Изменить историю онлайн: 10 сайтов, которые станут вашей машиной времени
Содержание:
- Почему страницы может не быть?
- Плюсы и минусы продвижения сателлитами
- Работа с результатами
- Полное удаление страницы
- Качаем сайт с web.archive.org
- Как просмотреть копию страницы?
- Как посмотреть, как выглядела страница ВКонтакте раньше
- Создание задачи
- Элементы сайта-истории
- Как использовать архив
- Что такое веб-архив и зачем он нужен?
- Бесплатные способы восстановления
- Утилиты для сохранения сайтов целиком
- Проекты, предоставляющие историю сайта
- Потеря исходных файлов
- Как использовать веб-архив?
- Как посмотреть удаленную страницу в веб-архиве
- Виды сателлитов
- Как посмотреть историю сайта
- Как выглядел сайт раньше — пошаговая инструкция, как посмотреть
- r-tools.org
- Что если сохраненной страницы нет?
- Как выглядит сайт-история?
- Элементы сайта-истории
- Залог успеха — эмоциональная вовлеченность
- Сохранить как HTML-файл
Почему страницы может не быть?
Иногда во время поиска при нажатии на стрелочку сниппета нужного пункта может и не быть. Это происходит по ряду причин:
- Сбой в работе поисковика. В Яндексе даже не скрывают, что нет никаких гарантий на наличие и показ копий — система может просто не сохранять страницы по какой-либо причине.
- Второй вариант: html-кодировка документа содержит мета-тег «robots» со значением «noarchive», что означает запрет на кэширование. Чтобы не рисковать из-за этого трафиком, стоит внимательно настроить соответствующие блоки и очистить ненужные значения.
Нет копии: чем это грозит?
С точки зрения продвижения — опасность нулевая. А вот сами причины, из-за которых невозможно сохранение, могут быть вредны, нужно разбираться именно в них.
Эксперты уверены, что проблема с копиями может обернуться трудностями при работе с биржами ссылок. Так, на некоторых известных биржах строго контролируют, есть ли в Яндексе копия, проверяя параметр No Index Cache (NIC).
Плюсы и минусы продвижения сателлитами
Преимущества продвижения с помощью сайтов-сателлитов очевидны:
- Удобный способ поддерживать качественную ссылочную массу
- Вы не зависите от рыночных цен на размещение ссылок
- Продвижение несколько проектов с помощью одной сети сателлитов
- Размещение рекламных блоков, покрывающих часть затрат на создание сети
- Есть возможность вытеснить конкурентов из выдачи по ключевым запросам
Недостатки такого метода продвижения:
- Высокая стоимость создания сети сателлитов, куда войдут регистрация домена и хостинга, подготовка контента
- Высокие временные затраты на создание сайта, разработку контента, продвижение
- Есть шанс попасть под пессимизацию Яндекс и Google при создании недостаточно трастовых ресурсов
Работа с результатами
После запуска, задачи появится на листинге в разделе “Восстановление из Вебархива”. Вы можете проследить за статусом его выполнения. Когда задача будет готова появится кнопка “Скачать”, с помощью которой вы сможете скачать ZIP-архив с копией сайта на свой компьютер и потом загрузить его на хостинг.
Чтобы перейти в задачу и просмотреть результаты, просто нажмите на название задачи. Перед вами откроется список скачанных файлов со столбцами:
- Название файла
- Тип файлов
- Дата сохранения
- Действия
Этот список вы можете отсортировать по любому столбцу. Также присутствует форма поиска по названию файла. Вы можете воспользоваться пагинацией или указать сколько результатов выводить на странице.
Вы можете кликнуть по URL-адресам выгруженных файлов — они доступны для просмотра и открываются в новой вкладке (откроется уже сохраненная на нашем сервере копия).
Если какие-то страницы скачались неправильно или не те, то для каждой из них можно выбрать другую дату копии, для этого нужно нажать в колонке “Действия” на иконку редактирования. Чуть подождав, откроется окно с выбором дат, за которые в Вебархиве есть копии. Нужно всего лишь установить чекбокс на дату, которая интересует:
Если других дат нет — значит в Вебархиве не содержится дополнительных копий выбранной страницы.
Дальше, чтобы восстановить сайт на своем сервере скачиваем ZIP-архив c задачи, просматриваем его и распаковываем по FTP в корневую директорию своего домена на хостинге:
После запуска сайта внимательно просмотрите как он работает, пройдитесь по всем страницам, проверьте работоспособность всех ссылок, кнопок, отображение стилей и картинок, так как бывает что в Вебархиве присутствуют не все страницы сайта и нужно что-то подправить.
Полное удаление страницы
Вот теперь, когда архив с данными сохранен, можно спокойно переходить к полному удалению страницы. Для этого выполним следующие действия:
- Открываем дополнительное меню, нажав по значку стрелки возле изображения профиля.
- В появившемся окошке выбираем «Настройки и конфиденциальность», а затем ещё раз «Настройки».
- Открывается специальная страница, с которой мы начинали создавать копию в предыдущем этапе. Только теперь нас интересует строка «Деактивация и удаление». Находим её и нажимаем «Посмотреть».
- Ставим галочку в пункте «Безвозвратное удаление аккаунта». Далее кликаем «Продолжить с удалением аккаунта».
- Внимательно просматриваем уведомление от системы и нажимаем «Удалить аккаунт».
- Подтверждаем действие.
После последнего действия начнется процедура удаления страницы. Однако она занимает определенное количество времени, поэтому если вы передумаете, то в течение месяца без труда сможете вернуть аккаунт.
Качаем сайт с web.archive.org
Процесс восстановления сайта из веб-архива я покажу на примере сайта 1mds.ru. Я не знаю что это за сайт, я всего лишь знаю что у него в архиве много страниц, а это значит что сайт не только существовал, но с ним работали.
Для того, что бы открыть архив нужного сайта, нам необходимо пройти по такой вот ссылке:
http://web.archive.org/web/*/1mds.ru
На 24 ноября 2018 года, при открытии этой ссылки я обнаружил вот такую картину:
Как видите на главной зафиксировались результаты экспериментов с программной частью. Если мы просто скачаем сайт как есть, то в качестве главной будет именно эта страница. нам необходимо избежать попадания в архив таких страниц. Как это сделать? Довольно просто, но для начала необходимо определить когда последний раз в архив добавлялась главная страница сайта. Для этого нам необходимо воспользоваться навигацией по архиву сайта, которая расположена вверху справа:
Кликаем левую стрелку ибо правая все равно не активна, и кликаем до тех пор, пока не увидим главную страницу сайта. Возможно кликать придется много, бывает домены попадаются с весьма богатым прошлым. Например сайт, на примере которого я демонстрирую работу с архивом, не является исключением.
Вот мы можем видеть что 2 мая 2018-го бот обнаружил сообщение о том, что домен направлен на другой сайт:
Классика жанра, регистрируешь домен и направляешь его на существующий дабы не тратить лимит тарифа на количество сайтов.
А до этого, 30 марта, там был вообще блог про шитье-вязание.
Долистал я до 23 октября 2017-го и вижу уже другое содержимое:
Тут мы видим уже материалы связанные с воспитанием ребенка. Листаем дальше, там вообще попадается период когда на домене была всего одна страница с рекламой:
А вот с 25 апреля 2011 по 10 сентября 2013-го там был сайт связанный с рекламой. В общем нам нужно определиться какой из этих периодов мы хотим восстановить. К примеру я хочу восстановить блог про шитье-вязание. Мне необходимо найти дату его появления и дату когда этот блог был замечен там последний раз.
Я нашел последнюю дату, когда блог был на домене и скопировал ссылку из адресной строки:
http://web.archive.org/web/20180330034350/http://1mds.ru:80/
Мне нужны цифры после web/, я их выделил красным цветом. Это временная метка, когда была сделана копия. Теперь мне нужно найти первую копию блога и также скопировать из URL временную метку. Теперь у нас есть две метки с которой и до которой нам нужна копия сайта. Осталось дело за малым, установить утилиту, которая поможет нам скачать сайт. Для этого потребуется выполнить пару команд.
- sudo apt install ruby
- sudo gem install wayback_machine_downloader
После чего останется запустить скачивание сайта. Делается это вот такой командой:
wayback_machine_downloader -f20171223224600 -t20180330034350 1mds.ru
Таким образом мы скачаем архив с 23/12/2017 по 30/03/2018. Файлы сайта будут сохранены в домашней директории в папке «websites/1mds.ru». Теперь остается закинуть файлы на хостинг и радоваться результату.
Как просмотреть копию страницы?
Самый простой и доступный способ посмотреть копии сохраненной страницы — сделать это вручную. В этом помогает поисковая выдача Яндекса. Возле каждого пункта найденных страниц имеется небольшая зеленая стрелка, вызывающая контекстное меню. И среди пунктов есть «Сохраненная копия». Она моментально переведет пользователя на кэшированную страницу.
Более автоматизированный способ подразумевает использование разнообразных плагинов, показывающих последние сохраненные страницы поисковиков. Это может быть удобно при периодическом мониторинге продвижения ресурса в поисковой выдаче.
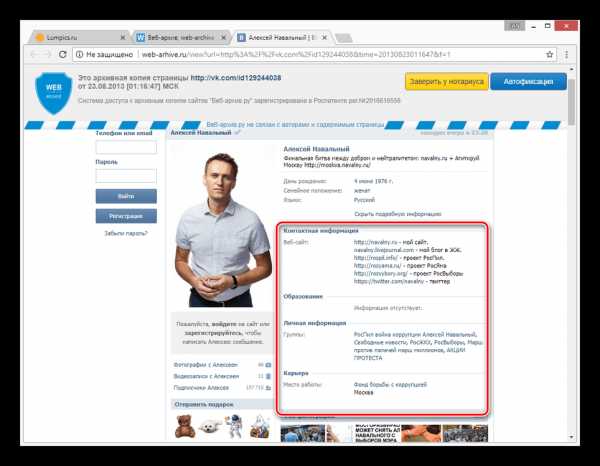
Как посмотреть, как выглядела страница ВКонтакте раньше

Пользовательские страницы ВКонтакте, включая и ваш персональный профиль, часто меняются под влиянием тех или иных факторов. В связи с этим становится актуальной тема просмотра раннего внешнего вида страницы, и для этого необходимо использовать сторонние средства.
Смотрим, как выглядела страница раньше
Первым делом нужно отметить, что просмотр ранней копии страницы, будь то действующий или уже удаленный аккаунт пользователя, возможен лишь тогда, когда настройки приватности не ограничивают работу поисковых систем. В противном случае сторонние сайты, включая сами поисковики, не могут кэшировать данные для дальнейшей демонстрации.
Подробнее: Как открыть стену ВК
Способ 1: Поиск Google
Наиболее известные поисковые системы, имея доступ к определенным страницам ВКонтакте, способны сохранять копию анкеты в своей базе данных. При этом срок жизни последней копии сильно ограничен, вплоть до момента повторного сканирования профиля.
- Воспользуйтесь одной из наших инструкций, чтобы найти нужного пользователя в системе Google.
Подробнее: Поиск без регистрации ВК
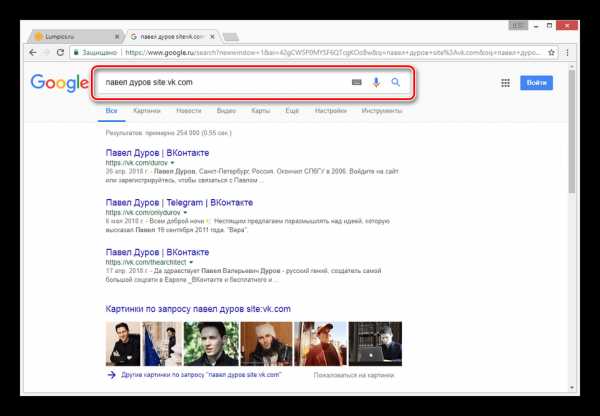
Среди представленных результатов отыщите нужный и кликните по иконке с изображением стрелочки, расположенной под основной ссылкой.
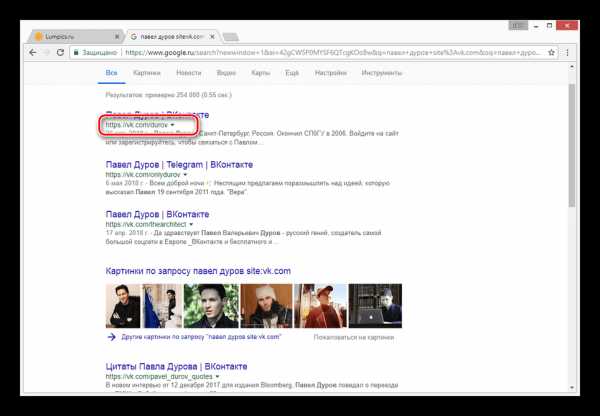
Из раскрывшегося списка выберите пункт «Сохраненная копия».
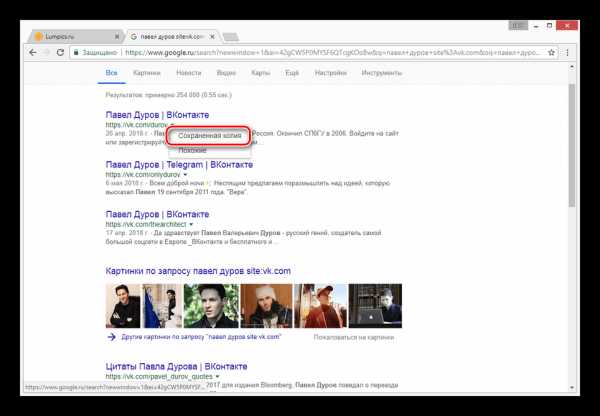
После этого вы будете перенаправлены на страницу человека, выглядящую в полном соответствии с последним сканированием.
Даже при наличии активной авторизации ВКонтакте в браузере, при просмотре сохраненной копии вы будете анонимным пользователем. В случае попытки авторизации вы столкнитесь с ошибкой или же система вас автоматически перенаправит на оригинальный сайт.
Допускается просмотр только той информации, что загружается вместе со страницей. То есть, например, посмотреть подписчиков или фотографии у вас не получится, в том числе из-за отсутствия возможности авторизации.
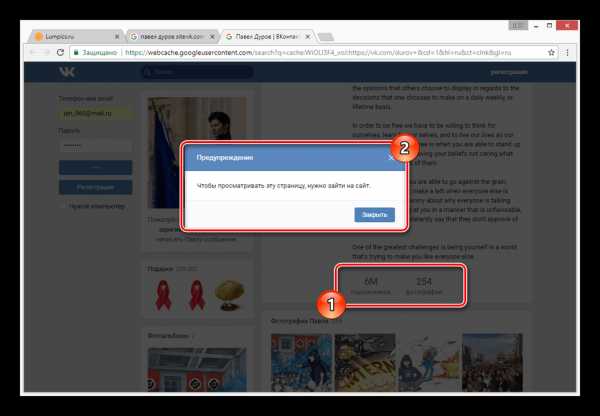
Использование этого метода нецелесообразно в случаях, когда необходимо найти сохраненную копию страницы очень популярного пользователя. Связано это с тем, что подобные аккаунты часто посещаются сторонними людьми и потому гораздо активнее обновляются поисковыми системами.
Способ 2: Internet Archive
В отличие от поисковых систем, веб-архив не ставит требований перед пользовательской страницей и ее настройками. Однако на данном ресурсе сохраняются далеко не все страницы, а только те, что были добавлены в базу данных вручную.
Перейти к официальному сайту Internet Archive
Главным отрицательным фактором способа является то, что любая информация на странице, за исключением вручную введенных данных, представлена на английском языке. Избежать этой проблемы можно, прибегнув к следующему сервису.
Способ 3: Web Archive
Данный сайт является менее популярным аналогом предыдущего ресурса, но со своей задачей справляется более чем хорошо. Кроме того, вы всегда можете воспользоваться этим веб-архивом, если ранее рассмотренный сайт по каким-либо причинам оказался временно недоступен.
Перейти к официальному сайту Web Archive
- Открыв главную страницу сайта, заполните основную поисковую строку ссылкой на профиль и нажмите кнопку «Найти».
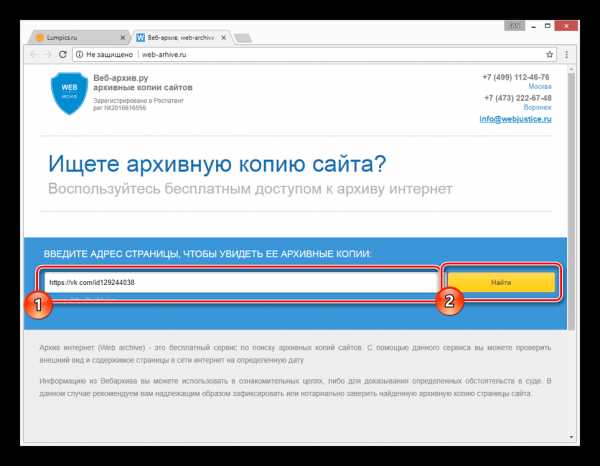
После этого под формой поиска появится поле «Результаты», где будут представлены все найденные копии страницы.
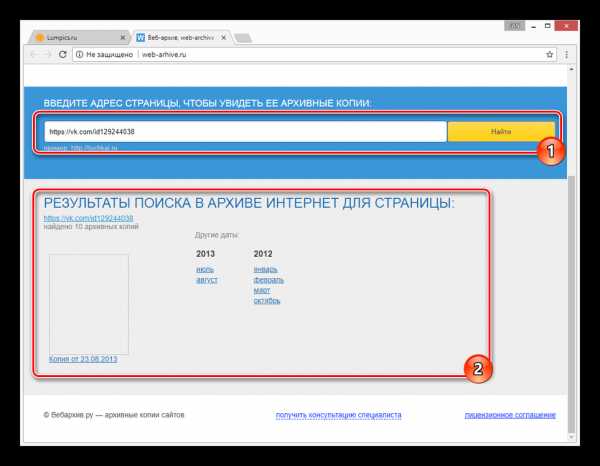
В списке «Другие даты» выберите колонку с нужным годом и кликните по наименованию месяца.
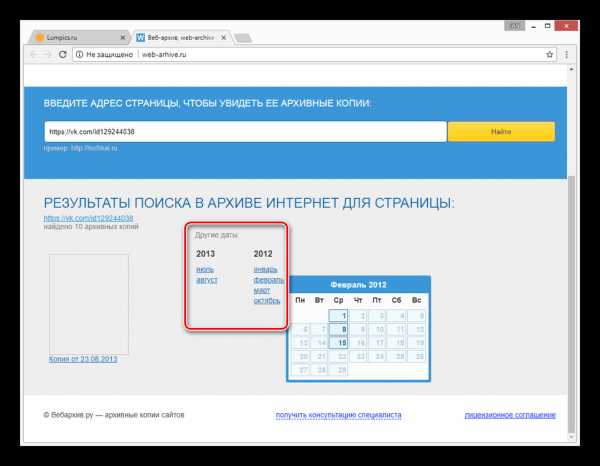
С помощью календаря кликните по одному из найденных чисел.
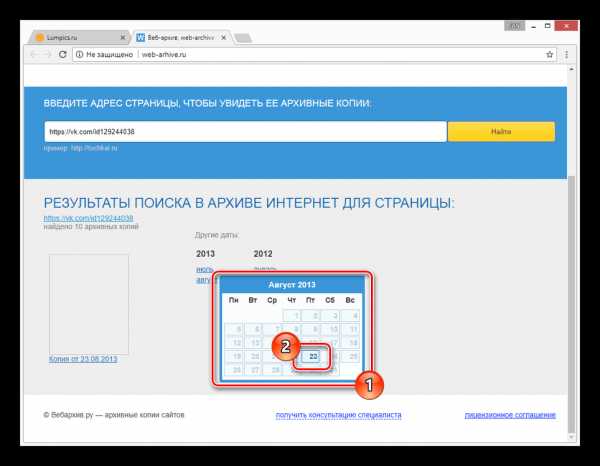
По завершении загрузки вам будет представлена анкета пользователя, соответствующая выбранной дате.
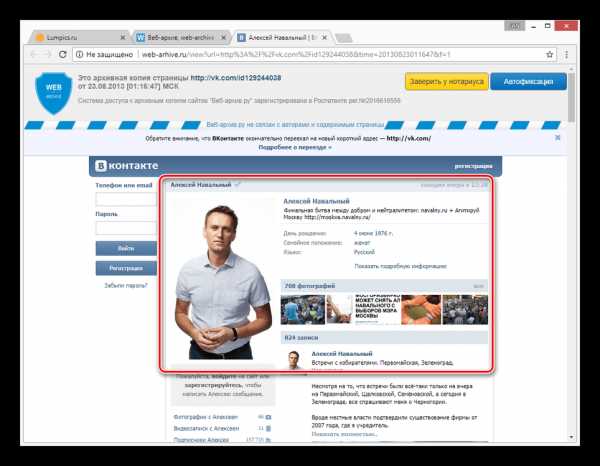
Как и в прошлом методе, все возможности сайта, кроме непосредственного просмотра информации, будут блокированы. Однако на сей раз содержимое полностью переведено на русский язык.
Вы также можете прибегнуть к еще одной статье на нашем сайте, рассказывающей о возможности просмотра удаленных страниц. Мы же завершаем данный способ и статью, так как изложенного материала более чем достаточно для просмотра ранней версии страницы ВКонтакте.
Мы рады, что смогли помочь Вам в решении проблемы.
Создание задачи
Вводим название задачи и переходим на следующий шаг к настройкам сбора. Тут есть чекбокс “Выбрать период”, чтобы скачать документы по установленной дате. Если чекбокс не будет активирован — система скачает документ по последней доступной дате.
Рекомендуем не включать этот чекбокс, если вы точно не знаете за какую дату вам нужна копия. Если домен, например, старый и вы точно знаете, за какую дату нужна копия, тогда просто выбираете в календаре:
Чекбоксы “Сделать пути относительными” и “Удалить счетчики статистики” рекомендуется всегда оставлять включенными — они помогут избежать различных проблем при переносе копии сайта на ваш сервер.
Далее, переходим на третий шаг и вводим адрес домена (без http и www), который нужно восстановить и после этого жмем “Добавить домен”:
Важно: на данный момент поддерживаются только задачи по 1 домену, поэтому если вам надо восстановить несколько сайтов, придется создать несколько задач. Далее нажимаем “Создать новую задачу” и подтверждаем запуск
Далее нажимаем “Создать новую задачу” и подтверждаем запуск.
Элементы сайта-истории
Любая история – это в первую очередь повествование. История на сайте – не исключение.
Повествование складывается из следующих элементов:
- Персонаж. Выступать в качестве персонажа может продукт компании, сам бренд или что-то еще. Может быть и вымышленный персонаж, который несет в себе собирательный образ, например, целевой аудитории компании.
- Конфликт (событие). В роли конфликта могут быть какие-либо волнующие целевую аудиторию проблемы. Ситуации, в которые попадает клиент и в решении которых может помочь компания.
- Действие. Это те действия, который должен совершить клиент, чтобы решить конфликт, проблему. И в истории рассказывается, какие это должны быть действия. Тут могут быть и действия, которые совершает компания, чтобы решить проблему клиента. Часто описывается конечный результат действий, положительные эмоции от использования продукта, счастье клиента после того, как проблема решена.
Как использовать архив
Веб-архив используют для следующих целей:
- восстановление собственного сайта, если он был по какой-либо причине утрачен либо поврежден;
- просмотр старой информации и медиа-контента, которого уже нет на работающих сайтах;
- анализ изменения выбранного ресурса с течением времени;
- поиск удаленной уникальной информации, которую затем можно использовать на собственном проекте.
Чтобы просмотреть старые версии нужного сайта, необходимо перейти на сервис веб-архива, указать адрес домена и нажать «BROWSE HISTORY»:
После этого отобразится временная шкала в диапазоне с даты основания ресурса по текущий момент. После клика мышью по году открывается календарь, в котором выбирается желаемая дата. Доступен выбор любой даты, отмеченной зеленым либо голубым кружком. Диаметр круга зависит от количества обращений робота веб-архива к проекту в этот день. Зеленый цвет обозначает редиректы. После выбора даты кликаем на нее для перехода на нужную версию сайта:
В некоторых случаях старые версии сайта могут отсутствовать в веб-архиве. Такое происходит, если правообладатель обратился с требованием удалить копии принадлежащего ему контента либо проект закрыли в связи с нарушением закона о защите интеллектуальной собственности. Бывает также, что разработчики закрыли возможность сканирования сайта роботами веб-архива.
Иногда нужный ресурс доступен, но могут отсутствовать картинки или элементы дизайна, тогда стоит открыть версию сайта, сохраненную в другой день.
Что такое веб-архив и зачем он нужен?
Веб-архив — история миллионов сайтов
Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Бесплатные способы восстановления
Ручной
Собственно основной ресурс, который используют все сервисы для восстановления сайта это https://archive.org/web/
Ниже отображается календарь за выбранный год, там вы можете увидеть конкретный месяц и день, когда был произведен снимок.
Кликайте по снимку, откроется окно со страницей сайта за тот день. Открываете консоль разработчика и копируете html и все ресурсы необходимые странице — картинки, css, js и др. Неблагодарное дело.
Аналоги archive.org
https://archive.org/web/ не единственый проект, который делает снимки сайтов и хранит их. Существуют и другие напримерArchive.ishttp://timetravel.mementoweb.org/ уникальный проект, своего рода гугл по сайтам-аналогам archive.org
Веб кэш
Если нужно восстановить данные сайта, которые были потеряны недавно, может подойти кэш поисковой системы Гугл. Можно попробовать тут https://thisis-blog.ru/posmotret-sajt-v-keshe/
Библиотеки
Можно развернуть и свою поделку под свои нужды, если есть возможность. На гитхабе ищется по ключу wayback-machine
Что там можно найти, примеры:
https://pypi.org/project/wayback-scraper/https://github.com/sangaline/wayback-machine-scraperhttps://github.com/hartator/wayback-machine-downloader
Делитесь своим опытом использования данных сервисов. Если нашли ошибку, либо есть что добавить, тоже пишите.
Утилиты для сохранения сайтов целиком
Есть программы для копирования ресурсов глобальной сети целиком. То есть со всем контентом, переходами, меню, ссылками. По такой странице можно будет «гулять», как по настоящей. Для этого подойдут следующие утилиты:
- HTTrack Website Copier.
- Local Website Archive.
- Teleport Pro.
- WebCopier Pro.
Есть много способов перенести страницу сайта на ПК. Какой выбрать — зависит от ваших нужд. Если хотите сохранить информацию, чтобы потом её изучить, достаточно обычного снимка экрана. Но когда надо работать с этими данными, редактировать их, добавлять в документы, лучше скопировать их или создать html-файл.
Проекты, предоставляющие историю сайта
Peeep.us в действии
Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Потеря исходных файлов
Самой частой причиной является удаление сайта с хостинга хостер-провайдером за неуплату (не продление услуги). Так же бывает, что владелец сайта не имеет доступа к хостингу или почте на которую зарегистрирован хостинг-аккаунт, так как все доступы находятся у разработчика который внезапно пропал. В первую очередь, это вина заказчика. Всегда регистрируйте аккаунты на свою электронную почту, чтобы не потерять доступ и вовремя получать уведомления об оплате.
Еще частой причиной являются вирусы. Например у пользователя нет исходных файлов сайта, а то что «лежит» на сервере заражено вредоносной программой. Причем найти источник вируса бывает достаточно проблематично.
Как использовать веб-архив?
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.
Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.
Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
Попытайте удачу в поисках архивной версии профиля на этих сайтах:
- archive.is;
- webcitation.org;
- freezepage.com;
- perma.cc.
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Виды сателлитов
У сайтов-спутников много разных классификаций. Давайте рассмотрим самые важные и интересные.
Первая классификация — по способу наполнения сайта. В зависимости от того, насколько основательно вы подошли к построению сайта и как часто обновляете на нем информацию, есть:
- Динамические: качественные проекты с обновляемым контентом, выполненные на популярных CMS.
- Статические: обычно создаются на готовых шаблонах без сложной структуры, наполнение таких сайтов не меняется.
- Дорвеи: их цель – перевод поискового трафика на другой сайт, поэтому такие сайты не обладают значимым контентом совсем.
Вторая классификация – по степени развития сайта. Актуальна для схемы трехуровневой сателлитовой сети. Суть в том, что сателлиты третьего уровня продвигают сайты второго уровня, а последние влияют на ресурсы первого уровня.
Подробнее о каждом:
- Третий уровень: используются рискованные методы продвижения, рассчитанные на скорость, а не на стойкий результат. Имеют неуникальный контент и большое количество некачественных внешних ссылок.
- Второй уровень: для этих сайтов используются уже менее агрессивные способы оптимизации. Контент для таких сателлитов все еще не эталонного качества, но обладает уже гораздо большей уникальностью.
- Первый уровень: продвижение этих сайтов похоже на продвижение ключевого проекта. Для них создается качественный контент, структура. Они имеют поисковый трафик сравнимый с основным сайтом.
Как посмотреть историю сайта
Конечно, после выполнения модернизации сайта есть желание его сравнить с теми версиями сайта, которые были раньше. Но если не знаешь, возникает вопрос, как посмотреть историю сайта, где её посмотреть? На помощь может прийти сервис archive.org. На сервисе archive.org собрано более, чем пол триллиона сайтов. Причем, каждый сайт (блог) представлен там, в различный период времени.
Например, Вы открываете сайт и хотите посмотреть, как он выглядел в феврале 2013 года. Вы действительно его увидите таким, каким он был в тот период времени. Опубликованные на блоге статьи сможете открыть и прочитать их, даже если автор эти статьи уже удалил. Вы можете проверить историю сайта за каждый месяц, за каждый год. Представляете, какой объём информации хранит сервис archive.org!
Многие люди пишут на форумах — archive.org заблокирован, как зайти? Действительно, если просто зайти по адресу первого сайта, то сервис archive.org почему то работает не корректно.
Итак, открывается окно сервиса archive.org, далее в поле нужно ввести доменное имя своего сайта и нажать кнопку «Browse history». Теперь выбираем дату архивирования своего сайта из встроенного календаря, сначала выбираем год, далее месяц и день.
День нужно выбирать тот, который отмечен голубым кружочком – нажимаем на дату. Теперь можем посмотреть историю нашего ресурса. Мы можем посмотреть историю сайта своего или чужого. А сейчас можете посмотреть видео, как узнать историю ресурса с помощью сервиса archive.org:
Как выглядел сайт раньше — пошаговая инструкция, как посмотреть
Как узнать, как сайт выглядел раньше?
Иногда хочется вспомнить те времена, когда по интернетам бродили динозавры, а одна песня загружалась 10 минут. Смотрим в прошлое и ностальгуем, спасибо за это онлайн-сервису: Wayback Machine – Internet Archive. Работает с 1996 года, за это время собрал в базе данных более 279 миллиардов веб-страниц.
Синими кругами на календаре обведены даты резервных копий. Выбираем нужный год, дату и заглядываем в прошлое веб-страницы.
Виртуальный хостинг сайтов для популярных CMS:
Где посмотреть, как выглядели страницы сайтов в разные годы.
Яндекс в это время открыл первый удаленный офис в Питере, запустил Яндекс.пробки и «словари». А майл.ру начали использовать поисковик на своем портале. Через год Яндекс купит разработчика мобильного софта «Смартком» и соц. сеть «Мой круг». Запустит «Календари», блого-сервис Я.ру, портал Яндекс.Mirror и откроет школу анализа данных — бесплатный образовательный курс.
запускают календарь, финансы и переводчик. Открывают бесплатный хостинг изображений Picasa и объявляют о покупке YouTube. В 2007 компания установит крупнейшую систему солнечных батарей (Сейчас она обеспечивает энергией 30% офисов) и объявит о появлении Android. А сотрудники начинают ездить по офисам на велосипедах gBikes.
История уникальна. Только в 2004 году сервис вышел за стены Гарварда, а уже в 2008 вырос так, что количество пользователей перевалило за 50 млн. человек, а состояние Марка Цукерберга уже оценивалось в 1.5 млдр. долларов.
r-tools.org
Первое, что бросается в глаза дизайн сайта стороват. Ребята, пора обновлять!
Плюсы:
- Подходит для парсинга сайтов у которых мало html страниц и много ресурсов другого типа. Потомучто они рассчитывают цену по html страницам
- возможность отказаться от сайта, если качество не устроило. После того как система скачала сайт, вы можете сделать предпросмотр и отказаться если качество не устроило, но только если еще не заказали генерацию архива. (Не проверял эту функцию лично, и не могу сказать на сколько хорошо реализован предпросмотр, но в теории это плюс)
- Внедрена быстрая интеграция сайта с биржей SAPE
- Интерфейс на русском языке
Минусы:
- Есть демо-доступ — это плюс, но я попробовал сделать 4 задания и не получил никакого результата.
- Высокие цены. Парсинг 25000 стр. обойдется в 2475 руб. , а например на Архивариксе 17$. Нужно учесть, что r-tools считает html страницы, архиварикс файлы. Но даже если из всех файлов за 17$ только половина html страницы, все равно у r-tools выходит дороже. (нужно оговориться, что считал при $=70руб. И возможна ситуация, когда r-tools будет выгоден написал про это в плюсах)
Что если сохраненной страницы нет?
Иногда в выдаче при нажатии на зеленую стрелку отсутствует пункт «Сохраненная копия». Этому может быть несколько причин:
- Иногда некоторые браузеры, в которых установлены плагины для блокировки рекламы, могут не отображать эту ссылку. Стоит попробовать приостановить плагин или удалить его и просмотреть сайт снова;
- Яндекс вообще не гарантирует попадание страницы сайта в сохраненные копии. То есть если ресурса нет, значит по какой-то причине поисковик решил не делать резервной копии. Ничего страшного, стоит проверить, не сохранила ли страницы сайта другая поисковая система — например, Google;
- Сайт отказал поисковым роботам в индексации своих страниц. Файл robots.txt, который может лежать в корне сайта, содержит инструкции для поисковых роботов, каким образом они должны сканировать его. Например, он может содержать требование не сканировать сайт совсем или сканировать только отдельные его страницы;
- Схожая с предыдущим пунктом причина. В html коде веб-ресурса может быть указан мета-тег Robots с атрибутом noarchive. Эта директива запрещает поисковому роботу делать копию сохраненной страницы.
Как выглядит сайт-история?
Помимо того, что здесь присутствует определенный сюжет, на сайтах-историях многое строится на взаимодействии визуальных частей и интерактивности. Применение техник сторителлинга на сайтах может быть весьма разнообразным. Порой они могут переплетаться с инфографикой, видео и т. п. Иногда сайты полностью основаны на сторителлинге, иногда – лишь частично.
Посмотрите на два сайта, при создании которых применялась техника визуального сторителлинга.
Нажмите для перехода
Нажмите для перехода
На самом деле сайты-истории очень разнообразны. Они могут рассказывать о том, как использовать тот или иной продукт компании, рассказывать о технологиях, которые применяются в производстве, или даже просто создавать определенное настроение у посетителя. Все зависит от целей компании.
Элементы сайта-истории
Любая история – это в первую очередь повествование. История на сайте – не исключение.
Повествование складывается из следующих элементов:
- Персонаж. Выступать в качестве персонажа может продукт компании, сам бренд или что-то еще. Может быть и вымышленный персонаж, который несет в себе собирательный образ, например, целевой аудитории компании.
- Конфликт (событие). В роли конфликта могут быть какие-либо волнующие целевую аудиторию проблемы. Ситуации, в которые попадает клиент и в решении которых может помочь компания.
- Действие. Это те действия, который должен совершить клиент, чтобы решить конфликт, проблему. И в истории рассказывается, какие это должны быть действия. Тут могут быть и действия, которые совершает компания, чтобы решить проблему клиента. Часто описывается конечный результат действий, положительные эмоции от использования продукта, счастье клиента после того, как проблема решена.
Это три основополагающих элемента хорошей истории. Как именно облечь их в визуальную форму на сайте — зависит от задачи
Главное здесь – это не упустить основную идею, отказаться от лишних отвлекающих внимание элементов, чтобы провести внимание зрителя от начала истории (сайта) до конца
Залог успеха — эмоциональная вовлеченность
Залогом успеха сайтов-историй является то, что они вызывают высокую эмоциональную вовлеченность. Они интересные, запоминаются, результативно транслируют нужные идеи.
По данным Koozai, сегодня люди сканируют контент, а не вникают в него
Ищут то, что их заинтересует, и останавливают на этом внимание. Если же контент не сможет выделиться из массы других сообщений и вызвать интерес, то можно считать, что он создан зря – то есть никогда не сможет выполнить возложенные на него функции
Техники сторителлинга позволяют создать сильный визуальный контент. Это понимает большинство маркетологов: по исследованиям Social Media Examiner, процент использования такого контента продолжает расти
Большое внимание уделяется видео. Видеоистории и их применение – в том числе и на сайтах – имеют решающее значение в эффективности маркетинговых кампаний
Исследования направлений движения глаз человека по веб-странице показывают, что пользователи сайтов обращают пристальное внимание на информативно насыщенные изображения. И, соответственно, проводят дольше времени на сайте, где эти изображения есть
И снова здесь выигрывают сайты, созданные с применением сторителлинга.
Есть и другие аспекты, которые влияют на результативность подобных сайтов.
Во-первых, они выделяются среди других, позволяют захватить внимание. Сегодня время, когда информации слишком много и из-за перенасыщенности различными рекламными сообщениями, брендам все труднее завладеть вниманием потенциальных клиентов
Использование историй помогает решить эту проблему. Ведь сама структура историй создаётся так, чтобы захватывать внимание зрителя и вести его от начала истории до конца.
Во-вторых, сообщение поданное с помощью сторителлинга легче для восприятия, это обусловлено тем, как наш мозг воспринимает информацию. А всем известный факт, если перегрузить внимание или сделать сообщение сложным, то оно перестанет работать. Чем проще, тем лучше.
Все это в комплексе и делает сайты-истории результативным инструментом достижения маркетинговых целей.
Сохранить как HTML-файл
Вот как сохранить страницу ресурса глобальной сети на компьютер в формате html. Впоследствии его можно будет конвертировать в другой тип. При таком копировании картинки с веб-портала помещаются в отдельную папку, которая будет иметь то же название, что html-файл, и находится в том же месте, что и он.
- Откройте сайт.
- Кликните правой кнопкой мышки в любом месте, свободном от рисунков, фонов, видео и анимации.
- Выберите «Сохранить как». В Mozilla Firefox аналогичную кнопку можно найти в меню. Для этого нужно нажать на значок с тремя горизонтальными чёрточками. В Opera эти настройки вызываются кликом на логотип.
- Задайте имя. Укажите путь.
- Подтвердите действие.