Clean-Param позволит избавиться от дублей страниц, которые возникают в результате генерации динамических URL (реферальные ссылки, сессии пользователей, идентификаторы и т.д.).
К примеру, если у вас на сайте появилось много страниц такого типа:И вы хотите, чтобы робот индексировал только www.mywebsite.com/testdir/index.php
Создаем правило для очистки параметров «id», «catid» и «Itemid», например:
Можно так же создать правило очистки параметров URL не только для определенной страницы, но и для всего сайта. Например, создать правило очистки UTM-меток: -
Crawl-delay: указывается время задержки в секундах между сканированием страниц
Данная директива полезна, если у вас большой сайт на слабом сервере и каждый день добавляется большое количество материалов. Поисковики при этом сразу же начинают индексировать сайт и создают нагрузку на сервер. Чтобы сайт не упал, задаем тайм-аут в несколько секунд для поисковиков — то есть задержка для перехода от одной к следующей странице.
Пример:
Таким образом, только через три секунды краулер перейдет к индексированию следующей страницы.
-
Sitemap: указываетcя полный путь к XML карте сайта
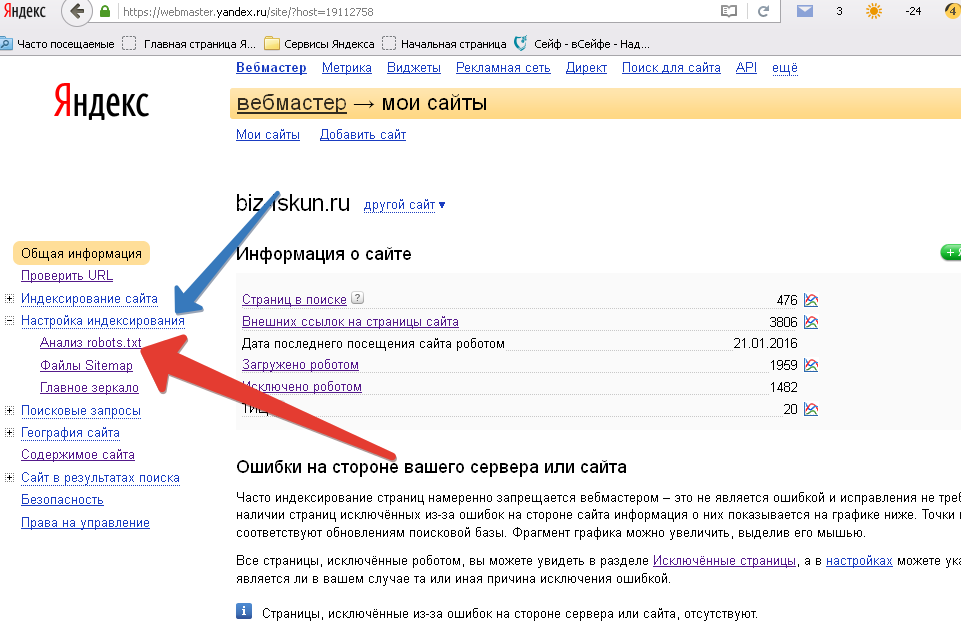
Данная директива сообщает ботам, что у сайта есть карта сайта, что поможет ботам быстро обнаруживать новые страницы при индексации. Если сайт часто наполняется, это особенно актуально, так как ускорит и улучшит индексацию (напомню, вы можете проверить индексацию страницы в нашем сервисе).
Пример: -
Host: указывается главное «зеркало» сайта, то есть его предпочтительная версия
Например, сайт доступен по http и https версии, чтобы краулер не запутался в “зеркалах” при индексации и не наделал дублей, указываем главный домен в директиве Host.Данная директива используется только для User-agent: Yandex
Пример:
Если сайт не на https, тогда указываем домен без протокола http: mywebsite.comПримечание: 20 марта 2018 года Яндекс заявил, что директива Host не обязательна, и вместо нее можно теперь использовать 301-й редирект.
Understanding Robots Meta Tag Attributes and Directives
Using robots meta tags is quite simple once you understand how to set the two attributes: name and content. Both of these attributes are required, so you must set a value for each.
Let’s take a look at these attributes in more detail.
Name
The name attribute controls that crawlers and bots (user-agents, also referred to as UA) should follow the instructions contained within the robots meta tag.
To instruct all crawlers to follow the instructions, use:
name=»robots»
In most scenarios, you’ll want to use this as default, but you can use as many different meta robots tags as needed to specify instructions to different crawlers.
When instructing different crawlers, it’s simply a case of using multiple tags:
There are hundreds of different user-agents. The most common ones are:
- : Googlebot (you can see a full list of Google crawlers here)
- Bing: Bingbot (you can see a full list of Bing crawlers here)
- DuckDuckGo: DuckDuckBot
- Baidu: Baiduspider
- Yandex: YandexBot
Content
The content attribute is what you use to give the instructions to the specified user-agent.
It’s important to know that if you do not specify a meta robots tag on a web page, the default is to index the page and to follow all of the links (unless they have a rel=»nofollow» attribute specified inline).
The different directives that you can use includes:
- index (include the page in the index) [Note: you do not need to include this if noindex is not specified, it is assumed as index)
- noindex (do not include the page in the index or show on the SERPs)
- follow (follow the links on the page to discover other pages)
- nofollow (do not follow the links on the page)
- none (a shortcut to specify noindex, nofollow)
- all (a shortcut to specify index, follow)
- noimageindex (do not index the images on the page)
- noarchive (do not show a cached version of the page on the SERPs)
- nocache (this is the same as noarchive, but only for MSN)
- nositelinkssearchbox (do not show a search box for your site on the SERPs)
- nopagereadaloud (do not allow voice services to read your page aloud)
- notranslate (do not show translations of the page on the SERPs)
- unavailable_after (specify a time after which the page should not be indexed)
You can see a full list of the directives that Google supports here and the ones that Bing supports here.
Влияние внутренних ссылок на индексацию сайта
Внутренние ссылки являются основной и практически единственной причиной того, что нам приходится закрывать ненужные и попавшие в индекс страницы разными метатегами и директивами robots.txt. Однако реальность такова, что ненужные роботам страницы очень даже нужны пользователям сайта, а следовательно должны быть и ссылки на эти самые страницы.
А что же делать? При любом варианте запрета индексации ссылок (rel=”nofollow”) и страниц (robots.txt, meta robots), вес сайта просто теряется, утекает на закрытые страницы.
Вариант №1. Большинство распространенных CMS имеют возможность использования специальных тегов (в DLE точно это есть, я сам этим очень активно пользуюсь) при создании шаблонов оформления, которые позволяют регулировать вывод определенной информации. Например, показывать какой-либо текст только гостям или группе пользователей с определенным id и т.д. Если таких тегов вдруг нет, то наверняка на помощь придут логические конструкции (такие конструкции есть в WordPress, а так же форумных движках IPB и vbulletin, опять же, я сам пользуюсь этими возможностями), представляющие из себя простейшие условные алгоритмы на php.
Так вот, логично было бы скрывать неважные и ненужные ссылки от гостей (обычно эту роль играют и роботы при посещении любого сайта), а так же скрывать ссылки на страницы, которые выдают сообщение о том, что вы не зарегистрированы, не имеете прав доступа и все такое. При необходимости можно специально для гостей выводить блок с информацией о том, что после регистрации у них появится больше прав и возможностей, а значит и соответствующие ссылки появятся 😉
Но бывают такие моменты, что ссылку нельзя скрыть или удалить, потому что она нужна, и нужна сразу всем – гостям, пользователям… А вот роботам не нужна. Что делать?
Вариант №2. В редких случаях (хотя последнее время все чаще и чаще) бывает необходимо, чтобы ссылки или даже целые блоки сайта были недоступны и невидны роботам, а вот людям отображались и работали в полной мере, вне зависимости от групп и привилегий. Вы уже, наверное, догадались, что я говорю про сокрытие контента при помощи JavaScript или AJAX. Как это делается технически, я не буду расписывать, это очень долго. Но есть замечательный пост Димы Dimox’а о том, как загрузить часть контента с помощью AJAX на примере WordPress (линк). В примере рассказывается про подгрузку целого сайдбара, но таким же методом можно подгрузить одну только ссылку, например. В общем, немного покопаетесь и разберетесь.
Так вот, если хочется какую-то часть контента роботам не показывать, то лучший выбор – JavaScript. А после того как провернете всю техническую часть, проверить это на работоспособность поможет замечательный плагин для FireFox под названием QuickJava. Просто с помощью плагина отключите для браузера обработку яваскрипта и перезагрузите страницу, весь динамически подгружаемый контент должен пропасть 😉 Но помните, что тут тоже надо знать меру!
И, кстати, еще парочка интересных моментов, которые необходимо знать:
Яндексу в индексации сайтов помогает Яндекс.Метрика, которая автоматически пингует в индекс все посещенные страницы, на которых установлен код Метрики. Но эту функцию можно отключить при получении кода счетчика, установив соответсвующую галочку.
Возможно как то в индексации замешаны Яндекс.Бар и сборка браузера Хром от Яндекса, но в этом я не уверен.
Но вот для Гугла есть информация, что роль поискового робота выполняет сам браузер Google Chrome. Такие уж они хитрецы.
Так что, как видим, скрыть информацию от роботов почти невозможно, если не предпринимать специальные меры.
Атрибуты¶
- Задаёт кодировку документа.
- Устанавливает значение атрибута, заданного с помощью или .
- Предназначен для конвертирования метатега в заголовок HTTP.
- Имя метатега, также косвенно устанавливает его предназначение.
charset
Указывает кодировку документа. Атрибут введён в HTML5 и предназначен для сокращения формы , которая задавала кодировку в предыдущих версиях HTML и XHTML.
Синтаксис
Значения
Название кодировки, например UTF-8.
Значение по умолчанию
Нет.
content
устанавливает значение атрибута, заданного с помощью или . Атрибут может содержать более одного значения, в этом случае они разделяются запятыми или точкой с запятой.
Некоторые значения атрибута для , предназначенных для поисковых роботов, приведены в табл. 1.
| Значение | Описание |
|---|---|
| Разрешает роботу индексировать данную страницу. | |
| Запрещает роботу индексировать текущую страницу. Она не попадает в базу поисковика и её невозможно будет найти через поисковую систему. | |
| Разрешает роботу переходить по ссылкам на данной странице. | |
| Запрещает роботу переходить по ссылкам на данной странице. При этом всем ссылкам не передаётся ТИЦ (тематический индекс цитирования) и PagePank. | |
| Запрещает роботу кэшировать данную страницу. |
Допустимые значения атрибута для , которые предназначены для управления просмотром сайта на мобильных устройствах, приведены в табл. 2.
| Значение | Допустимые значения | Описание |
|---|---|---|
| device-width или целое положительное число | Устанавливает ширину области просмотра в пикселях. | |
| device-height или целое положительное число | Устанавливает высоту области просмотра в пикселях. | |
| Число от 0.0 до 10.0 | Устанавливает соотношение между шириной устройства (device-width в портретном режиме или device-height в ландшафтном режиме) и размером области просмотра. | |
| Число от 0.0 до 10.0 | Задаёт максимальное значение масштаба. Должно быть больше или равно minimum-scale, в противном случае игнорируется. | |
| Число от 0.0 до 10.0 | Задаёт минимальное значение масштаба. Должно быть меньше или равно maximum-scale, в противном случае игнорируется. | |
| yes или no | Если указано no, то пользователь не сможет масштабировать веб-страницу. По умолчанию используется yes. |
Синтаксис
Значения
Строка символов, которую надо взять в одинарные или двойные кавычки.
Значение по умолчанию
Нет.
http-equiv
Браузеры преобразовывают значение атрибута , заданное с помощью , в формат заголовка ответа HTTP и обрабатывают их, как будто они прибыли непосредственно от сервера.
Синтаксис
Значения
Любой подходящий идентификатор. Ниже приведены некоторые допустимые значения атрибута .
- Тип кодировки документа.
Устанавливает дату и время, после которой информация в документе будет считаться устаревшей.
Способ кэширования документа.
- Загружает другой документ в текущее окно браузера.
Значение по умолчанию
Нет.
name
Устанавливает идентификатор метатега для пары «». Одновременно использовать атрибуты и не допускается.
Синтаксис
Значения
Любой подходящий идентификатор. Ниже приведены некоторые допустимые значения атрибута .
- Имя автора документа.
- Описание текущего документа.
- Список ключевых слов, встречающихся на странице.
- Управляет просмотром сайта на мобильных устройствах.
Значение по умолчанию
Нет.
Другие метатеги
Верификация
Для подтверждения права собственности на сайт и возможности управлять им в Вебмастере Яндекса или Search Console в Google можно использовать особые метатеги верификации google-site-verification и yandex-verification (или иной способ).
Viewport
Метатег нужен для адаптации к мобильным устройствам, контролирует масштаб видимой области просмотра в браузере. Без него отображение некорректное.
Http-equiv
Принимаемые значения:
- Content-Type – помогает определить кодировку и тип документа;
- Refresh – перенаправление на другую страницу после заданного в секундах времени нахождения;
- Content-Language – указание основного языка документа.
Тег указывает браузеру, на основании каких данных нужно обработать содержание документа.
Как закрыть внешние ссылки от индексации
Для того чтобы запретить к индексации текстовые фрагменты, на сайте нужно использовать тег noindex
Важно знать, что этот тег способен закрывать только текстовые блоки. Картинки, баннеры, и другие элементы запретить к индексации с помощью этого тега нельзя
Многие люди совершают большую ошибку, когда заключают в этот тег ссылку. Поисковая система без проблем считывает и индексирует ссылку. В этом случае запрещён к индексации только анкор ссылки, так как это текст. Будьте внимательны.
Тег noindex прописывается в исходный код сайта. Имеет открывающий и закрывающий тег. Текст помещается между этими тегами.
Теперь подробнее:
Этот текст поисковые системы не отдадут на индексацию. А также тег noindex может выступать в роли метатега, который расположен в начале страницы и он отличается в корне. Если на странице расположен метатег noindex, в этом случае он запрещает индексирование всей страницы. При этом не только тексты, но и все что на ней находится – ссылки, картинки, баннеры, формы и так далее, всё это будет запрещено к индексации. Лучше всего для запрета индексация целых страниц использовать специальный файл robots.txt.
Как правильно ставить тег noindex
Вначале можно прочитать, что тег noindex создан исключительно для поисковых машин. То есть этот тег не является официальным тегом языка html. Именно поэтому HTML-редакторы могут показывать, что тег написан с ошибкой. Не пугайтесь, это происходит по причине того, что они просто не понимают этот тег и не считают его валидным. Но, так или иначе, его без проблем прочитают поисковые машины.
И ещё важно знать и запомнить, на тег noindex будет реагировать только поисковая система Яндекс, так как он его и создал. Поисковая система Google не реагирует на такой тег вообще.. Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега
Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже
Многие начинающие SEO-оптимизаторы допускают одну и ту же ошибку, а именно пытаются запретить к индексации ссылку с помощью этого тега. Для того чтобы скрыть ссылку от индексации нужно использовать другой тег – nofollow, об этом ниже.
Владельцам сайта не запрещается манипулировать тегами, можно не смотреть за их вложенностью, noindex будет работать при любом раскладе. Об этом пишет сам Яндекс. Главное, быть внимательным при работе с этими тегами, так как если вы забудете поставить закрывающий тег, схема работать не будет. В этом случае поисковая система Яндекс проиндексирует и отдаст всё что есть на странице в выдачу.
Как скрыть ссылки от индексации
В случае когда в тег ссылки добавить отдельный, дополнительный атрибут rel=”nofollow”, это будет означать, что ссылка не будет проиндексирована поисковым роботом. Вот пример как это выглядит в коде HTML:
Этот параметр очень важен для тех сайтов, которые не хотят делиться весом своего ресурса с другими WEB-проектами
Но также важно запомнить, что он не оставляет этот вес и у себя, по сути, он просто сгорает и не достаётся никому
Если же ссылку использовать без этого тега nofollow, то вес страницы, через эту ссылку уйдёт на другой сайт
Исходя из этого, важно понимать, что если внести этот атрибут во все ссылки, которые уходят на другие сайты, сайт потеряет в весе
Как работает этот атрибут nofollow на примере:
Конечно, если ссылка ссылается на страницу в рамках одного сайта или блога, то проставлять это свойство бесполезно и даже вредно. Это можно использовать только в тех случаях, когда стоит задача не передавать вес отдельным страницам сайта. Например, если есть продающая страница, куда должен поступать весь трафик, имеет ссылку на внутреннюю страницу, например, ответы на вопросы, то, конечно, лучше эту ссылку поместить в атрибут nofollow.
Как использовать тег noindex и nofollow одновременно
Данные теги не конфликтуют между собой, поэтому совершенно спокойно можно использовать их одновременно на одной странице или участке текста. В этом случае и текст и ссылка не будет доступна к индексации
Но важно не забывать, что текст будет скрыт только для поисковой системы Яндекс
На этом сегодня всё, всем удачи и до новых встреч!
Мета тег title
Например, если вы посмотрите HTML-код этой страницы, то увидите, что заголовок выглядит следующим образом:
Теги заголовков помещаются в <head> вашей веб-страницы и предназначены для предоставления чёткого и исчерпывающего представления о том, о чём эта страница. Но имеют ли они такое же сильное влияние на позиции в выдаче, как это было много лет назад?
В последние несколько лет идёт активное обсуждение поведенческих факторов, как логического доказательства релевантности и, следовательно, сигнала ранжирования – даже представители поисковых систем периодически признают их влияние.
Заголовок страницы по-прежнему является первым, что пользователь видит в поисковой выдаче и решает, отвечает ли страница поисковому запросу. Правильно написанный title может значительно увеличить количество кликов по сниппету и трафик на сайт, что, безусловно, влияет на ранжирование.
Простой эксперимент показывает, что Гуглу больше не нужен ваш тайтл, включающий ключ с точным соответствием, чтобы понять тему страницы. Например, несколько лет назад выдача Гугла по запросу «как повысить узнаваемость бренда» очень сильно походила на то, что вы можете наблюдать сейчас в Яндексе:
Всего 1 заголовок из всего топа не включает точное соответствие. А теперь давайте взглянем на Google:
Всего 1 заголовок из всего топа включает точное соответствие. Но при этом в Гугле нет ни одного неуместного результата: каждая, из приведённых здесь страниц, объясняет, как повысить узнаваемость, и заголовки это отражают.
Поисковые системы смотрят на общую картину и обычно оценивают содержание страницы в целом, но «обложка книги» всё ещё имеет значение, особенно, когда речь идёт о взаимодействии с пользователями.
Как правильно заполнять title
- Сделайте для каждой страницы уникальный заголовок, который кратко и точно описывает её контент.
- Если хотите, чтобы заголовки не обрезались в поисковой выдаче, лучше ограничивать их 50-60 символами. В Google длинные заголовки сокращаются, примерно, до 600-700 пикселей, но эти цифры иногда меняются, так что не стоит их жёстко придерживаться.
- Главные ключевые слова должны стоять как можно ближе к началу заголовка. Но вставляйте их максимально органично, как будто вы это делаете для посетителей сайта.
- Используйте название вашего бренда в названии, даже если оно не отображается в поисковой выдаче, это всё равно будет иметь значение для поисковой системы.
Совет: используйте title для привлечения внимания
Тег заголовка ценен не только потому, что он является основным элементом поисковой выдачи, но и потому, что он действует, как заголовок вкладки в вашем веб-браузере. Это можно использовать для привлечения внимания пользователя. Например:
Такой подход используют социальные сети: ВКонтакте, Facebook, LinkedIn, чтобы показать вам, что имеются новые уведомления. Эта тактика может дать весьма неплохой результат!
Robots.txt & Meta Robots Tags Work Together
One of the biggest mistakes I see when working on my client’s websites is when the robots.txt file doesn’t match what you’ve stated in the meta robots tags.
For example, the robots.txt file hides the page from indexing, but the meta robots tags do the opposite.
Remember the example from Leadfeeder I showed above?
So, you’ll notice that this thank you page is disallowed in the robots.txt file and using the meta robots tags of noindex, nofollow.
In my experience, Google has given priority to what is prohibited by the robots.txt file.
But, you can eliminate non-compliance between meta robots tags and robots.txt by clearly telling search engines which pages should be indexed, and which should not.
Директивы Meta Robots, которые стоит использовать в SEO
Как мы видим из предыдущей таблицы, не все атрибуты метатега Robots поддерживаются поисковой системой Google, под которую оптимизируют сайты большинство разработчиков и SEO-специалистов. Поэтому рассмотрим те атрибуты метатега Robots, которые поддерживаются Google:
- nosnippet,
- noimageindex,
- noarchive,
- unavailable_after.
Все они прописываются в блоке страницы, к которой вы хотите применить те или иные инструкции по индексации.
Nosnippet
Для решения проблемы вам следует использовать инструкцию следующего вида:
Также важно учитывать, что атрибут nosnippet отключает и отображение расширенных сниппетов в результатах поиска. К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов
Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц
К тому же, исследование HubSpot показало, что сниппеты с расширенной информацией получают в два раза больше кликов. Соответственно, отключение сниппета может стать причиной снижения CTR вашего сайта или отдельных его страниц.
Noimageindex
Директива noimageindex позволит скрыть графический контент на вашем сайте из результатов поиска по картинкам. Это может быть полезно, если вы, к примеру, хотите разместить на своём блоге уникальные изображения и при этом минимизировать риск воровства.
Чтобы запретить поисковым системам индексировать изображения, задайте в блоке html-документа следующую директиву:
Действие необходимо повторить с каждой страницей, которая содержит изображения, которые вы хотите скрыть от поисковиков. Учитывайте, что если другие сайты уже ссылались на ваши изображения, поисковики могут продолжать индексировать их.
Запрещая индексацию изображений, не забывайте о том, что поиск по картинкам может приносить хороший дополнительный трафик вашему сайту.
Noarchive
Вопреки распространённому мнению, директива noarchive никак не влияет на ранжирование — эту информацию подтвердил в своем Твиттере ведущий аналитик компании Google, специалист отдела качества поиска по работе с вебмастерами Джон Мюллер (John Mueller).
Директива unavailable_after наиболее актуальна для страниц с акционными предложениями. Так как по истечению времени действия акции они теряют свою актуальность, вы можете указать поисковикам дату крайнего срока индексации контента. Дату и время нужно указывать в формате RFC 850.
К примеру, если вам нужно исключить возможность индексации страницы после 25 марта 2019 года, используйте метатег следующего вида:
Отдельно отметим, что для правильного функционирования тега необходимо, чтобы он был прописан до первого обхода роботом. В таком случае запрос на удаление из поисковой выдачи займёт примерно сутки после указанной даты.
Which search engine supports which robots meta tag values?
This table shows which search engines support which values. Note that the documentation provided by some search engines is sparse, so there are many unknowns.
| Robots value | Yahoo | Bing | Ask | Baidu | Yandex | |
|---|---|---|---|---|---|---|
| Indexing controls | ||||||
| index | Y* | Y* | Y* | ? | Y | Y |
| noindex | Y | Y | Y | ? | Y | Y |
| noimageindex | Y | N | N | ? | N | N |
| Whether links should be followed | ||||||
| follow | Y* | Y* | Y* | ? | Y | Y |
| nofollow | Y | Y | Y | ? | Y | Y |
| none | Y | ? | ? | ? | N | Y |
| all | Y | ? | ? | ? | N | Y |
| Snippet/preview controls | ||||||
| noarchive | Y | Y | Y | ? | Y | Y |
| nocache | N | N | Y | ? | N | N |
| nosnippet | Y | N | Y | ? | N | N |
| nositelinkssearchbox | Y | N | N | N | N | N |
| nopagereadaloud | Y | N | N | N | N | N |
| notranslate | Y | N | N | ? | N | N |
| max-snippet: | Y | Y | N | N | N | N |
| max-video-preview: | Y | Y | N | N | N | N |
| max-image-preview: | Y | Y | N | N | N | N |
| Miscellaneous | ||||||
| rating | Y | N | N | N | N | N |
| unavailable_after | Y | N | N | ? | N | N |
| noodp | N | Y** | Y** | ? | N | N |
| noydir | N | Y** | N | ? | N | N |
| noyaca | N | N | N | N | N | Y |
* Most search engines have no specific documentation for this, but we’re assuming that support for excluding parameters (e.g., ) implies support for the positive equivalent (e.g., ).** Whilst the noodp and noydir attributes may still be ‘supported’, these directories no longer exist, and it’s likely that these values do nothing.
Метатеги для поисковых систем
Robots
Метатег указывает роботам поисковых систем, как сканировать и индексировать страницу.
Для конкретного бота можно задать свою инструкцию. Например, заменить robots на Googlebot для Гугла или на YandexBot для Яндекса.
Возможные указания:
- all – означает, что разрешена индексация и переход по ссылкам, аналогично index, follow;
- noindex – запрет индексации;
- index – разрешена индексация;
- nofollow – нельзя переходить по ссылкам;
- follow – можно переходить по ссылкам;
- noarchive – запрещено показывать ссылку на сохраненную копию в выдаче;
- noyaca – (для Яндекса) не использовать для сниппета описание из Яндекс.Каталога;
- nosnippet – (в Google) нельзя использовать для сниппета фрагмент текста и показывать видео;
- noimageindex – (в Google) запрет указания страницы как источника изображения;
- unavailable_after: – (в Google) после указанной даты будет прекращено сканирование и индексирование страницы;
- none – запрет индексации и перехода по ссылкам, аналогичен noindex, nofollow.
Description
Метатег name=«description» может использоваться поисковыми системами при формировании сниппета, поэтому он должен:
- точно описывать содержание страницы;
- вызывать желание кликнуть;
- включать продвигаемое ключевое слово.
В разных поисковых системах выводятся 160–240 символов.
Description для каждой продвигаемой страницы должен быть уникальным.
Keywords
Метатег name=«keywords» раньше использовался поисковыми системами при ранжировании, но из-за многочисленных манипуляций его значимость постоянно уменьшалась. Теперь большинство поисковиков его игнорируют. Google не поддерживает вообще, а Яндекс пишет, что может учитывать. Но на практике keywords давно не оказывает влияния, а его некорректное заполнение может привести к переспаму.
Существуют три подхода:
- оставлять пустым;
- писать конкретные фразы или отдельные слова через запятую;
- указать через пробел бессвязный набор слов, из которых могут быть составлены ключевые фразы.
Если принято решение прописать ключевые слова, важно не допускать спама. Ключевые слова должны характеризовать конкретную страницу и упоминаться в контенте
Ключевые слова должны характеризовать конкретную страницу и упоминаться в контенте.
Title
Title технически не является метатегом, но его часто относят к этой группе, потому что он содержит информацию, которая используется поисковыми системами и браузерами.
Данный HTML-тег важен для SEO: влияет на ранжирование и кликабельность по сниппету.
Классические рекомендации по заполнению метатега:
- использовать главное продвигаемое ключевое слово на странице;
- разместить ключ вначале;
- обеспечить уникальность внутри сайта;
- сделать привлекательным для пользователя;
- подобрать такую длину, чтобы заголовок не обрезался в сниппете.
Рекомендуема длина – 70–80 символов.
В чем разница rel=nofollow и
Так в чем же проблема?
Зачем Яндексу понадобилось вводить поддержку rel=»nofollow»?
тег <noindex> это личная инициатива Yandex
Атрибут со статусом rel=»nofollow» стандартизирован и используется во всем мире для указания поисковикам, что ссылка не одобрена автором и по ней не нужно следовать.
Например, если закрыть служебную страницу от индексации в robots.txt, а ссылку оставить открытой, робот проследует на данную страницу, но не проиндексирует ее. Зачем тогда тратить ресурсы робота на переходы по ненужным страницам? Еще есть один нюанс, если на вашу служебную страницу ведут открытые ссылки с других внешних источников, то ваша, как бы закрытая страница, попадет в поиск, даже если она закрыта в robots.txt. Об этом также расскажу в следующих статьях.
Исходя из всего этого, по многочисленным просьбам и жалобам веб-мастеров, Яндекс ввел поддержку стандартизированного W3C атрибута со статусом rel=»nofollow». Атрибут закрывает ссылки от переходов роботом и не передает вес. Теперь многое стало проще. Но есть один нюанс. Анкоры ссылок будут проиндексированы как текст.
NOFOLLOW в ссылках
Nofollow используется как значение атрибута rel в теге <a>. И отвечает за индексацию каждой конкретной ссылки на странице.
<a href=»url» rel=»nofollow»>ссылка</a>
Атрибут rel показывает отношение данного документа к документу, на который ссылается.
В данном случае, указывая атрибуту rel значение nofollow, мы просим поисковую систему не переходить по внешней ссылке, а также подчеркиваем то, что мы не отвечаем за содержание, на которое ссылаемся.
По ссылкам, оформленным с данным значением, не передается авторитет нашей страницы, другими словами не передается тИЦ и Page Rank. Однако стоит также учитывать и то, что в случае с PR вес все же уходит, но не на сайт, на который мы ссылаемся, а в никуда в прямом смысле этого слова. По поводу тИЦ точной информации о том, уходит вес или остается на сайте — нет.
Остановимся подробнее на распределении и передаче веса в Google.
Итак, абсолютно не важно, сколько ссылок у вас имеют атрибут rel=»nofollow», а сколько без него. Если на странице стоит 10 ссылок, то каждая ссылка получит часть авторитета вашей страницы, и каждая из них передаст этот вес, но если в одном случае вес передастся на конкретный сайт, то в другом случае – вес просто уйдет в никуда
Давайте представим немного, как видит всемирную паутину поисковая система. Все сайты связаны между собой ссылками, абсолютно все. Первый ссылается на второй, второй на третий … тысячный на тысяча первый и миллион какой-то в итоге обязательно будет ссылаться на первый.
Таким образом цепочка замыкается, все сайты находятся в цикле, и вес, который передает первый сайт всегда возвращается к нему через сотни и тысячи других сайтов. Также не забываем, и я уже писала об этом в статье про перелинковку, что этот вес передается не единожды, а постоянно, при этом с течением времени вес становится только больше, все сильнее увеличивая свой авторитет. Именно на этом принципе строится перелинковка сайта.
Теперь представим, что первый сайт закрыл свои ссылки атрибутом rel=»nofollow». Вес не перейдет на второй сайт, а утечет в никуда, и второй сайт не получит ту часть веса, которую должен был, не сможет передать его дальше по цепочке, и в итоге, пройдя весь цикл, Х-какой-то сайт, который должен был передать вес на первый сайт, передаст его в значительно меньшем количестве, чем мог бы. Итак, каждый раз не получая ту часть веса, которую вы самостоятельно пускаете в никуда, закрывая свои ссылки атрибутом rel=»nofollow», сайт не может передать вам ее, из чего следует, что закрывая свои ссылки, вы сами лишаете себя увеличения веса, и такого показателя, как PR.
Чтобы было проще это понять, представим, что каждая ссылка передает вес, равным единице.
Таким образом, если первый сайт не закрыл ссылку атрибутом rel=»nofollow», то в конце цикла получит больший вес от входящих ссылок, чем в случае, если исходящие ссылки будут закрыты.
Но есть ситуации, когда действительно необходимо закрывать ссылки значением nofollow. Обратимся к источникам, Яндекс и Google, что они говорят по этому поводу?
Выдержка из раздела Помощь Яндекса:
Выдержка из раздела Справка Google:
Мы должны закрывать ссылки в тех разделах своего сайта, где любой пользователь может оставить свою ссылку, за которую мы не сможем поручиться, гарантировать, что там качественное содержание.
Также мне хотелось бы уделить внимание ещё одному моменту. Некоторые ярые борцы за закрытые ссылки ставят rel=»nofollow» не только в самих ссылках, т.е
в теге , но и везде, на что только хватает фантазии. И в теге
Давайте не будем выдумывать свои собственные стандарты, а обратимся к существующим, которые разрабатывает международная организация W3C.
Значение rel=»nofollow» можно использовать только в теге , и в других тегах его использовать нельзя!
Итак, мы выяснили, когда стоит пользоваться атрибутом ссылки rel=»nofollow», а когда это не целесообразно. Также мы больше не будем вставлять его никуда, кроме одного единственного тега, обозначающего ссылку
Теперь уделим внимание тегу noindex.