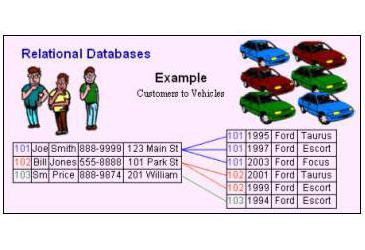
База данных
Содержание:
- Иерархическая база данных, структура иерархических данных
- Локальный кэш распределенной информации
- Сетевая модель данных
- Что такое база данных MySQL?
- Примечания
- От прошлого к настоящему
- Что такое СУБД и язык структурированных запросов SQL
- Проблемы использования баз данных
- Неопределенность смысла
- Как автономные технологии улучшают управление базами данных
- Преимущества и недостатки
- Проблемы определения
- История создания
- Объектно-ориентированные субд
- Объектно-реляционные субд
- Языки манипулирования данными
Иерархическая база данных, структура иерархических данных
Когда речь идёт о хранении иерархических данных, каждый объект хранит информацию в виде определенной сущности, и у каждой сущности могут быть родительские и дочерние элементы, а у дочерних, в свою очередь, тоже могут быть дочерние элементы. Таким образом, можно сказать, что это данные, которые подлежат строгой иерархии (представьте себе своеобразное дерево).
Простой пример иерархических данных — документ в формате XML либо файловая система компьютера.
Нельзя не упомянуть и то, что базы данных этого вида оптимизированы под чтение информации. При такой структуре данные можно быстро выбирать из нужной области, отдавая запрашиваемую информацию пользователям. Например, компьютер легко работает с конкретной папкой либо файлом, которые, по сути, можно назвать объектами структуры иерархических данных. Но когда нужно перебрать всю информацию, это может занять время (если вернуться к вышеописанному примеру, то проверка антивирусом всех уголков нашего компьютера выполняется не так быстро, как хотелось бы).
На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
Локальный кэш распределенной информации
В системе слежения за почтовыми отправлениями никогда не требуется доступ ко всей информации сразу. Это обычное явление во всех областях применения: есть вся накопленная и доступная информация, а есть та ее маленькая часть, которая актуальна на конкретный момент времени.
Ничто не мешает веб-ресурсу создать локальный образ распределенной базы данных. Например, пришел посетитель. Еще до того, как он сформулирует запрос, можно подгрузить варианты ответа.
Если есть опыт работы с посетителями из конкретной страны, то может быть известно, из каких стран ожидаются данные.
В некоторых странах система слежения загружена, в основном, локальными запросами (внутри страны), ничто не мешает оптимизировать этот момент, а внешние отправления отдать на откуп другим веб-ресурсам. В некоторых случаях необходимо не только предоставить посетителю внешнюю информацию, но и сопоставить сведения по ответу на один и тот же запрос от разных систем слежения.
Сказать, что в таком случае получится объектно-реляционная модель информации и доступа к ней в определенном смысле возможно, но для реализации этой модели потребуется представить инструмент моделирования действий компаний, работающих в области слежения, то есть развивающих свой функционал.
Сетевая модель данных
Стандарт
сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference
of Data System Languages), которая определила базовые понятия модели и формальный
язык описания.
Базовыми
объектами модели являются:
- элемент данных;
- агрегат данных;
- запись;
- набор данных,
Элемент данных
—
то же, что и в иерархической модели, то есть минимальная информационная
единица, доступная пользователю с использованием СУБД.
Агрегат данных
—
соответствует следующему уровню обобщения в модели. В модели определены
агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа.
Агрегат данных
имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа
вектор соответствует линейному набору элементов данных. Например, агрегат Адрес
может быть представлен следующим образом:
|
Адрес |
|||
|
Город |
Улица |
дом |
квартира |
Агрегат типа
повторяющаяся группа соответствует совокупности векторов данных. Например, агрегат
Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
|
Зарплата |
|
|
Месяц |
Сумма |
Записью называется
совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов
реального мира. Понятие записи соответствует понятию «сегмент» в
иерархической модели. Для записи, так же как и для сегмента, вводятся понятия
типа записи и экземпляра записи.
Следующим
базовым понятием в сетевой модели является понятие «Набор».
Набор
—
это двухуровневый граф, связывающий отношением «один-ко-многим» два типа записи.
Набор фактически
отражает иерархическую связь между двумя типами записей. Родительский тип записи
в данном наборе называется владельцем набора, а дочерний тип записи — членом
того же набора.
Для любых
двух типов записей может быть задано любое количество наборов, которые их связывают.
Фактически наличие подобных возможностей позволяет промоделировать отношение
«многие-ко-многим» между двумя объектами реального мира, что выгодно
отличает сетевую модель от иерархической. В рамках набора возможен последовательный
просмотр экземпляров членов набора, связанных с одним экземпляром владельца
набора.
Между двумя
типами записей может быть определено любое количество наборов: например, можно
построить два взаимосвязанных набора. Существенным ограничением набора является
то, что один и тот же тип записи не может быть одновременно владельцем и членом
набора.
В качестве
примера рассмотрим таблицу, на основе которой организуем два набора и определим
связь между ними:
|
Преподаватель |
Группа |
День недели |
№ пары |
Аудитория |
Дисциплина |
||
|
Иванов |
4306 |
Понедельник |
1 |
22-13 |
КИД |
||
|
Иванов |
4307 |
Понедельник |
2 |
22-13 |
КИД |
||
|
Карпова |
4307 |
Вторник |
2 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
4309 |
Вторник |
4 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
84305 |
Вторник |
1 |
22-14 |
БД |
||
|
Смирнов |
4306 |
Вторник |
3 |
23-07 |
ГВП |
||
|
Смирнов |
4309 |
Вторник |
4 |
23-07 |
ГВП |
||
Экземпляров
набора Ведет занятия будет 3 (по числу преподавателей), экземпляром набора Занимается
у будет 4 (по числу групп). На рис. 3.6 представлены взаимосвязи экземпляров
данных наборов.
Рис.
3.6. Пример взаимосвязи экземпляров двух наборов
Среди всех
наборов выделяют специальный тип набора, называемый «Сингулярным набором»,
владельцем которого формально определена вся система. Сингулярный набор изображается
в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора,
но у которой не определен тип записи «Владелец набора». Например,
сингулярный набор М.
Сингулярные
наборы позволяют обеспечить доступ к экземплярам отдельных типов данных, поэтому
если в задаче алгоритм обработки информации предполагает обеспечение произвольного
доступа к некоторому типу записи, то для поддержки этой возможности необходимо
ввести соответствующий сингулярный набор.
В общем случае
сетевая база данных представляет совокупность взаимосвязанных наборов, которые
образуют на концептуальном уровне некоторый граф.
Что такое база данных MySQL?
MySQL — это система управления реляционными базами данных с открытым исходным кодом, основанная на SQL. Он был разработан и оптимизирован для веб-приложений и может работать на любой платформе. По мере появления в Интернете новых и различных требований MySQL стала предпочтительной платформой для веб-разработчиков и веб-приложений. Поскольку MySQL предназначен для обработки миллионов запросов и тысяч транзакций, он является популярным выбором для предприятий электронной коммерции, которым необходимо управлять несколькими денежными переводами. Гибкость по запросу — основная особенность MySQL.
MySQL — это СУБД, стоящая за некоторыми из ведущих веб-сайтов и веб-приложений в мире, включая Airbnb, Uber, LinkedIn, Facebook, Twitter и YouTube.
Примечания
«Следует отметить, что термин база данных часто используется даже тогда, когда на самом деле подразумевается СУБД. Такое обращение с терминами предосудительно». — К. Дж. Дейт. Введение в системы баз данных. — 8-е изд. — М.: «Вильямс», 2006, стр. 50.«Этот термин (база данных) часто ошибочно используется вместо термина ‘система управления базами данных’». — Когаловский М. Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002., стр. 460.«Среди непрофессионалов путаница возникает при использовании терминов „база данных“ и „система управления базами данных“. Мы будем строго разделять эти термины». —
Кузнецов С. Д. Основы баз данных: учебное пособие. — 2-е издание, испр. — М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2007, стр. 19.
↑ ГОСТ Р ИСО МЭК ТО 10032-2007: Эталонная модель управления данными (идентичен ISO/IEC TR 10032:2003 Information technology — Reference model of data management)
ГОСТ 33707-2016 (ISO/IEC 2382:2015) Информационные технологии (ИТ)
Словарь
↑ .
.
.
Важно понимать, что структурированность базы данных оценивается не на уровне физического хранения (на котором все данные представлены совокупностями битов или байтов), а на уровне некоторой логической модели данных.
↑
Riedewald M., Agrawal D., Abbadi A. Dynamic Multidimensional Data Cubes for Interactive Analysis of Massive Datasets // In: Encyclopedia of Information Science and Technology, First Edition, Idea Group Inc., 2005
ISBN 9781591405535
↑
От прошлого к настоящему
Нет смысла охватывать историю баз данных, цепляясь за любое сходство, поэтому моментом появления баз данных будет не античное время, а 60-е годы 20 века. Именно тогда компьютеры стали эффективным инструментом для коммерческих компаний, а организация COBASYL (COnference on DAta SYstems Language), создавшая в 1959 году язык COBOL и впоследствии наделив его возможностями для управления БД, помогла им управлять резко возросшими потоками информации.
К концу 60-х появилась первая сетевая модель данных, возникло понятие СУБД, а в 1974 году компания IBM стала работать над языком для System R. Так на свет появился SEQUEL (Structured English QUEry Language). Однако позже, когда стало известно, что такое название используется британской авиастроительной компанией, было решено немного сократить до привычного SQL.
С увеличением доступности компьютеров стали появляться ориентированные на простых пользователей БД (Paradox, RBASE 5000, RIM, Dbase III), API (ODBC, Excel, Access) и средства разработки (VB, Oracle Developer, PowerBuilder). Само-собой, тенденция охватила и интернет, на сегодняшний день эффективное взаимодействие с БД – негласное требование к любому ресурсу с более-менее динамической информацией.
Если говорить о компаниях, то на рынке установилось троевластие: практически вся власть в области баз данных распределена между IBM, Microsoft и Oracle.
Что такое СУБД и язык структурированных запросов SQL
Определение
Системы управления базами данных СУБД – специальные средства, включающие определенный язык программирования, предназначены для разработки программ или их систем, работающих с базами данных.
Распространенные СУБД:
- Oracle Database;
- MS SQL Server;
- MySQL (MariaDB);
- ACCESS в составе профессионального пакета Microsoft Office.
Современные системы обладают большими возможностями, а также способствуют разработке сложных программных комплексов.
Определение
SQL (SQL, Structured Query Language) — язык программирования структурированных запросов, применяемый в качестве эффективного способа сохранения данных, поиска их частей, обновления, извлечения из базы и удаления.
SQL представляет собой ключевой инструмент оптимизации и обслуживания базы данных. Возможности обработки охватывают:
- команды определения представлений;
- указания прав доступа, схем отношений;
- взаимодействие с другими языками программирования;
- проверку целостности;
- задание начала и завершения транзакций.
SQL отличается простотой и легкостью в изучении. Его применяют:
- разработчики баз данных, для обеспечения функциональности приложений;
- тестировщики, в ручном и автоматическом режиме;
- администраторы, с целью поддержки рабочих параметров среды.
Проблемы использования баз данных
Сегодняшние крупные корпоративные базы данных часто поддерживают очень сложные запросы и, как ожидается, дадут почти мгновенные ответы на эти запросы. В результате администраторы баз данных постоянно вынуждены использовать самые разные методы для повышения производительности. Вот некоторые общие проблемы, с которыми они сталкиваются:
Управление лавинообразно растущими объемами данных. Стремительный рост количества данных, поступающих от датчиков, подключенных компьютеров и десятков других источников, заставляет администраторов баз данных изо всех сил пытаться управлять и организовывать этот сложный массив данных своих компаний.
Обеспечение безопасности данных. В наши дни утечки данных происходят повсеместно, и хакеры становятся все изобретательнее
Как никогда важно, чтобы данные были в безопасности, но при этом были легко доступны для пользователей. Идти в ногу со спросом
В сегодняшней быстро меняющейся деловой среде компаниям необходим доступ в режиме реального времени к своим данным, чтобы поддерживать своевременное принятие решений и использовать новые возможности.
Управление и обслуживание базы данных и инфраструктуры. Администраторы баз данных должны постоянно следить за базой данных на предмет проблем и выполнять профилактическое обслуживание, а также применять обновления программного обеспечения и исправления. По мере того, как базы данных становятся более сложными, а объемы данных растут, компании сталкиваются с расходами на привлечение дополнительных специалистов для отслеживания и настройки своих баз данных.
Снятие ограничений на масштабируемость. Чтобы выжить, бизнесу необходимо расти, и вместе с ним должно расти и управление данными. Но администраторам баз данных очень сложно предсказать, какой объем ресурсов потребуется компании, особенно для локальных баз данных.
Решение всех этих проблем может занять много времени и может помешать администраторам баз данных выполнять более стратегические функции.
Неопределенность смысла
Есть данное: название страны. Его предполагаемое значение — РФ = Россия = Российская Федерация. Но это также ассоциация с СССР и 15 республиками. Есть и другие варианты по названиям разных стран. Индия = колония = связь с Англией. Америка = США = штаты = территория, открытая Колумбом = территория, где собрались представители других стран и образовали новую нацию, что спорно по многим причинам.
Слово, которое вовсе не имеет значения, может быть «адресом» в конкретное информационное пространство. Это повод для развития технологий баз данных. Одно данное, но у него так много смысла, что касается всей технологии и обязывает пересмотреть принципиальные моменты.
Формально тип, который указан в модели данных, не может быть строкой символов, числом или структурой данных. Если в нем сидит реальное значение, значит, в нем определяется смысл, а смысл — это динамика, а не фиксированная строка символов. Это фактор неопределенности, который обуславливает развитие каждой модели данных.
Как автономные технологии улучшают управление базами данных
Самоуправляемые базы данных (автономные) — это мощный тренд будущего — они предлагают интригующую возможность для организаций, которые хотят использовать лучшую доступную технологию баз данных без головной боли, связанной с запуском и эксплуатацией этой технологии.
Автономные базы данных используют облачные технологии и машинное обучение для автоматизации многих рутинных задач, необходимых для управления базами данных, таких как настройка, безопасность, резервное копирование, обновления и другие рутинные задачи управления. Автоматизация этих утомительных задач дает администраторам баз данных возможность выполнять более стратегическую работу. Возможности автономного управления, самозащиты и самовосстановления автономных баз данных готовы революционизировать способы управления и защиты своих данных компаниями, обеспечивая повышение производительности, снижение затрат и повышение безопасности.
https://youtube.com/watch?v=uHytMyRmVeM
Преимущества и недостатки
Надлежащие системы управления базами данных помогают получить лучший доступ к данным, а также оптимизировать управление ими. В свою очередь, точечный доступ помогает конечным пользователям быстро и эффективно обмениваться данными в рамках выполнения задач организации.
|
Год создания |
Преимущества |
Недостатки |
|
|
Иерархическая |
1960-й |
Очень быстрый доступ для чтения, четкая структура, технически простой. |
Исправлена структура в дереве, которая не допускает связи между деревьями. |
|
Сетевая |
Начало 1970-х |
Поддерживает несколько способов доступа к записи, без строгой иерархии. |
Плохой обзор с большими базами данных. |
|
Реляционная |
1970-й |
Простое, гибкое создание и редактирование, легко расширяемое, быстрый ввод в эксплуатацию, простое расширение, быстрый запуск, очень динамичный контекст. |
Неуправляемый с большими объемами данных, плохой сегментацией, атрибутами искусственного ключа, внешним интерфейсом программирования, плохо отражает свойства и поведение объектов. |
|
Ориентирована на объекты |
Конец 1980-х |
Лучшая поддержка объектноориентированных языков программирования, хранение мультимедийного контента. Поддерживает объектноориентированные языки программирования, позволяет хранить мультимедийный контент. |
Более низкая производительность с большими объемами данных, мало совместимых интерфейсов. |
|
Ориентирована на документы |
1980-е |
Соответствующие данные хранятся централизованно в независимых документах, свободной структуре, концепции мультимедиа, относится к классификации сущностей БД. |
Организационная работа относительно высока, часто требует навыков программирования. |
Проблемы определения
В литературе предлагается множество определений понятия «база данных», отражающих скорее субъективное мнение тех или иных авторов, однако общепризнанная единая формулировка отсутствует.
Определения из международных стандартов и национальных стандартов, разработанных на основе международных:
- База данных — совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных.
- База данных — совокупность данных, организованных в соответствии с концептуальной структурой, описывающей характеристики этих данных и взаимоотношения между ними, которая поддерживает одну или более областей применения.
Определения из авторитетных монографий:
- База данных — организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторой предметной области и используемая для удовлетворения информационных потребностей пользователей.
- База данных — некоторый набор перманентных (постоянно хранимых) данных, используемых прикладными программными системами какого-либо предприятия.
- База данных — совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации.
В определениях наиболее часто (явно или неявно) присутствуют следующие отличительные :
- БД хранится и обрабатывается в вычислительной системе.Таким образом, любые внекомпьютерные хранилища информации (архивы, библиотеки, картотеки и т. п.) базами данных не являются.
- Данные в БД логически структурированы (систематизированы) с целью обеспечения возможности их эффективного поиска и обработки в вычислительной системе.Структурированность подразумевает явное выделение составных частей (элементов), связей между ними, а также типизацию элементов и связей, при которой с типом элемента (связи) соотносится определённая семантика и допустимые операции.
- БД включает схему, или метаданные, описывающие логическую структуру БД в формальном виде (в соответствии с некоторой метамоделью).В соответствии с ГОСТ Р ИСО МЭК ТО 10032-2007, «постоянные данные в среде базы данных включают в себя схему и базу данных. Схема включает в себя описания содержания, структуры и ограничений целостности, используемые для создания и поддержки базы данных. База данных включает в себя набор постоянных данных, определённых с помощью схемы. Система управления данными использует определения данных в схеме для обеспечения доступа и управления доступом к данным в базе данных».
Из перечисленных признаков только первый является строгим, а другие допускают различные трактовки и различные степени оценки. Можно лишь установить некоторую степень соответствия требованиям к БД.
В такой ситуации не последнюю роль играет общепринятая практика. В соответствии с ней, например, не называют базами данных файловые архивы, Интернет-порталы или электронные таблицы, несмотря на то, что они в некоторой степени обладают признаками БД. Принято считать, что эта степень в большинстве случаев недостаточна (хотя могут быть исключения).
История создания
Базы данных (БД) представляют собой логически структурированные системы для электронного администрирования, которое производится с помощью системы управления базами данных (СУБД), добавив ее в репозиторий. Большинство БД можно открывать, редактировать и консультировать только с использованием конкретных приложений. По этим принципам выполняют классификацию БД. В 1960-х годах концепция электронной информационной базы стала разрабатываться как отдельный слой программного обеспечения между ОС и прикладной программой.
Идея системы электронных БД стала одним из наиболее актуальных нововведений в компьютерных разработках. Первыми моделями, которые были разработаны, были иерархические и сетевые базы данных. IBM в семидесятых произвела революцию в этом секторе, с разработкой модели реляционных БД. Наиболее успешными продуктами в то время были язык запросов БД Oracle SQL и преемники IBM, SQL/DS и DB2.
Объектно-ориентированные субд
Появление объектно-ориентированных СУБД вызвано потребностями программистов на ОО-языках, которым были необходимы средства для хранения объектов, не помещавшихся в оперативной памяти компьютера. Также важна была задача сохранения состояния объектов между повторными запусками прикладной программы. Поэтому, большинство ООСУБД представляют собой библиотеку, процедуры управления данными которой включаются в прикладную программу. Примеры реализации ООСУБД как выделеного сервера базы данных крайне редки.
Сразу же необходимо заметить, что общепринятого определения «объектно-ориентированной модели данных» не существует. Сейчас можно говорить лишь о неком «объектном» подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Структура
Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция — каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов — процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира;
наследование — подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков);
полиморфизм — различные объекты могут по разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы.
Целостность данных
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования возможность объявить некоторые поля данных и методы объекта как «скрытые», не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.
В объектно-ориентированных базах данных, в отличие от реляционных, хранятся не записи, а объекты. ОО-подход представляет более совершенные средства для отображения реального мира, чем реляционная модель, естественное представление данных. В реляционной модели все отношения принадлежат одному уровню, именно это осложняет преобразование иерархических связей модели «сущность-связь» в реляционную модель. ОО-модель можно рассматривать послойно, на разных уровнях абстракции. Имеется возможность определения новых типов данных и операций с ними.
В то же время, ОО-модели присущ и ряд недостатков:
осутствуют мощные непроцедурные средства извлечения объектов из базы. Все запросы приходится писать на процедурных языках, проблема их оптимизации возлагается на программиста;
вместо чисто декларативных ограничений целостности (типа явного объявления первичных и внешних ключей реляционных таблиц с помощью ключевых слов PRIMARY KEY и REFERENCES) или полудекларативных триггеров для обеспечения внутренней целостности приходится писать процедурный код.
Очевидно, что оба эти недостатка связаны с отсутствием развитых средств манипулирования данными. Эта задача решается двумя способами — расширение ОО-языков в сторону управления данными (стандарт ODMG), либо добавление объектных свойств в реляционные СУБД (SQL-3, а также так называемые объектно-реляционных СУБД).
Объектно-реляционные субд
Разница между объектно-реляционными и объектными СУБД: первые являют собой надстройку над реляционной схемой, вторые же изначально объектно-ориентированы. Главная особенность и отличие объектно-реляционных, как и объектных, СУБД от реляционных заключается в том, что О(Р)СУБД интегрированы с Объектно-Ориентированным (OO) языком программирования, внутренним или внешним как C++, Java. Характерные свойства OРСУБД:
- комплексные данные,
- наследование типа,
- объектное поведение.
Комплексные данные могут быть реализованы через постоянно-хранимые объекты (persistent objects). Создание комплексных данных в большинстве существующих ОРСУБД основано на предварительном определении схемы через определяемый пользователем тип (UDT — user-defined type). Используются также встроенные конструкторы составных типов, например массив (ARRAY).
Иерархия структурных комплексных данных предлагает дополнительное свойство, наследование типа. То есть структурный тип может иметь подтипы, которые используют все его атрибуты и содержат дополнительные атрибуты, специфицированные в подтипе.
Объектное поведение закладывается через описание программных объектов. Такие объекты должны быть сохраняемыми и переносимыми для обработки в базе данных, поэтому они называются обычно как постоянные (или долговременные) объекты. Внутри базы данных все отношения с постоянным программным объектом есть отношения с его объектным идентификатором (OID).
Объектно-реляционными СУБД являются, к примеру, широко известные Oracle Database, Microsoft SQL Server 2005, PostgreSQL, а также Sav Zigzag, IBM Cloudscape,
Языки манипулирования данными
Основное средство для общения с реляционными базами данных — язык структурированных запросов SQL.
Это декларативный язык. То есть инструкции в нём не идут одна за другой (не как в императивных языках). Каждый оператор SQL описывает только необходимое действие, а СУБД сама принимает решение, как его выполнить.
Например, чтобы выбрать все данные из таблицы Messages за 10.11.2020, делается запрос:
SELECT * FROM messages WHERE date = ‘10.11.2020’
Язык структурированных запросов делится на несколько частей (группы операторов) и позволяет:
- определять данные (DDL),
- манипулировать ими (DML),
- контролировать доступ к данным (DCL)
- и управлять транзакциями (TCL).
В SQL изначально нет средств для создания печатных отчётов, экранных форм и других инструментов для разработки программ. Хотя SQL сам по себе не является полноценным (Тьюринг-полным) языком программирования, но его стандарт позволяет создавать процедурные расширения. Они доводят его функциональность до полноценного языка программирования.
При этом синтаксис SQL в разных СУБД может различаться. Кое-где даже используются его отдельные диалекты, например:
- T-SQL — для работы с Microsoft SQL Server;
- на PL / SQL пишут хранимые процедуры и функции в Oracle;
- на PL / pgSQL — в PostgreSQL.