Что такое программный интерфейс или api?
Содержание:
- Введение
- Кнопка Run in Postman
- Что такое API
- API7:2019 Security Misconfiguration (Некорректная настройка параметров безопасности)
- Критика протокола и оргподходов Telegram. Часть 1, техническая: опыт написания клиента с нуля — TL, MT
- Стратегии документирования вложенных объектов
- API2:2019 — Broken User Authentication (Недостатки аутентификации пользователей)
- Dart на сервере
- Запросы на разных языках
- Отсутствие результата — тоже результат
- Прощай, Google Maps
- Избегайте двойных отрицаний
- Избегайте частичных обновлений
- Плюсы и минусы работы с API
- Уродливый API
- Что такое REST API?
- Работа с API — реальные примеры использования
- Примеры разделов “Начало работы”
- Используйте глобально уникальные идентификаторы
- Весь веб на 60+ FPS: как новый рендерер в Firefox избавился от рывков и подтормаживаний
Введение
Вы наверное безумец, если не согласны со следующим утверждением:
На сегодняшний день API – повсюду и уже стали привычной частью мира технологий, бизнеса в партнерском маркетинге и тем, без чего мы не сможем обойтись.
Однако, вам кажется, что вы не совсем понимаете что это такое.
Возможно, вам хотелось бы знать, какие приложения используются для API, как ими пользоваться, и как они будут влиять на работу аффилиатов в будущем?
Не беспокойтесь! Эта статья – то, чего вы так долго ждали!
Мы расскажем вам, что такое API, приведем примеры, объясним какие виды API существуют, и как вы можете использовать API в своей работе каждый день.
К концу прочтения статьи вы будете знатоком этой темы!
Хватит вступлений. Начнем, пожалуй!
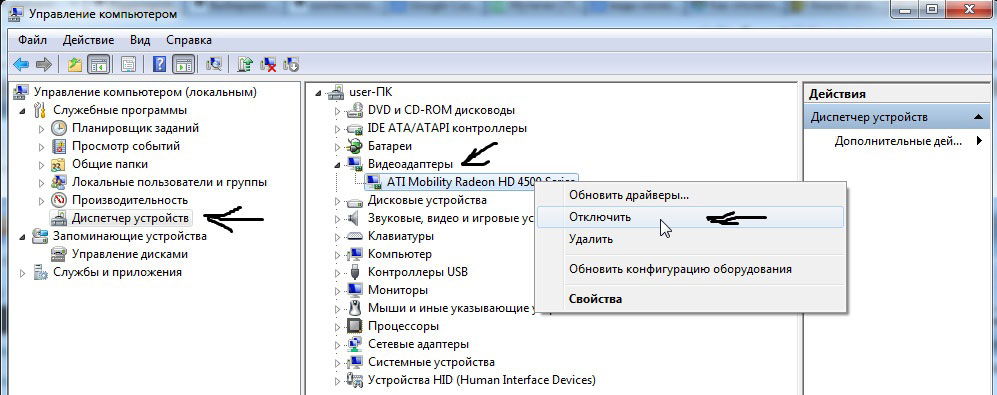
Кнопка Run in Postman
В разделе “Начало работы” можно рассмотреть возможность добавления кнопки . (Postman — это клиент REST API GUI, который мы изучили ранее в разделе .) Если есть , можно экспортировать свои коллекции Postman в виде виджета для встраивания в HTML-страницу.
это кнопка, которая при нажатии импортирует информацию об API в Postman, чтобы пользователи могли выполнять вызовы с помощью клиента Postman. Таким образом, кнопка позволяет импортировать интерактивный пробный интерфейс API для конечных точек на веб-страницу.
Чтобы добавить кнопку , можно или ввести информацию об API вручную. Стоит изучить раздел “Postman/docs”, как создать кнопку .
Множество демонстраций Run in Postman можно посмотреть здесь. Многие из этих демонстраций перечислены в сети API Postman.
 сеть API Postman
сеть API Postman
Вот демо с использованием конечной точки API OpenWeatherMap (с которой мы работали ):
Если нажать на кнопку, будет предложено открыть коллекцию в клиенте Postman:
 Вариант открытия коллекции
Вариант открытия коллекции
предоставляет мощный клиент REST API, с которым знакомы многие разработчики. Postman позволяет пользователям настраивать ключ и параметры API и сохранять эти значения. Хотя Postman не имеет возможности вызова в браузере, как в Swagger UI, во многих отношениях клиент Postman более полезен, поскольку позволяет пользователям настраивать и сохранять сделанные ими запросы. Postman — тот инструмент, который внутренние разработчики часто используют для хранения запросов API при тестировании и изучении функциональности.
Особенно, если ваши пользователи уже знакомы с Postman, является хорошим вариантом для пользователей, чтобы опробовать API, потому что он позволяет пользователям легко генерировать необходимый код для отправки запросов практически в любой язык. Это дает пользователям отправную точку, где они могут опираться на информацию для создания более подробных и настраиваемых вызовов.
Если в документации еще нет функции , кнопка предоставляет такую интерактивность простым способом, не требуя жертв со стороны единственного источника знаний для документации.
Недостатком является то, что в Postman не попадают описания параметров и конечных точек. Кроме того, если пользователи незнакомы с Postman, им может быть трудно понять, как им пользоваться. Редакторы , которые запускаются непосредственно в браузере, как правило, более просты и лучше интегрируют документацию.
Что такое API
В общем, API (Application Programming Interface) обеспечивает взаимодействие между двумя системами. Это как винтик, связывающий две детали, или как шестеренка, при помощи которой приводятся в движение две соседние шестеренки (как на картинке ниже).
API — как шестеренка, приводящая в движение две соседние шестеренки
Картинка взята с ресурса Brent 2.0, spinning gears, CC BY-ND 2.0
API часто получают данные из пользовательских интерфейсов. Джим Биссо, опытный технический писатель API в области Силиконовой долины, описал API, используя аналогию калькулятора компьютера. Когда нажимаем кнопки, скрытые функции взаимодействуют с другими компонентами для получения информации. Как только информация возвращается, калькулятор представляет данные обратно в графический интерфейс.
Когда нажимаем кнопки, скрытые функции взаимодействуют с другими компонентами и выдают информацию
API работают аналогичным образом. При нажатии на кнопку в интерфейсе, запускаются внутренние функции, чтобы передать и получить информацию. Но вместо того, чтобы получать информацию из одной и той же системы, веб-API вызывают удаленные сервисы в сети, чтобы получить их информацию.
В конечном счете, разработчики вызывают API незримо для пользователя для извлечения информации в свои приложения. Кнопка в графическом интерфейсе пользователя программно подключена для вызова внешних служб. Например, кнопки Twitter или Facebook, которые взаимодействуют с социальными сетями, или видео Youtube, которые извлекают видео с youtube.com, работают под управлением веб-API.
API7:2019 Security Misconfiguration (Некорректная настройка параметров безопасности)
- Используются дефолтные настройки приложений, которые могут быть небезопасны.
- Используются открытые хранилища данных.
- В OpenSourсe попала закрытая информация, например, конфигурация системы или параметры доступа.
- Неправильно сконфигурированы HTTP заголовки (данная тема рассмотрена далее в разделе «Insecure HTTP Headers»).
- Аутентификационные данные (логин/пароль, токен, apiKey) посылаются в URL. Это небезопасно, т.к. параметры из URL могут оставаться в логах веб серверов.
- Отсутствует или неправильно используется политика Cross-Origin Resource Sharing (CORS) (данная политика рассмотрена далее в одноимённом разделе).
- Не используется HTTPS (использование HTTPS рассмотрено в разделе «Insecure Transport»).
- При эксплуатации промышленной системы используются настройки, предназначенные для разработки и отладки.
- Сообщения об ошибках содержат чувствительную информацию, например, трейсы стека.
- Для пользователей устанавливать только необходимые права доступа.
- Открывать только необходимые сетевые порты.
- Устанавливать безопасные версии патчей OS и приложений (подробно рекомендации рассмотрены в разделе «Using Components with Known Vulnerabilities»).
Критика протокола и оргподходов Telegram. Часть 1, техническая: опыт написания клиента с нуля — TL, MT
В последнее время на Хабре стали чаще появляться посты о том, как хорош Telegram, как гениальны и опытны братья Дуровы в построении сетевых систем, и т.п. В то же время, очень мало кто действительно погружался в техническое устройство — как максимум, используют достаточно простой (и весьма отличающийся от MTProto) Bot API на базе JSON, а обычно просто принимают на веру все те дифирамбы и пиар, что крутятся вокруг мессенджера. Почти полтора года назад мой коллега по НПО «Эшелон» Василий (к сожалению, его учетку на Хабре стёрли вместе с черновиком) начал писать свой собственный клиент Telegram с нуля на Perl, позже присоединился и автор этих строк. Почему на Perl, немедленно спросят некоторые? Потому что на других языках такие проекты уже есть
Тем не менее, в данной серии постов будет не так много криптографии и математики. Зато будет много других технических подробностей и архитектурных костылей (пригодится и тем, кто не будет писать с нуля, а будет пользоваться библиотекой на любом языке). Итак, главной целью было — попытаться реализовать клиент с нуля по официальной документации. То есть, предположим, что исходный код официальных клиентов закрыт (опять же во второй части подробнее раскроем тему того, что это и правда бывает так), но, как в старые времена, например, есть стандарт по типу RFC — возможно ли написать клиент по одной лишь спецификации, «не подглядывая» в исходники, хоть официальных (Telegram Desktop, мобильных), хоть неофициальных Telethon?
Стратегии документирования вложенных объектов
Часто бывает, ответ содержит вложенные объекты (объекты внутри объектов) или повторяющиеся элементы. Форматирование документации для схемы ответа является одним из наиболее сложных аспектов справочной документации API.
Очень популярно использование таблиц. В курсе Петера Грюнбаума по технической документацииAPI для Udemy Грюнбаум представляет вложенные объекты, используя таблицы с различными столбцами:

Грюнбаум использует таблицы главным образом для того, чтобы уменьшить акцент на инструментах и уделить больше внимания контенту.
Dropbox API представляет вложение косой чертой. Например, , и указывают несколько уровней объекта.

Другие API будут вкладывать определения ответов для имитации структуры JSON. Вот пример из bit.ly API:

Многоуровневые списки обычно являются бельмом на глазу, но здесь они служат цели, которая хорошо работает, не требуя сложного моделирования.
Подход eBay еще уникальнее. В их случае вложен в , который вложен в , который вложен в
(Обратите внимание, что этот ответ находится в формате XML вместо JSON.):
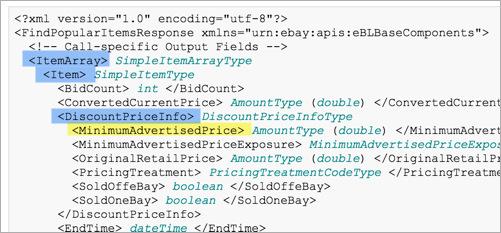
Вот документация ответа:

Также интересно, сколько деталей eBay включает для каждого элемента. В то время как авторы Twitter, опускают описания, авторы eBay пишут небольшие романы, описывающие каждый элемент в ответе.
API2:2019 — Broken User Authentication (Недостатки аутентификации пользователей)
OAuth 2.0, OpenID Connect, WebAuthn
- Пользователь заходит на сайт и нажимает кнопку «Зайти с помощью Google аккаунта»
- Сервер посылает запрос на Google.
- Google показывает пользователю свою форму логина.
- Пользователь вводит логин/пароль.
- Google проверяет логин/пароль и отправляет на наш сервер приложений access token и refresh token.
- Для аутентификации сервер расшифровывает token или получает информацию о пользователе по Google API.
- После этого при каждом запросе к серверу клиент будет передавать access token в запросе, а наш сервер проверять его на валидность в Google и только после этого передавать запрошенные данные.
- При окончании срока действия access токена сервер использует refresh токен для получения нового.
Какие плюсы Token-Based Authentication для сервера приложений:
- Не надо хранить пароли в базе данных на сервере, таким образом сразу избавляемся от уязвимости Insecure Passwords.
- В некоторых случаях можно вообще избавиться от базы данных на сервере и получать всю необходимую информацию из Google или других систем.
- Нет проблем с безопасностью, характерных для остальных методов:
- При компрометации логина/пароля доступ к данным получается сразу и длится пока пользователь сам не заметит факт взлома, у токенов же есть время жизни, которое может быть небольшим.
- Токен автоматически не уйдет на сторонний сайт, как Cookie.
- Cookie-Based Authentication подвержена атаке Cross-Site Request Forgeries (CSRF) и, соответственно, необходимо использовать дополнительные механизмы защиты.
- Можно не хранить сессию пользователя на сервере, а токен проверять каждый раз в Google.
Минус видится один:
Dart на сервере
Tutorial
Недавно столкнулся с необходимостью написать REST API сервер на Dart. Оставим за рамками этой статьи почему и зачем это было надо, но первое с чем я столкнулся — выбор библиотек. Так уж сложилось, что я привык писать на NodeJS используя KoaJS в качестве веб сервера. Простая и удобная библиотека с кучей расширений для любой необходимости. А вот Dart в этом плане несколько подкачал. На момент поисков из «живых» пакетов на pub.dev был только shelf. Что-то отдаленно похожее, но по факту жутко неудобное. Неделю промучившись с оным, понял, надо писать свое, с блэкджеком… что-нибудь в стиле того же KoaJS.
Запросы на разных языках
Как было сказано ранее в разделе Что такое REST API? REST API не зависит от языка. Универсальный протокол помогает облегчить широкое распространение для разных языков программирования. Разработчики могут кодировать свои приложения на любом языке, от Java до Ruby, JavaScript, Python, C #, Node JS или каком-либо еще. Пока разработчики могут отправлять HTTP-запросы на своем языке, они могут использовать API. Ответ от веб-запроса будет содержать данные в формате JSON или XML.
Поскольку невозможно знать, на каком языке будут писать конечные пользователи, попытка предоставить примеры кода на каждом языке бесполезна. Многие API просто показывают формат для отправки запросов и пример ответа, и авторы предполагают, что разработчики будут знать, как отправлять HTTP-запросы на своем конкретном языке программирования.
Однако некоторые API отображают простые запросы на разных языках. Вот пример из Twilio:
в выпадающем списке можно выбрать, какой язык использовать для примера запроса: C #, curl, Java, Node.js, PHP, Python или Ruby.
Вот еще пример API от Clearbit:
Можно увидеть запрос в Shell (curl), Ruby, Node или Python. Разработчики могут легко скопировать необходимый код в свои приложения, вместо того чтобы выяснить, как заставить запрос curl перевести на определенный язык программирования.
Предоставление различных запросов, подобных этому, часто отображаемых на , помогает упростить реализацию API. Еще лучше, если есть возможность автоматически заполнять ключи API фактическими пользовательскими ключами API на основе их авторизованного профиля.
Но нас не испугает этот шведский стол с примерами кода. Некоторые инструментальные средства API (такие как или SwaggerHub) могут автоматически генерировать эти примеры кода, поскольку паттерны выполнения запросов REST на разных языках программирования следуют общему шаблону.
Tip: Менеджеры продуктов часто знают, на каких языках программирования целевые пользователи разрабатывают приложения. Если известен предпочитаемый язык программирования целевой аудитории, можно добавлять примеры кода только на нужном языке.
Отсутствие результата — тоже результат
Если сервер корректно обработал вопрос и никакой внештатной ситуации не возникло — следовательно, это не ошибка. К сожалению, весьма распространён антипаттерн, когда отсутствие результата считается ошибкой.
Плохо
Статусы означают, что клиент допустил ошибку; однако в данном случае никакой ошибки сделано не было, ни пользователем, ни разработчиком: клиент же не может знать заранее, готовят здесь лунго или нет.
Хорошо:
Это правило вообще можно упростить до следующего: если результатом операции является массив данных, то пустота этого массива — не ошибка, а штатный ответ. (Если, конечно, он допустим по смыслу; пустой массив координат, например, является ошибкой.)
Это дополнение к . Работа ведётся на Github. Англоязычный вариант этой же главы опубликован на medium. Я буду признателен, если вы пошарите его на реддит — я сам не могу согласно политике платформы.
Прощай, Google Maps
Перевод
Google решил сделать из Google Maps новый миллиардный бизнес, подняв цены в 14 раз и уменьшив лимит бесплатного использования почти в 30 раз, всё с минимальным периодом уведомления. К счастью, это немедленно стимулировало конкуренцию. Apple Maps, MapBox, TomTom — что выбрать?
Наш стартап GdziePoLek.pl позволяет пациентам находить нужные лекарства в обычных аптеках
И даже по названию («где найти лекарства») понятно, насколько важно отображение на карте. Работу сервиса легко объяснить одной картинкой, на фоне которой всегда были карты Google Maps:Типичная страница нашего сервиса показывает наличие лекарства в аптеках
Избегайте двойных отрицаний
Плохо: — люди в целом плохо считывают двойные отрицания. Это провоцирует ошибки.
Лучше: или — читается лучше, хотя обольщаться все равно не следует. Насколько это возможно откажитесь от семантически двойных отрицаний, даже если вы придумали «негативное» слово без явной приставки «не».
Стоит также отметить, что в использовании законов де Моргана ошибиться ещё проще, чем в двойных отрицаниях. Предположим, что у вас есть два флага:
Условие «кофе можно приготовить» будет выглядеть как — есть и зерно, и стакан. Однако, если по какой-то причине в ответе будут отрицания тех же флагов:
— то разработчику потребуется вычислить флаг ⇔ , а вот этом переходе ошибиться очень легко, и избегание двойных отрицаний помогает слабо. Здесь, к сожалению, есть только общий совет «избегайте ситуаций, когда разработчику нужно вычислять такие флаги».
Избегайте частичных обновлений
Плохо:
— такой подход часто практикуют для того, чтобы уменьшить объёмы запросов и ответов, плюс это позволяет дёшево реализовать совместное редактирование. Оба этих преимущества на самом деле являются мнимыми.
Во-первых, экономия объёма ответа в современных условиях требуется редко. Максимальные размеры сетевых пакетов (MTU, Maximum Transmission Unit) в настоящее время составляют более килобайта; пытаться экономить на размере ответа, пока он не превышает килобайт — попросту бессмысленная трата времени.
Перерасход трафика возникает, если:
-
не предусмотрен постраничный перебор данных;
-
не предусмотрены ограничения на размер значений полей;
-
передаются бинарные данные (графика, аудио, видео и т.д.).
Во всех трёх случаях передача части полей в лучше случае замаскирует проблему, но не решит. Более оправдан следующий подход:
-
для «тяжёлых» данных сделать отдельные эндпойнты;
-
ввести пагинацию и лимитирование значений полей;
-
на всём остальном не пытаться экономить.
Во-вторых, экономия размера ответа выйдет боком как раз при совместном редактировании: один клиент не будет видеть, какие изменения внёс другой. Вообще в 9 случаях из 10 (а фактически — всегда, когда размер ответа не оказывает значительного влияния на производительность) во всех отношениях лучше из любой модифицирующей операции возвращать полное состояние сущности в том же формате, что и из операции доступа на чтение.
В-третьих, этот подход может как-то работать при необходимость перезаписать поле. Но что делать, если поле требуется сбросить к значению по умолчанию? Например, как удалить ?
Часто в таких случаях прибегают к специальным значениям, которые означают удаление поля, например, null. Но, как мы разобрали выше, это плохая практика. Другой вариант — запрет необязательных полей, но это существенно усложняет дальнейшее развитие API.
Хорошо: можно применить одну из двух стратегий.
Вариант 1: разделение эндпойнтов. Редактируемые поля группируются и выносятся в отдельный эндпойнт. Этот подход также хорошо согласуется , который мы рассматривали в предыдущем разделе.
Теперь для удаления достаточно не передавать его в . Этот подход также позволяет отделить неизменяемые и вычисляемые поля ( и ) от изменяемых, не создавая двусмысленных ситуаций (что произойдёт, если клиент попытается изменить ?). В этом подходе также можно в ответах операций возвращать объект заказа целиком (однако следует использовать какую-то конвенцию именования).
Вариант 2: разработать формат описания атомарных изменений.
Этот подход существенно сложнее в имплементации, но является единственным возможным вариантом реализации совместного редактирования, поскольку он явно отражает, что в действительности делал пользовать с представлением объекта. Имея данные в таком формате возможно организовать и оффлайн-редактирование, когда пользовательские изменения накапливаются и потом сервер автоматически разрешает конфликты, «перебазируя» изменения.
Плюсы и минусы работы с API
Плюсов у использования API немало:
- Самый главный плюс работы с API – это экономия времени при разработке собственных сервисов. Программист получает готовые решения и ему не нужно тратить время на написание кода для функционала, который уже давно реализован.
- В API могут учитываться нюансы, которые сторонний разработчик может не учесть или просто не знать,
- API дает приложениям определенную системность и предсказуемость – одна и та же функция с помощью API может быть реализована в разных приложениях так, что будет понятна и знакома всем пользователям.
- API дает сторонним разработчикам доступ к закрытым сервисам.
Но также есть и минусы:
- Если в основной сервис вносятся изменения и доработки, в API они могут попасть не сразу,
- Разработчику доступны готовые решения, как именно они реализованы и как выглядит исходный код, он не знает,
- API предназначен в первую очередь для общего использования, он может не подойти для создания какого-то особого функционала.
Уродливый API
Из песочницы
В этой статье хочу рассказать о проблемах, с которыми столкнулся в процессе интеграции с API по HTTP протоколу, и поделиться опытом их решения.
При разработке фронтенд приложений (mobile/web), часто сталкиваешься с тем, что API на бэкенде еще не реализован. Приходится ждать разработчика на бэкенде, когда он предоставит нужные запросы, постоянно напоминая ему о себе. Не редкость и другая ситуация, когда нужные http запросы уже есть, но они реализованы очень плохо и криво.
Возможно, я бы и не писал эту статью. Но мне показался поразительным тот факт, что все приведенные ниже примеры плохой реализации API попались мне в одном-единственном проекте, одновременно!
В этом проекте я разрабатываю мобильное приложение на Flutter, используя пакет Retrofit, который помогает мне сократить время и код, который приходится писать самому, генерируя значительный код автоматически. Так же использую Insomnia, для первоначальной проверки запросов до реализации их в коде.
Итак, начнем.
Что такое REST API?
Representable State Transfer(REST) Application Programming Interface(API) предоставляет набор методов, которые программист может использовать через HTTP для отправки и получения данных. Поскольку эти методы используют HTTP, любой язык программирования может работать с ними.
Сейчас доступны тысячи REST API практически на всех возможных сайтах. Обычно для общедоступных данных, таких как погода или фондовые рынки, вы можете найти десятки разных API, доступных для использования. Многие популярные веб-платформы, такие как Facebook и Twitter, также предоставляют API для разработчиков. Некоторые из проприетарных API имеют ограничения на количество обращений к ним. Многие требуют регистрации и получения закрытого ключа. Наиболее безопасные API требуют настройки OAuth для безопасного входа пользователей.
Вы можете найти огромный список публичных API на Github, а еще больший список существует на RapidAPI.
Работа с API — реальные примеры использования
Какое практическое применение API может быть? Есть применение, если вы, программист.
Большинство крупных приложений открывают свои API и предоставляют возможность пользоваться ими.
Например, сервис по продвижению крупных технологических проектов под названием Product Hunt, собрал на своем официальном сайте коллекцию API всевозможных сервисов – заходите, скачивайте, пользуйтесь. Тут есть API Gmail, Uber, и так далее.
Кроме того существует интересный ресурс под названием ifttt, который представляет собой максимально доступное для пользователя приложение для работы с различными API. Данный сервис помогает взаимодействовать огромному количеству приложений и сайтов. Например, с помощью этого сервиса можно настроить автоматическую публикацию статей в ленте Facebook после ее публикации на вашем WordPress-сайте.
Примеры разделов “Начало работы”
Ниже приведены несколько примеров разделов “Начало работы” в API. Если сравнить различные разделы «Начало работы», можно увидеть, что некоторые из них являются подробными, а некоторые — высокоуровневыми и краткими. В общем, чем дольше можно вести разработчика за руку, тем лучше. Тем не менее, раздел должен быть кратким, а не многословным с другой документацией. Ключевым моментом является то, чтобы показать пользователю полный, от и до, процесс работы с API.
Paypal
“Начало работы” Paypal содержит довольно много деталей, начиная с авторизации, запросов и других деталей до первого запроса. Хотя этот уровень детализации не так краток, он помогает сориентировать пользователей на необходимую им информацию. Чистый и понятный формат.
Начало работы в Твиттер
На стартовой странице Twitter есть несколько разделов, посвященных началу работы, для разных целей разработки. Текст лаконичен и понятен. В разделе размещены ссылки на другую документацию для получения более подробной информации. В целях краткости можно следовать такой же стратегии — быть кратким и ссылаться на другие страницы, которые содержат более подробную информацию.
Parse Server
Начало работы Parse Server
Раздел “Начало” работы в Parse Server содержит большое количество деталей и подробное описание различных этапов. Для более подробных шагов по подключению вашего приложения и запуску сервера в другом месте, в разделе размещена ссылка на дополнительную информацию.
Adsense
Начало работы Adsense
“Начало работы” Adsense выделяет некоторые основные предпосылки для начала работы на платформе. После того, как вы настроитесь, он предоставляет «краткое руководство по началу работы». Такое руководство знакомит пользователей с простым сценарием от начала до конца, помогая им понять продукт и его возможности.
Aeris
Начало работы Aeris
Начало работы в сервисе погоды Aeris предоставляет информацию для настройки приложения, а затем делает запрос на одном из нескольких популярных языков. Хотя показ кода на определенных языках, несомненно, более полезен для программистов, использующих данный язык, примеры кода могут быть неуместны для других пользователей (например, разработчики Java могут найти код Python неуместным, и наоборот). Фокусировка на определенном языке часто является компромиссом.
Watson and IBM Cloud
Начало работы Watson and IBM Cloud
В разделе “Начало работы” Watson и IBM Cloud перечислены три шага. Тем не менее, это не полное руководство по началу работы. Пользователь может только выбрать сервис для своего проекта. В итоге кодировать начинаем с помощью Watson Dashboard.
В идеале, раздел “Начало работы” должен помочь пользователю увидеть ощутимые результаты, но возможно ли это или нет, зависит от API.
Используйте глобально уникальные идентификаторы
Хороший тон при разработке API — использовать для идентификаторов сущностей глобально уникальные строки, либо семантичные (например, «lungo» для видов напитков), либо случайные (например ). Это может чрезвычайно пригодиться, если вдруг придётся объединять данные из нескольких источников под одним идентификатором.
Мы вообще склонны порекомендовать использовать идентификаторы в urn-подобном формате, т.е. (или просто ), это сильно помогает с отладкой legacy-систем, где по историческим причинам есть несколько разных идентификаторов для одной и той же сущности — тогда неймспейсы в urn помогут быстро понять, что это за идентификатор и нет ли здесь ошибки использования.
Отдельное важное следствие: не используете инкрементальные номера как идентификаторы. Помимо вышесказанного, это плохо ещё и тем, что ваши конкуренты легко смогут подсчитать, сколько у вас в системе каких сущностей и тем самым вычислить, например, точное количество заказов за каждый день наблюдений
NB: в этой книге часто используются короткие идентификаторы типа «123» в примерах — это для удобства чтения на маленьких экранах, повторять эту практику в реальном API не надо.
Весь веб на 60+ FPS: как новый рендерер в Firefox избавился от рывков и подтормаживаний
Перевод
До релиза Firefox Quantum остаётся всё меньше времени. Он принесёт множество улучшений в производительности, в том числе сверхбыстрый движок CSS, который мы позаимствовали у Servo.
Но есть ещё одна большая часть технологии Servo, которая пока не вошла в состав Firefox Quantum, но скоро войдёт. Это WebRender, часть проекта Quantum Render.
WebRender известен своей исключительной скоростью. Но главная задача — не ускорить рендеринг, а сделать его более плавным.
При разработке WebRender мы поставили задачу, чтобы все приложения работали на 60 кадрах в секунду (FPS) или лучше, независимо от размера дисплея или от размера анимации. И это сработало. Страницы, которые пыхтят на 15 FPS в Chrome или нынешнем Firefox, летают на 60 FPS при запуске WebRender.
Как WebRender делает это? Он фундаментальным образом меняет принцип работы движка рендеринга, делая его более похожим на движок 3D-игры.