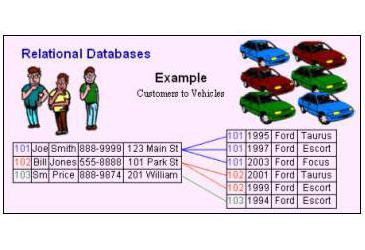
Этапы проектирования баз данных
Содержание:
- Этапы проектирования базы данных
- Литература
- Запросы к базе данных и отчёты
- Мультиплатформные приложения баз данных
- Виды баз данных и их структура, примеры
- Основные этапы проектирования баз данных
- Этапы создания базы данных
- Приведём пример
- Правило 3: Не переусердствуйте с правилом 2
- SQLite
- Изменения в данных и схемах
- Структура базы данных: построение блоков
- Правило 4: Относитесь к дублирующим неоднородным данным как к своему главному врагу.
- Признаки БД, чем отличаются от электронных таблиц
- Правило 7. Тщательно выбирайте производные столбцы
- SQL Server Data Tools
- Выбор системы управления и программных средств БД
- Разница между реляционной и иерархической базой данных
- Список полезной литературы
- Анализ требований: определение цели базы данных
Этапы проектирования базы данных
Этап начальной разработки
- анализ деятельности компании;
- анализ структуры компании;
- спецификация требований;
- определение целей;
- сферы применения;
- границы возможностей.
Концептуальное проектирование базы данных
- анализ требований к базе данных, выявление представлений конечных пользователей и требований к обработке транзакций;
- определение сущностей, атрибутов и связей;
- разработка ER-диаграмм (от ER — Entity-Relationship — Сущность-Связь);
- нормализация;
- проверка модели данных, выявление основных процессов (правила ввода, обновления и удаления данных);
- проверка отчётов, запросов, представлений, целостности, совместного использования и безопасности.
Литература
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — 1328 с. — ISBN 0-321-19784-4.
- Когаловский М.Р. Перспективные технологии информационных систем. — М.: ДМК Пресс; Компания АйТи, 2003. — 288 с. — ISBN 5-279-02276-4.
- Когаловский М.Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. — ISBN 978-5-94774-736-2.
- Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: «Вильямс», 2003. — 1436 с. — ISBN 0-201-70857-4.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс. — М.: «Вильямс», 2003. — 1088 с. — ISBN 5-8459-0384-X.
Запросы к базе данных и отчёты
Запросы:
- доступность выбираемого в селекторе препарата в выбираемой в селекторе аптеке на данный момент времени;
- группы препаратов, которых нет в выбираемой в селекторе аптеке на данный момент времени;
- аптеки, в которых есть дефицит любого препарата по введённой дате;
- покупки препаратов, которые есть на витринах аптек по введённой дате с указанием препаратов и аптек;
- клиенты, совершившие покупки в выбранной в селекторе аптеке по введённой дате.
Отчёты:
- о количестве покупок со списком аптек по введённой дате с указанием сумм;
- о продажах выбранного препарата во всех аптеках по введённой дате;
- о проданных препаратах стоимостью более 150 рублей по введённой дате;
- о препаратах, которые есть на витрине во всех аптеках;
- о клиентах, зарегистрированных в определённый интервал времени.
Поделиться с друзьями
Реляционные базы данных и язык SQL
Мультиплатформные приложения баз данных
Особую проблему для разработчиков представляет разработка приложений баз данных, которые должны работать с несколькими СУБД. Например, банки и страховые компании обычно имеют несколько больших офисов и множество маленьких филиалов. Большинство бизнес-процессов, касающихся ввода оперативной информации и повседневного документооборота, совпадают и в головном офисе, и в филиалах, однако масштабы разные. Естественное желание сэкономить на стоимости лицензий промышленной СУБД для применения в филиалах приводит к мысли о том, что хорошо бы выбрать другую СУБД без смены приложения.
Опытные разработчики баз данных хорошо понимают суть возникающих здесь проблем: различие типов данных и диалектов SQL, отсутствие механизмов миграции и репликации между разными СУБД, сложность верификации миграции превращают написание и эксплуатацию приложений для разных СУБД в кошмар. Со стороны средств разработки приложений эту проблему пытаются решить за счет создания библиотек доступа к данным (dbExpress в Delphi и C++ Builder, ADO и ADO.Net от Microsoft), построенным на единых архитектурных принципах и методах доступа, а также путем применения многочисленных объектно-реляционных «оберток» (Object Relation Mapping, ORM) над реляционной логикой и структурой базы данных, генерирующих исходный код для работы с данными на основе анализа схемы базы данных и использующих механизм «адаптеров» для реализации протокола конкретной СУБД. Среди наиболее популярных ORM надо отметить Hibernate для Java и ActiveRecord в RubyOnRails, которые предоставляют объектно-ориентированный интерфейс к хранящимся в СУБД данным. Для Delphi существует аналогичный проект tiOPF, для C# – NHibernate.
Конечно, использование таких универсальных библиотек и наборов компонентов позволяет значительно сократить число рутинных операций в процессе мультиплатформной разработки баз данных. Однако этого недостаточно, когда речь идет о приложениях, использующих более сложные базы данных, в которых активно употребляется логика, заложенная в хранимых процедурах и триггерах, – для ее реализации, отладки и тестирования требуются отдельные инструменты, подчас совершенно разные для разных СУБД. Для разработки кроссплатформных приложений баз данных Embarcadero предлагает инструмент RapidSQL.
Все продукты Embarcadero для работы с базами данных поддерживают несколько платформ и основаны на ядре анализа схемы и статистики баз данных Thunderbolt. Каждая поддерживаемая СУБД и каждая конкретная версия СУБД имеют соответствующие ветки кода в ядре Thunderbolt, что позволяет максимально точно отображать схему базы данных на внутреннее представление в этом ядре и, самое главное, осуществлять корректные преобразования между представлением и реальными базами данных. Именно благодаря ядру Thunderbolt система RapidSQL позволяет разрабатывать качественный SQL-код для всех поддерживаемых платформ (Oracle, MS SQL, Sybase и различные варианты IBM DB2), а ER/Studio может осуществлять точный reverse- и forward-инжиниринг схем баз данных.
Если разрабатывается приложение для двух и более платформ или переносится существующее приложение с одной платформы на другую, то RapidSQL предоставит все необходимые инструменты для миграции схемы, пользователей и разрешений между разными СУБД. Конечно, RapidSQL автоматически не конвертирует процедуры на PL/SQL в T-SQL – для этого все еще требуется программист, однако инструмент обеспечивает единое окно для мультиплатформной разработки, унифицированные редакторы объектов схемы, пользователей и их прав, а также отладку SQL на всех поддерживаемых платформах. По утверждениям пользователей RapidSQL, в результате экономится до 70% времени, которое тратится на миграцию между разными СУБД.
Виды баз данных и их структура, примеры
Выделяют несколько видов баз данных. Основными из них являются:
- Фактографическая, с краткой информацией об объектах какой-то системы, формат которой строго фиксирован.
- Документальная, включает документы разного вида, в том числе текстовые, графические, звуковые, мультимедийные.
- Распределенная, является базой данных с разными частями, которые хранятся на различных компьютерах, объединенных в сеть.
- Централизованная, представляет собой базу данных, местом хранения которой является один компьютер.
- Реляционная, имеет табличную организацию данных.
- Неструктурированная (NoSQL), является базой данных, в которой делается попытка решить проблемы масштабируемости и доступности с помощью атомарности и согласованности данных без четкой структуры.
Базы данных разных систем обладают неодинаковой структурой. Для ПЭВМ характерно использование реляционных баз данных с файлами в виде таблиц, в которых столбцы являются полями, а строки – записями. В базе данных находятся данные определенного множества объектов. Для каждой записи характерна информация по одному объекту. Такую базу определяют:
- имя файла;
- список полей;
- ширина полей.
В качестве примера можно привести школьную базу с данными «Ученик», «Класс», «Адрес». Также базой данных является расписание движения поездов или автобусов. В этом случае каждой строке соответствует запись с данными конкретного объекта. Возможные поля: номер рейса, маршрут, время отправления и прибытия. Классической базой данных является телефонный справочник.
Определение
Запрос к базе данных – предписание с указанием на данные, которые необходимы пользователю.
Примечание
В случае некоторых запросов требуется составление сложной программы. К примеру, для выполнения запроса к базе в виде автобусного расписания необходимо вычислить разницу в среднем интервале отправления транспорта из одного города во второй и из второго пункта в третий.
Существует три звена для создания приложения, с помощью которого можно просматривать и редактировать базы данных:
- набор данных;
- источник информации;
- визуальные компоненты управления.
В случае Access роль таких звеньев выполняют:
- Table.
- DataSource.
- DBGrid.
Приложения базы данных является нитью, которая связывает базу и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table, в виде таблицы, навигационного доступа;
- Query, включая запрос, реляционный доступ.
Визуальными компонентами являются:
- Сетки DBGrid, DBCtrlGrid.
- Навигатор DBNavigator.
- Разные аналоги Lable, Edit.
- Компоненты подстановки.
Access характеризуется наличием следующих типов полей:
- текстовый, в виде текстовой строки с максимальной длиной до 255, заданной параметром «размер»;
- поле МЕМО, является текстом длиной до 65535 символов;
- числовой, в параметре «Размер поля» можно задать поле: байт, целое, действительное и другие;
- дата/время, необходимо для записи данных о времени;
- денежный, является специальным форматом для решения финансовых задач;
- счетчик, в виде автоинкрементного поля, который предназначен для ключевого поля, увеличивается на единицу после добавления новой записи и сохраняется в данное поле новой записи, что гарантирует разные значения для неодинаковых записей;
- логический, в виде «да или нет», «правда или ложь», «включен или выключен»;
- объект OLE, предназначен для хранения документов, картинок, звуков и другой информации, представляет собой частный случай BLOB, то есть полей (Binary Large Object), которые можно встретить в разных базах данных;
- гиперссылка, необходима для хранения ссылок на ресурсы в Интернете, характерна не для всех форматов баз данных, например, отсутствует в dBase и Paradox;
- подстановка.
Благодаря связи с обеспечением целостности таблиц осуществляется контроль удаления и модификации данных. С помощью монопольного доступа к базам данных в них производят фундаментальные изменения.
Основные этапы проектирования баз данных
Концептуальное (инфологическое) проектирование
Пример концептуальной схемы
Концептуальное (инфологическое) проектирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» и «инфологическая модель» являются синонимами. Кроме того, в этом контексте равноправно могут использоваться слова «модель базы данных» и «модель предметной области» (например, «концептуальная модель базы данных» и «концептуальная модель предметной области»), поскольку такая модель является как образом реальности, так и образом проектируемой базы данных для этой реальности.
Конкретный вид и содержание концептуальной модели базы данных определяется выбранным для этого формальным аппаратом. Обычно используются графические нотации, подобные .
Чаще всего концептуальная модель базы данных включает в себя:
- описание информационных объектов или понятий предметной области и связей между ними.
- описание ограничений целостности, то есть требований к допустимым значениям данных и к связям между ними.
Логическое (даталогическое) проектирование
Пример логической схемы для реляционной модели данных.
Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи.
Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован.
На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД.
Физическое проектирование
Физическое проектирование — создание схемы базы данных для конкретной СУБД. Специфика конкретной СУБД может включать в себя ограничения на именование объектов базы данных, ограничения на поддерживаемые типы данных и т. п. Кроме того, специфика конкретной СУБД при физическом проектировании включает выбор решений, связанных с физической средой хранения данных (выбор методов управления дисковой памятью, разделение БД по файлам и устройствам, методов доступа к данным), создание индексов и т. д.
Результатом физического проектирования логической схемы выше на языке SQL может являться следующий скрипт:
CREATE TABLE IF NOT EXISTS Department ( -- Факультет
id INT NOT NULL,
name VARCHAR(45),
PRIMARY KEY (id)
);
CREATE TABLE IF NOT EXISTS Group (
id INT NOT NULL,
name VARCHAR(45) ,
depart_id INT NOT NULL,
UNIQUE INDEX depart_id_UNIQUE (depart_id ASC),
PRIMARY KEY (id, depart_id),
CONSTRAINT depart_fk
FOREIGN KEY (depart_id)
REFERENCES Department (id)
);
CREATE TABLE IF NOT EXISTS Student (
first_name VARCHAR(16) NOT NULL,
last_name VARCHAR(45) NOT NULL,
email VARCHAR(255),
group_id INT NOT NULL,
PRIMARY KEY (last_name, first_name, group_id),
INDEX group_fk_idx (group_id ASC),
CONSTRAINT group_fk
FOREIGN KEY (group_id) REFERENCES Group (id)
);
Этапы создания базы данных
Надлежащим образом структурированная база данных:
- Помогает сэкономить дисковое пространство за счет исключения лишних данных;
- Поддерживает точность и целостность данных;
- Обеспечивает удобный доступ к данным.
Основные этапы разработки базы данных:
- Анализ требований или определение цели базы данных;
- Организация данных в таблицах;
- Указание первичных ключей и анализ связей;
- Нормализация таблиц.
Рассмотрим каждый этап проектирования баз данных подробнее
Обратите внимание, что в этом руководстве рассматривается реляционная модель базы данных Эдгара Кодда, написанная на языке SQL (а не иерархическая, сетевая или объектная модели)
Приведём пример
Допустим, вы хотите создать базу данных для интернет-форума. На форуме есть зарегистрированные пользователи, создающие темы и оставляющие сообщения в данных темах. Вся эта информация и должна размещаться в базе данных.
В теории всё можно расположить в одной таблице, а именно:
Однако такое расположение противоречит атомарности, причём в столбцах «Созданные сообщения» и «Созданные темы» возможно неограниченное число значений. Целесообразнее всего разбить таблицу на три:
Теперь таблица «Пользователи» соответствует правилам. Но вот таблицы «Сообщения» и «Темы» — нет, т. к. не должно быть 2-х одинаковых строк. В нашем же случае один и тот же пользователь может написать 2 одинаковых сообщения:
А ещё давайте вспомним о том, что каждое сообщение должно относиться к какой-нибудь теме. Для решения этого вопроса в реляционных базах данных используют ключи.
Правило 3: Не переусердствуйте с правилом 2
Разработчики — люди, зачастую воспринимающие все буквально. Если вы скажете им как нужно делать, они будут делать только так и могут переусердствовать, что может привести к нежелательным последствиям. Это также относится к правилу 2, о котором мы только что говорили выше. Когда вы думаете о декомпозиции, остановитесь и спросите себя, насколько она нужна? Разложение должно быть обдуманным и логичным.
Например,ниже вы видите поле номера телефона. Вряд ли вы часто будете использовать коды ISD для телефонных номеров отдельно (пока ваша заявка не потребует этого). Поэтому было бы разумным решением не разбивать его, поскольку это может привести к большему количеству осложнений.
SQLite
Провозгласившая себя самой распространенной СУБД в мире, SQLite зародилась в 2000 году и используется Apple, , Microsoft и . Каждый релиз тщательно тестируется. Разработчики SQLite предоставляют пользователям списки ошибок, а также хронологию изменений кода каждой версии.
Достоинства
- Нет отдельного серверного процесса;
- Формат файла – кросс-платформенный;
- Транзакции соответствуют требованиям ACID;
- Доступна профессиональная поддержка.
Недостатки
Не рекомендуется для:
- клиент-серверных приложений;
- крупномасштабных сайтов;
- больших наборов данных;
- программ с высокой степенью многопоточности.
Изменения в данных и схемах
Миграция с одной СУБД на другую невозможна без ее верификации. Кто и каким образом может гарантировать, что данные, перенесенные из одной СУБД в другую, действительно идентичны? Разные клиентские библиотеки, разные типы данных и разные кодировки превращают процесс сравнения данных в нетривиальную задачу.
В реальном мире на развертывании приложения и базы данных работа не заканчивается — идет сопровождение, появляются новые версии исполняемых файлов приложения и патчи к базе данных. Каким образом можно получить гарантии, что все необходимые обновления были применены к базе данных и что весь комплекс ПО заработает правильно?
Embarcadero разработала инструмент Change Manager, предназначенный для сравнения данных, схем и конфигураций баз данных. Сравнение происходит в рамках одной или нескольких СУБД, с автоматической проверкой соответствия между типами данных и формированием SQL-скриптов отличий, которые можно тут же применить для приведения баз в идентичное состояние. Модуль сравнения метаданных обеспечивает сравнение схем баз данных как между «живыми» базами данных, так и между базой данных и SQL-скриптом и генерирует скрипт отличий метаданных. Эта функциональность может быть использована не только для проверки баз данных на соответствие эталону, но и для организации регулярного процесса обновления баз данных, а также для проверки на неавторизованные изменения, скажем, в удаленных филиалах крупной организации. Аналогичная ситуация с конфигурационными файлами – Change Manager сравнивает конфигурационные файлы и позволяет обеспечить соответствие конфигурации развернутых приложений требованиям для данного ПО.
Структура базы данных: построение блоков
Следующим шагом будет визуальное представление базы данных. Для этого нужно точно знать, как структурируются реляционные БД. Внутри базы связанные данные группируются в таблицы, каждая из которых состоит из строк и столбцов.
Чтобы преобразовать списки данных в таблицы, начните с создания таблицы для каждого типа объектов, таких как товары, продажи, клиенты и заказы. Вот пример:
Каждая строка таблицы называется записью. Записи включают в себя информацию о чем-то или о ком-то, например, о конкретном клиенте. Столбцы (также называемые полями или атрибутами) содержат информацию одного типа, которая отображается для каждой записи, например, адреса всех клиентов, перечисленных в таблице.
- CHAR — конкретная длина текста;
- VARCHAR — текст различной длины;
- TEXT — большой объем текста;
- INT — положительное или отрицательное целое число;
- FLOAT, DOUBLE — числа с плавающей запятой;
- BLOB — двоичные данные.
Некоторые СУБД также предлагают тип данных Autonumber, который автоматически генерирует уникальный номер в каждой строке.
В визуальном представлении БД каждая таблица будет представлена блоком на диаграмме. В заголовке каждого блока должно быть указано, что описывают данные в этой таблице, а ниже должны быть перечислены атрибуты:
проектировании информационной базы данныхPK
Атрибуты, выбранные в качестве первичных ключей, должны быть уникальными, неизменяемыми и для них не может быть задано значение NULL (они не могут быть пустыми). По этой причине номера заказов и имена пользователей являются подходящими первичными ключами, а номера телефонов или адреса — нет. Также можно использовать в качестве первичного ключа несколько полей одновременно (это называется составным ключом).
Когда придет время создавать фактическую БД, вы реализуете как логическую, так и физическую структуру через язык определения данных, поддерживаемый вашей СУБД.
Также необходимо оценить размер БД, чтобы убедиться, что можно получить требуемый уровень производительности и у вас достаточно места для хранения данных.
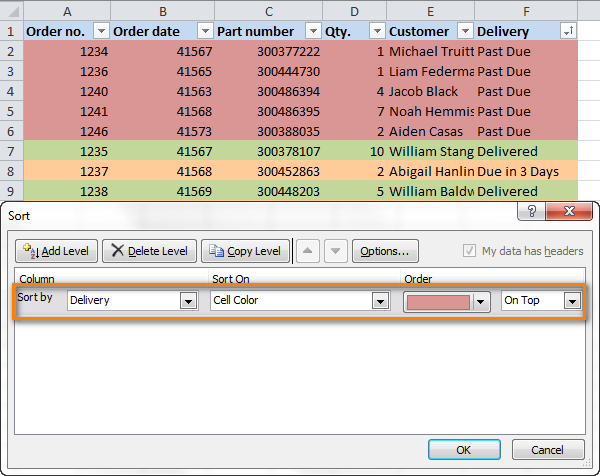
Правило 4: Относитесь к дублирующим неоднородным данным как к своему главному врагу.
Соберите и обработайте дубликаты данных. Основная проблема относительно повторяющихся данных заключается не в том, что требуется пространство на жестком диске, а в путанице, которую они создают.
Например, на приведенной ниже таблице вы можете заметить, что «5th Standard» и «Fifth standard» означает то же самое.Возможно данные попали в систему из-за плохого ввода данных или плохой проверки. Если вы когда-либо захотите получить отчет, они будут отображаться как разные объекты, что очень сбивает с толку.
Одно из возможных решений — перемещение в другую основную таблицу и их передача через внешние ключи. На рисунке ниже показано, мы создали новую главную таблицу под названием «Standards» и связали ее с помощью простого внешнего ключа.
Признаки БД, чем отличаются от электронных таблиц
Любая база данных обладает набором стандартных признаков. Основными из них являются:
- хранение и обработка в вычислительной системе;
- логическая структура;
- наличие схемы или метаданных, которые описывают логическую структуру базы в формальном виде.
Примечание
Первый признак соблюдается строго, остальные могут трактоваться по-разному и иметь неодинаковые степени оценки. Согласно общепринятой практике, к базам данных не относят файловые архивы, интернет-порталы или электронные таблицы.
Рассмотреть базу данных целесообразно на примере Access. Это специальное приложение, в котором хранятся упорядоченные данные, что допускает применение и других приложений (к примеру, Excel). В обоих случаях информация представлена в табличном виде.
Excel включает особые средства, позволяющие работать с упорядоченными данными, позволяет формировать простые базы данных. При внешнем сходстве приложения обладают рядом отличий:
- Excel не предусматривает установку реляционных связей между таблицами. Благодаря связям в Access, исключается ненужное дублирование информации и ошибки при обработке данных. Также допускается совместное использование данных из разных таблиц.
- Access обеспечивает хранение в таблицах нескольких миллионов записей. При этом скорость их обработки сохраняется на высоком уровне.
- Access включает возможность организации одновременной работы с базой данных нескольких десятков пользователей, которые в реальном времени могут видеть изменения, выполненные другими пользователями.
- Данные в Access сохраняются автоматически после завершения редактирования текущей записи. В случае Excel для этого нужно запустить команду «Сохранить».
- Таблицы в Access характеризуются заранее предопределенной жесткой структурой. Невозможно в один столбец записать разные типы данных или форматировать отдельные ячейки.
- Прямо в таблице базы данных Access нельзя выполнять вычисления, подобные действия реализуются с применением запросов.
Вывод: Excel целесообразно использовать для создания компактных баз данных, которые могут поместиться на одном рабочем листе. Excel обладает рядом значительных ограничений для ведения полноценной базы данных, но может успешно использоваться для анализа данных благодаря достаточному математическому аппарату.
Правило 7. Тщательно выбирайте производные столбцы
Если вы работаете над приложениями OLTP, избавление от производных столбцов было бы хорошей мыслью, если только не существует веской причины для повышения производительности. В случае работы с OLAP, где нам нужно производить много сумм и вычислений, эти поля необходимы для повышения производительности.
На приведенном выше рисунке вы можете увидеть, как среднее поле зависит от меток и объекта. Это также одна из форм избыточности. Подумайте, действительно ли нужны поля, полученные из других полей?
Это правило также выражено в 3-й нормальной форме:«Ни один столбец не должен зависеть от других столбцов непервичного ключа». Не стоит применять это правило вслепую, так как не всегда избыточные данные плохие. Если избыточные данные являются расчетными данными, проанализируйте ситуацию, а затем решите, хотите ли вы реализовать третью нормальную форму.
SQL Server Data Tools
SQL Server Data Tools (SSDT) – это отдельный компонент (рабочая нагрузка) Visual Studio, который предназначен для разработки реляционных баз данных SQL Server.
SSDT создан для проектной разработки баз данных с применением всех возможностей и преимуществ Visual Studio, а также с использованием привычного для разработчиков приложений интерфейса и функционала.
Таким образом, SQL Server Data Tools предназначен для разработчиков, создающих приложения в среде Visual Studio.
Основные особенности
Интегрирован в Visual Studio
Знакомый интерфейс и функционал Visual Studio
Ориентация на разработку баз данных
Охват всех этапов разработки базы данных
Можно работать как с проектом базы данных, так и с подключенным экземпляром базы данных
Конструктор таблиц с графическим интерфейсом
Навигация по коду
Технология IntelliSense
Сборка и отладка
Рефакторинг баз данных
Декларативное внесение изменений в редакторе Transact-SQL
Недостатки
Инструмент реализован только под Windows
Инструмент нельзя использовать без Visual Studio
Не подходит для простого написания, редактирования и выполнения SQL запросов
Не подходит для администрирования SQL Server
Мне нравится1Не нравится
Выбор системы управления и программных средств БД
От выбора системы управления БД зависит практическая реализация информационной системы. Наиболее значимыми критериями в процессе выбора становятся параметры:
- типа модели данных и её соответствие потребностям предметной области,
- запас возможностей в случае расширения информационной системы,
- характеристики производительности выбранной системы,
- эксплуатационная надёжность и удобство СУБД,
- инструментальная оснащённость, ориентированная на персонал администрирования данных,
- стоимость самой СУБД и дополнительного софта.
Ошибки в выборе СУБД практически наверняка впоследствии спровоцируют необходимость корректировать концептуальную и логическую модели.
Разница между реляционной и иерархической базой данных
Определение
Реляционная база данных — это база данных, основанная на реляционной модели данных, как было предложено Э. Ф. Коддом в 1970 году. Иерархическая база данных — это тип базы данных, которая организует данные в древовидную структуру. Следовательно, это объясняет принципиальное различие между реляционной и иерархической базой данных.
Основанная модель
То есть; Реляционная база данных основана на реляционной модели. В отличие от этого, иерархическая база данных основана на иерархической модели.
Способ хранения данных
Кроме того, другое различие между реляционной и иерархической базой данных состоит в том, что реляционная база данных хранит данные в таблицах, в то время как иерархическая база данных хранит данные в древовидной структуре.
Извлечение данных
Данные можно легко получить с помощью SQL в реляционной базе данных. С другой стороны, получение данных затруднено в иерархической базе данных. Для получения данных необходимо пройти через все дерево, начиная с корневого узла
Таким образом, это важное различие между реляционной и иерархической базой данных
Заключение
Вкратце, реляционные и иерархические базы данных являются двумя основными типами баз данных. Основное различие между реляционной и иерархической базой данных состоит в том, что реляционная база данных следует реляционной модели и хранит данные в таблицах, в то время как иерархическая база данных следует иерархической модели и хранит данные в древовидной структуре.
Список полезной литературы
- Учимся проектированию Entity Relationship — диаграмм // Хабр URL: https://habr.com/ru/post/440556/ (дата обращения: 02.01.2021).
- Технологии баз данных. Лекция 3. Модель «Сущность-связь». URL: https://docplayer.ru/27886777-Model-sushchnost-svyaz-tehnologii-baz-dannyh-lekciya-3.html (дата обращения: 02.01.2021).
- Entity Relationship Diagram. URL: https://plantuml.com/ru/ie-diagram (дата обращения: 03.01.2021).
- Transact-SQL Reference (Database Engine) // Microsoft Docs URL: https://docs.microsoft.com/ru-ru/sql/t-sql/language-reference?view=sql-server-ver15 (дата обращения: 05.01.2021).
- Нормализация отношений. Шесть нормальных форм // Хабр URL: https://habr.com/ru/post/254773/ (дата обращения: 05.01.2021).
- Материалы для скачивания по SQL Server // Microsoft URL: https://www.microsoft.com/ru-ru/sql-server/sql-server-downloads (дата обращения: 05.01.2021).
- Другой пример проектирования базы данных (MySQL). URL: https://pro-prof.com/forums/topic/db_example
Анализ требований: определение цели базы данных
Например, если вы создаете базу данных для публичной библиотеки, нужно продумать, каким образом и читатели, и библиотекари должны получать доступ к БД.
Вот несколько способов сбора информации перед созданием базы данных:
- Опрос людей, которые будут ее использовать;
- Анализ бизнес-форм, таких как счета-фактуры, расписания, опросы;
- Рассмотрение всех существующих систем данных (включая физические и цифровые файлы).
Начните со сбора существующих данных, которые будут включены в базу. Затем определите типы данных, которые нужно сохранить. А также объекты, которые описывают эти данные. Например:
Клиенты
- Имя;
- Адрес;
- Город, штат, почтовый индекс;
- Адрес электронной почты.
Товары
- Название;
- Цена;
- Количество в наличии;
- Количество под заказ.
Заказы
- Номер заказа;
- Торговый представитель;
- Дата;
- Товар;
- Количество;
- Цена;
- Стоимость.
При проектировании реляционной базы данных эта информация позже станет частью словаря данных, в котором описаны таблицы и поля БД. Разбейте информацию на минимально возможные части. Например, подумайте о том, чтобы разделить поле почтового адреса и штата, чтобы можно было фильтровать людей по штату, в котором они проживают.
После того, как вы определились с тем, какие данные будут включены в базу, откуда эти данные будут поступать, и как они будут использоваться, можно приступить к планированию фактической БД.