Программы для работы с субд mysql
Содержание:
- Ограничение доступа к данным
- Отношения между таблицами
- CiteSeerX — Научные публикации и препринты
- MySQL
- Azure Data Studio
- Планы на будущее
- SQLite3 manager LITE
- Наукометрические базы данных – что это и зачем нужны?
- RAWGraphs
- MySQL, Navicat и другие
- Создаем базу данных
- Структура нового фреймворка
- Сколько стоит бесплатный сыр
- Как хранится информация в БД
- Виды баз данных и их структура, примеры
- Разное
Ограничение доступа к данным
- Шифрование и обфускация процедур и функций (Wrapping) — то есть отдельные инструменты и утилиты, которые из читаемого кода делают нечитаемый. Правда, потом его нельзя ни поменять, ни зарефакторить обратно. Такой подход иногда требуется как минимум на стороне СУБД — логика лицензионных ограничений или логика авторизации шифруется именно на уровне процедуры и функции.
- Ограничение видимости данных по строкам (RLS) — это когда разные пользователи видят одну таблицу, но разный состав строк в ней, то есть кому-то что-то нельзя показывать на уровне строк.
- Редактирование отображаемых данных (Masking) — это когда пользователи в одной колонке таблицы видят или данные, или только звездочки, то есть для каких-то пользователей информация будет закрыта. Технология определяет, какому пользователю что показывать с учетом уровня доступа.
- Разграничение доступа Security DBA/Application DBA/DBA — это, скорее, про ограничение доступа к самой СУБД, то есть сотрудников ИБ можно отделить от database-администраторов и application-администраторов. В open source таких технологий немного, в коммерческих СУБД их хватает. Они нужны, когда много пользователей с доступом к самим серверам.
- Ограничение доступа к файлам на уровне файловой системы. Можно выдавать права, привилегии доступа к каталогам, чтобы каждый администратор получал доступ только к нужным данным.
- Мандатный доступ и очистка памяти — эти технологии применяют редко.
- End-to-end encryption непосредственно СУБД — это client-side шифрование с управлением ключами на серверной стороне.
- Шифрование данных. Например, колоночное шифрование — когда вы используете механизм, который шифрует отдельную колонку базы.
Как это влияет на производительность СУБД?
Проведем тест c pgcrypto
Выборка из таблицы без функции шифрования
Время: 1,386 мсВыборка из таблицы с функцией шифрования:
Время: 50,203 мсРезультаты тестирования
| Без шифрования | Pgcrypto (decrypt) | |
| Выборка 1000 строк | 1,386 мс | 50,203 мс |
| CPU | 15% | 35% |
| ОЗУ | +5% |
Пример такого шифрования в MongoDB
Отношения между таблицами
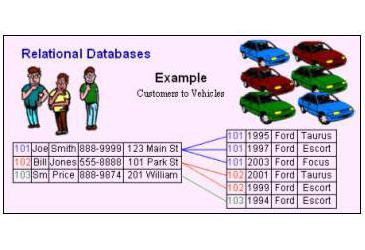
Чтобы база данных стала реляционной, одних данных мало. Между ними нужны еще и связи (те самые relations, от которых и пошло слово «реляционный»).
Для связи между таблицами служит так называемый внешний ключ (foreign key). Название довольно точно выражает его суть. Если в таблице A есть столбец для хранения первичного ключа таблицы B, то такой столбец и называется внешним ключом. Первичные и внешние ключи устанавливают связи между таблицами, превращая набор таблиц в цельную конструкцию — реляционную базу данных.
Приведу пример. Допустим, мы создали еще одну простую таблицу — справочник товаров. Назовем ее GOODS.
| Товарный справочник GOODS | ||||
| ID | NAME | PRICE | UNIT | COUNTRY |
| 1 | Яблоки | 50.00 | кг | Россия |
| 2 | Груши | 60.40 | кг | Франция |
| 3 | Апельсины | 40.00 | кг | Марокко |
| 4 | Макароны | 21.00 | шт | Франция |
| 5 | Кефир | 25.30 | шт | Россия |
| 6 | Молоко | 30.50 | шт | Россия |
Ее колонки: ID — первичный ключ, NAME — название товара, PRICE — его цена, UNIT — краткое название единицы измерения, COUNTRY — название страны-производителя.
Хорошо ли построена такая таблица? Вроде бы всем упоминавшимся выше принципам она удовлетворяет: уникальные имена столбцов с однородными данными, строки с уникальным первичным ключом. Казалось бы, все на месте. Тем не менее построена она непрофессионально. Здесь мы подходим к принципам, о которых я еще не упоминал, — к понятию о нормализации таблиц. Суть в том, чтобы всюду, где только можно, избегать избыточности в хранении данных путем выделения их в отдельные таблицы.
Посмотрим на нашу таблицу GOODS. Чем она плоха? Представьте себе, что завтра придется изменить название какой-нибудь страны. Такое случается часто. Бирма когда-то меняла свое название на Мьянму, Польша — на Польскую Республику. Хочется ли вам менять огромное количество строк во всех таблицах, где эти страны упоминаются? Представьте также, что вас попросят отобрать запросом весь штучный товар. Можете ли вы быть уверены в том, что оператор всюду набил эту аббревиатуру правильно и одинаково? Скорее всего, окажется, что в таблице встречаются все мыслимые вариации: «шт», «Шт», «шт.», «штук» и «штуки».
Думаю, проблема понятна. Выходом из этой ситуации будет выделение из нее двух других таблиц: справочника стран (COUNTRIES) и справочника единиц измерений (UNITS).
| Справочник единиц измерения UNITS | ||
| ID | NAME | SHORT_NAME |
| 1 | Штуки | шт |
| 2 | Килограммы | кг |
Сам справочник товаров GOODS будет теперь выглядеть совершенно по-другому (см. таблицу).
| Товарный справочник GOODS после нормализации | ||||
| ID | NAME | PRICE | UNIT_ID | COUNTRY_ID |
| 1 | Яблоки | 50.00 | 2 | 1 |
| 2 | Груши | 60.40 | 2 | 2 |
| 3 | Апельсины | 40.00 | 2 | 3 |
| 4 | Макароны | 21.00 | 1 | 2 |
| 5 | Кефир | 25.30 | 1 | 1 |
| 6 | Молоко | 30.50 | 1 | 1 |
Что изменилось? Вместо столбцов с названиями единиц измерения и стран появились столбцы UNIT_ID и COUNTRY_ID с кодами, отсылающими нас к другим таблицам. Это и есть внешние ключи. Что означает значение 2 в столбце UNIT_ID? Оно означает, что интересующая нас информация по единице измерения находится той строке таблицы UNITS, где ID = 2. Достаточно заглянуть в этот справочник, чтобы убедиться, что называется эта единица полностью «штуки», а кратко — «шт».
Объяснение всех видов и принципов нормализации выходит далеко за рамки данной статьи. Главное — почувствовать общие принципы. Единожды научившись строить базы данных правильно, вы уже не сможете иначе. Для этого не обязательно знать теорию в полном объеме — зачастую здравого смысла и интуиции бывает достаточно.
Вернемся к нашей маленькой базе данных. Ну хорошо, нормализовали мы таблицу. Сможем теперь менять названия стран, не исправляя всю таблицу. Замечательно. Но как теперь увидеть эти названия? Ведь в справочнике товаров появились коды, и таблица сразу потеряла свою наглядность.
Вот тут-то мы и подходим к понятию уже не раз упоминавшихся запросов, которые, используя связи, извлекают из них нужную информацию и выдают нам опять же в виде так называемой отчетной таблицы.
CiteSeerX — Научные публикации и препринты
Бесценным инструментом для студентов, а также и для преподавателей является общедоступный поисковый движок и цифровая библиотека учебных и научных работ CiteSeerX. Эта база данных часто считается первой автоматизированной системой индексации цитирования, причем она оказала влияние на создание поисковых систем Google Scholar и Microsoft Academic Search. Впрочем, последняя из указанных была интегрирована в поисковик Bing.
В CiteSeerX индексированы документы, предназначенные для общеобразовательных школ. Если научный документ распространяться открыто, то много шансов, что он появится в этой поисковой системе. CiteSeerX является прекрасным примером предоставления общих знаний для очень широкой аудитории.
MySQL
Самый именитый представитель нашего обзора программ для разработки базы данных. Бесплатная база данных MySQL существует с 1995 года и теперь принадлежит компании Oracle. СУБД имеет открытый исходный код. Также существует несколько платных версий, которые предлагают дополнительные функции, такие как гео-репликация кластера и автоматическое масштабирование.
Поскольку MySQL является отраслевым стандартом, она совместима практически со всеми операционными системами и написана на языках C и C ++. Это решение является отличным вариантом для международных пользователей. Сервер СУБД может выводить клиентам сообщения об ошибках на нескольких языках.
Достоинства
- Проверка на стороне сервера;
- Может использоваться как локальная база данных;
- Гибкая система привилегий и паролей;
- Безопасное шифрование всего трафика паролей;
- Библиотека, которая может быть встроена в автономные приложения;
- Предоставляет сервер в качестве отдельной программы для сетевого окружения клиент/сервер.
Недостатки практической разработки и администрирования баз данных MySQL Приобретена компанией Oracle:
- пользователи полагают, что MySQL больше не подпадает под категорию бесплатного и открытого программного обеспечения;
- больше не поддерживается сообществом;
- пользователи не могут исправлять ошибки и патчи;
- проигрывает другим решениям из-за медленных обновлений.
Azure Data Studio
Azure Data Studio – это бесплатный, кроссплатформенный инструмент с открытым исходным кодом для работы с базами данных Microsoft SQL Server.
Azure Data Studio основана на Visual Studio Code и ориентирована на SQL разработчиков, так как основное назначение Azure Data Studio – это написание, редактирование и выполнение SQL запросов, иными словами, это редактор SQL кода.
Azure Data Studio позволяет работать с базами данных Microsoft SQL Server, SQL Azure, а также с другими СУБД, например, с PostgreSQL
Основные особенности
Инструмент бесплатный
Кроссплатформенность (поддержка Windows, Linux, macOS)
Ориентация на SQL разработчиков
Продвинутый SQL редактор (технология IntelliSense, фрагменты SQL кода)
Расширяемость (встроенная поддержка расширений)
Работа с другими СУБД
Встроенная возможность выгрузки данных в формат Excel, XML, JSON, CSV
Группировка подключений к серверам
Визуализация данных с помощью диаграмм и графиков
Поддержка нескольких цветовых тем
Встроенный терминал (Bash, PowerShell, sqlcmd)
Записные книжки
Недостатки
Отсутствует конструктор таблиц
Нет функционала для работы со свойствами объектов
Отсутствует возможность управления безопасностью
Отсутствует возможность импорта и экспорта DACPAC
Отсутствует функционал для большинства задач администрирования
Мне нравится2Не нравится
Планы на будущее
Во фреймворке заложены основные возможности, которые я хотел в нем видеть. Он вполне работоспособен, но тем не менее ту стадию, на которой он находится в данный момент, я бы назвал только концептом.
Так, например, на данный момент существует backend, который позволяет фреймворку работать только с базой данных MySQL, из-за чего его можно запустить только на Electron. Также не реализован интерфейс для работы на мобильных устройствах и ряд других возможностей.
Ближайшие планы по развитию фреймворка:
- Реализовать механизмы объединения и группировок в запросах в классе Query.
- Добавить элементы управления для работы с объединениями и группировками.
- Разработать backend для преобразования объекта Query в json или xml, а также разработать серверную часть для работы с моделями Django.
- Реализовать механизм кеширования запросов к серверу данных.
- Воплотить в жизнь большое количество других идей.
SQLite3 manager LITE
Сайт производителя: http://www.pool-magic.net/sqlite-manager.htm
Цена: .
| Критерий | Оценка (от 0 до 2) | |
| Функциональность | 2 | |
| Цена | 2 | |
| Работа с UTF-8 | ||
| Русский интерфейс | ||
| Удобство | 1 | |
| Итог | 5 |
По сравнению с предыдущей программой “SQLite3 manager LITE” выглядит более функциональным. Кроме того, что можно просто просматривать данные в таблицах, также можно просматривать и создавать триггеры, индексы, представления и т.д. Дополнительно можно экспортировать все мета-данные базы данных. При этом можно создавать файлы с данными для экспорта таблиц в Paradox и Interbase.
Также в программе была предпринята попытка зделать, что-то вроде визуального мастера создания запросов наподобие MS Access, но, на мой взгляд, попытка успехом не увенчалась.
У бесплатной версии есть один недостаток – не понимает данные в кодировке UTF-8. Есть, конечно, возможность указать кодировку базы данных при открытии файла, но в списке кодировок UTF-8 отсутствует. Как работает Full-версия программы я так и не увидел, т.к. на сайте производителя чёрт ногу сломит. Висит какой-то непонятный javascript, выводящий непонятную инфу. В общем, сложилось впечатление, что проект успешно заглох.
Наукометрические базы данных – что это и зачем нужны?
Для оценивания успешности ученых используют качественные и количественные показатели. В основе качественных лежат выводы экспертов из различных областей знаний. Такой метод трудно назвать достоверным, ведь подобные оценки субъективны – мнения ученых по одним и тем же вопросам могут сильно расходиться.
К количественным показателям относят публикуемые материалы – количество публикаций и частота их цитирований, число премий, стипендий, грантов, индекс Хирша, импакт-фактор, участие в составе редколлегии, сотрудничество с иностранными партнерами. Основными показателями успешности ученого считаются:
- Импакт-фактор – параметр определяет число цитирований конкретного научного труда за последние два года.
- Индекс Хирша – характеристика учитывает количество публикаций автора и число их цитирований (например, при наличии 5 статей у исследователя, на каждую из которых ссылаются не менее 5 раз, h-индекс составит 5).
- Индекс цитирования – показатель значимости научной работы одного ученого или целого коллектива, определяемый числом ссылок на эту работу или фамилию автора.
Ключевые данные получают из наукометрических баз данных. Это библиографические и реферативные источники информации, содержащие инструменты для отслеживания цитируемости различных публикаций. Помимо этого, наукометрическая база данных представляет собой собрание научных работ исследователей на любые темы, из которых легко находить интересующие материалы.
Через инструменты баз данных узнают:
- востребованность определенных статей;
- индексы влияния ученых, написавших эти труды;
- частоту размещения публикаций конкретными авторами или научными организациями.
В то же время базы данных помогают систематизировать и хранить различные публикационные материалы, искать литературные источники при написании собственного труда, оценивать себя, коллег и конкурентов, сравнивать журналы, научные организации, грантовые фонды. Наличие публикаций в одной из наукометрических баз данных – обязательное условие для защиты диссертации и успешного развития ученого в научном мире, его продвижения по карьерной лестнице.
Чтобы войти в определенную базу, журнал должен выполнить определенные условия. Это ряд требований, предъявляемых к содержанию, оформлению и количеству публикаций, составу редколлегии, периодичности выпусков, качеству работы сайта и его наполнения, размещению материалов на английском языке. Проверяют наличие изданий в определенных базах на их официальных сайтах.
RAWGraphs
RAWGraphs
Сильные стороны бесплатной версии
- Диаграммы в RAWGraphs очень просто создавать, для работы с системой не нужно даже регистрировать учётную запись.
- Система поддерживает различные форматы входных данных — TSV, CSV, DSV, JSON и Excel-файлы(.xls, .xlsx).
- По сведениям RAWGraphs обработка данных производится исключительно средствами браузера. Платформа не занимается серверной обработкой или хранением данных. Никто из тех, кто не имеет отношения к данным, не сможет их просматривать, модифицировать или копировать.
- RAWGraphs — это система, поддающаяся расширению. Например, добавлять в неё новые диаграммы можно, обладая базовыми знаниями D3.js.
Слабые стороны бесплатной версии
- Диаграммы, создаваемые в RAWGraphs, иногда выглядят слишком простыми. У пользователей системы есть не особенно много механизмов для подстройки их под свои нужды.
- Визуализации данных не являются интерактивными.
В результате пришлось полностью отказаться от использования модуля Django Admin и клиентскую часть писать самостоятельно на JavaScript с использованием вышеуказанных технологий. Так был решен вопрос с интерактивностью, но время, которое стало уходить на создание интерфейсов, было неоправданно большим. Иногда, чтобы сэкономить время, для сбора и анализа данных я использовал чистый Mysql с клиентской частью в виде Navicat. Как оказалось, благодаря триггерам и видам, это не самое плохое решение, а огромное число задач решаются таким образом довольно просто (что не удивительно, ведь, согласно википедии, Mysql и создавался первоначально для решения подобных задач).
Создаем базу данных
Управление базами данных как объектами
Будем считать, что наша небольшая экскурсия по запросам и командам SQL со стороны «торгового зала» завершена. Заглянем теперь в его «служебные помещения» и познакомимся с тем, как создается сама база данных. Эта часть языка SQL не столь стандартизирована и сильно отличается в различных реализациях. Поэтому в дальнейших примерах я буду придерживаться синтаксиса, принятого в самой популярной на веб-серверах системе — MySQL.
MySQL — продукт шведской компании MySQL AB. Ее основатели — Дэвид Аксмарк, Аллан Ларсон и Майкл Видениус (последний больше известен по прозвищу — Монти). По одной из версий, первая часть названия продукта (My) — не что иное, как англизированная запись имени дочери М. Видениуса. Однако точно за происхождение названия сегодня не могут поручиться даже отцы-создатели. Существует версия, по которой «my» — это префикс, с которого начинались названия рабочих каталогов на их компьютерах.
Из всех команд чаще всего нам будут нужны три: CREATE (создать), ALTER (изменить) и DROP (уничтожить).
Чтобы создать новую базу данных с названием, ну скажем, OUR_SHOP, следует выполнить команду:
Еще лучше сразу при ее создании установить нужную кодировку (ведь по умолчанию в MySQL используется latin1). В итоге команда будет выглядеть так.
Если вы забыли сделать это сразу, не беда. Для того и существуют команды по изменению:
Когда, наигравшись вдоволь с пробной базой данных, вы захотите ее уничтожить, воспользуйтесь командой:
Управление таблицами
Чтобы создать таблицу GOODS, на которой мы отрабатывали манипуляции с данными, потребуется составить команду примерно такого вида:
Разберем эту команду подробнее. Тип INT устанавливается для столбцов с целочисленными данными, тип VARCHAR(100) обеспечивает хранение строк с длиной не более 100 символов, DECIMAL(10,2) соответствует действительным числам с не более чем десятью знаками и точностью в два знака после запятой.
Столбец ID объявлен первичным ключом (PRIMARY KEY).
Ключевое слово AUTO_INCREMENT означает, что при добавлении новых строк с неуказанным значением ID оно будет автоматически заполняться следующим значением. Это удобно, поскольку обычно нет нужды вручную указывать значения первичных ключей, а за тем, чтобы они были уникальными, пусть лучше следит база данных.
NOT NULL означает запрет на пустые значения в столбце, иными словами, гарантирует обязательность заполнения.
Команда DEFAULT задает значение по умолчанию — то, которое будет записываться в базу при добавлении новой строки, если не указано иное. В нашем случае она обеспечивает автоматическое объявление товара штучным (код = 1) в случае, если при добавлении новых строк не будет указан другой код.
Признак UNIQUE обеспечивает уникальность значений в колонке (в нашем случае — уникальность названий товаров).
Если в будущем вы захотите перенастроить объявленные командой CREATE столбцы таблицы, сделать это можно командой ALTER. Например, таблицу GOODS можно нарастить строчной колонкой REMARK (подкоманда ADD):
Поработав с ней немного и убедившись, что 50 символов для примечания явно недостаточно, увеличиваем максимальный размер строки до 250 (блок CHANGE):
Так как имя столбца мы не изменяли (новое совпадает со старым), то его просто повторяем в этой команде (как бы меняем само на себя).
И наконец, убедившись через какое-то время, что без примечания в товарном справочнике вполне можно обойтись, мы удаляем ставшую ненужной колонку (блок DROP):
Удалить таблицу целиком можно командой DROP:
Стоит ли говорить о том, что пользоваться командами с этим ключевым словом следует с особой осторожностью?
Структура нового фреймворка
Фреймворк заточен на быстрое создание интерфейсов для СУБД. Он состоит из нескольких частей (модулей). Некоторые могут использоваться отдельно, некоторые — только совместно с остальными.
Модуль core содержит механизмы описания моделей, взаимодействия объектов (записей) данных между собой, механизмы описания запросов к базе данных. Модуль core обращается к источникам данных через модуль backend.
Модуль backend — это прослойка между модулем core и базой (источником) данных. В качестве источника данных может выступать как непосредственно сервер баз данных, вроде SQL, так и прослойка для доступа к моделям других фреймворков, таких как Django или Sequelize.
Модуль model-ui отвечает за генерацию интерфейса: он визуализирует данные, предоставляемые модулем core, используя элементы управления, предоставляемые модулем ui.
Модуль ui содержит базовые элементы управления, которые используются модулем model-ui при генерации интерфейса. Эти элементы могут использоваться также и независимо от фреймворка.
Модуль windows-manager управляет контейнерами для отображения пользовательских интерфейсов. В зависимости от типа windows-manager приложения можно разворачивать как на компьютерах, так и на мобильных устройствах.
Сколько стоит бесплатный сыр
Стоимость владения
Для баз данных, как и для любого софта, существует понятие полной стоимости владения (Total Cost of Ownership, TCO).
Приобретая программный продукт, мы вкладываем деньги не только в лицензии — для того чтобы получить какой-то эффект от приобретения и заставить ПО реально работать, необходимо затратить деньги и на множество сопутствующих вещей.
Вообще говоря, ТСО — это схема для вычисления всех затрат, связанных с ПО. Таких схем существует несколько, и компании-производители программного обеспечения постоянно соревнуются в снижении этого показателя (причем обычно выигрывает тот, кто измеряет).
Традиционно считается, что ТСО состоит из трех частей:
стоимость аппаратного обеспечения;
стоимость программного обеспечения;
стоимость персонала, необходимого для обслуживания ПО.
Посчитали — прослезились…
Прежде всего, конечно, стоит обратиться к стоимости персонала. Хорошо известно, что для нормального функционирования системы на той же Oracle нужен профессиональный администратор базы данных. Конечно, пока система внедряется, эту работу обычно выполняют разработчики, но потом без администратора не обойтись. Сколько нужно платить толковому администратору, можете выяснить сами.
Затем — hardware. 1 Гбайт оперативной памяти для системы, основанной, скажем, на Firebird и обслуживающей 30–50 пользователей, вполне достаточно, тогда как для Oracle потребуется куда больше.
И несколько слов о стоимости программного обеспечения. Да, сама СУБД бесплатна, но стоит посмотреть, есть ли для нее все необходимые драйверы, инструменты администратора и разработчика, и главное, сколько они стоят!
И рос он не по годам, а по часам
С ограничением размера базы данных, прямо скажем, загвоздка. Сейчас часто нужно хранить в базах данных фотографии и видеоматериалы, а для данных такого рода 4 Гбайт недостаточно. Поэтому, если в вашем проекте предусмотрено хранение мультимедии, нужна СУБД без ограничений на размер базы данных.
Вход бесплатно, выход — нет
Все новые «коммерческие бесплатные» базы данных рассчитаны на то, чтобы через «попробовать» молодые разработчики и целые компании становились адептами этих СУБД или просто клиентами, покупая и используя в своей работе их базы данных.
Немаловажен и другой вопрос — как долго будут поддерживаться бесплатные версии СУБД? Например, компания Borland, выпустив в 2000 году InterBase 6 Open Edition, которую стали использовать миллионы разработчиков, выпустила только два небольших апдейта, после чего вернулась к коммерческой модели, прекратив поддержку Open Edition. И если бы не появление Firebird, то выбравшие Inter-Base 6 Open Source разработчики должны были бы либо купить лицензии новых версий InterBase, либо переходить на другие СУБД.
Обратите внимание, что многие «бесплатные» СУБД не открывают своих кодов, поэтому ситуация очень напоминает мышеловку: бегите сюда, мыши, кушайте сыр, мышеловка скоро захлопнется!
Как хранится информация в БД
В основе всей структуры хранения лежат три понятия:
- База данных;
- Таблица;
- Запись.
База данных
База данных — это высокоуровневное понятие, которое означает объединение совокупности данных, хранимых для выполнения одной цели.
Если мы делаем современный сайт, то все его данные будут храниться внутри одной базы данных. Для сайта онлайн-дневника наблюдений за погодой тоже понадобится создать отдельную базу данных.
Таблица
По отношению к базе данных таблица является вложенным объеком. То есть одна БД может содержать в себе множество таблиц.
Аналогией из реального мира может быть шкаф (база данных) внутри которого лежит множество коробок (таблиц).
Таблицы нужны для хранения данных одного типа, например, списка городов, пользователей сайта, или библиотечного каталога.
Таблицу можно представить как обычный лист в Excel-таблице, то есть совокупность строк и столбцов.
Наверняка каждый хоть раз имел дело с электронными таблицами (MS Excel).
Заполняя такую таблицу, пользователь определяет столбцы, у каждого из которых есть заголовок. В строках хранится информация.
В БД точно также: создавая новую таблицу, необходимо описать, из каких столбцов она состоит, и дать им имена.
Запись
Запись — это строка электронной таблицы.
Это неделимая сущность, которая хранится в таблице. Когда мы сохраняем данные веб-формы с сайта, то на самом деле добавляем новую запись в какую-то из таблиц базы данных. Запись состоит из полей (столбцов) и их значений. Но значения не могут быть какими угодно.
Определяя столбец, программист должен указать тип данных, который будет храниться в этом столбце: текстовый, числовой, логический, файловый и т.д. Это нужно для того, чтобы в будущем в базу не были записаны данные неверного типа.
Соберем всё вместе, чтобы понять, как будет выглядеть ведение дневника погоды при участии базы данных.
- Создадим для сайта новую БД и дадим ей название «weather_diary».
- Создадим в БД новую таблицу с именем «weather_log» и определим там следующие столбцы:
- Город (тип: текст);
- День (тип: дата);
- Температура (тип: число);
- Облачность (тип: число; от 0 (нет облачности) до 4 (полная облачность));
- Были ли осадки (тип: истина или ложь);
- Комментарий (тип: текст).
- При сохранении формы будем добавлять в таблицу weather_log новую запись, и заполнять в ней все поля информацией из полей формы.
Теперь можно быть уверенными, что наблюдения наших пользователей не пропадут, и к ним всегда можно будет получить доступ.
Реляционная база данных
Английское слово „relation“ можно перевести как связь, отношение.
А определение «реляционные базы данных» означает, что таблицы в этой БД могут вступать в отношения и находиться в связи между собой.
Что это за связи?
Например, одна таблица может ссылаться на другую таблицу. Это часто требуется, чтобы сократить объём и избежать дублирования информации.
В сценарии с дневником погоды пользователь вводит название своего города. Это название сохраняется вместе с погодными данными.
Но можно поступить иначе:
- Создать новую таблицу с именем „cities“.
- Все города в России известны, поэтому их все можно добавить в одну таблицу.
- Переделать форму, изменив поле ввода города с текстового на поле типа «select», чтобы пользователь не вписывал город, а выбирал его из списка.
- При сохранении погодной записи, в поле для города поставить ссылку на соответствующую запись из таблицы городов.
Так мы решим сразу две задачи:
- Сократим объём хранимой информации, так как погодные записи больше не будут содержать название города;
- Избежим дублирования: все пользователи будут выбирать один из заранее определённых городов, что исключит опечатки.
Связи между таблицами в БД бывают разных видов.
В примере выше использовалась связь типа «один-ко-многим», так как одному городу может соответствовать множество погодных записей, но не наоборот!
Бывают связи и других типов: «один-к-одному» и «многие-ко-многим», но они используются значительно реже.
Виды баз данных и их структура, примеры
Выделяют несколько видов баз данных. Основными из них являются:
- Фактографическая, с краткой информацией об объектах какой-то системы, формат которой строго фиксирован.
- Документальная, включает документы разного вида, в том числе текстовые, графические, звуковые, мультимедийные.
- Распределенная, является базой данных с разными частями, которые хранятся на различных компьютерах, объединенных в сеть.
- Централизованная, представляет собой базу данных, местом хранения которой является один компьютер.
- Реляционная, имеет табличную организацию данных.
- Неструктурированная (NoSQL), является базой данных, в которой делается попытка решить проблемы масштабируемости и доступности с помощью атомарности и согласованности данных без четкой структуры.
Базы данных разных систем обладают неодинаковой структурой. Для ПЭВМ характерно использование реляционных баз данных с файлами в виде таблиц, в которых столбцы являются полями, а строки – записями. В базе данных находятся данные определенного множества объектов. Для каждой записи характерна информация по одному объекту. Такую базу определяют:
- имя файла;
- список полей;
- ширина полей.
В качестве примера можно привести школьную базу с данными «Ученик», «Класс», «Адрес». Также базой данных является расписание движения поездов или автобусов. В этом случае каждой строке соответствует запись с данными конкретного объекта. Возможные поля: номер рейса, маршрут, время отправления и прибытия. Классической базой данных является телефонный справочник.
Определение
Запрос к базе данных – предписание с указанием на данные, которые необходимы пользователю.
Примечание
В случае некоторых запросов требуется составление сложной программы. К примеру, для выполнения запроса к базе в виде автобусного расписания необходимо вычислить разницу в среднем интервале отправления транспорта из одного города во второй и из второго пункта в третий.
Существует три звена для создания приложения, с помощью которого можно просматривать и редактировать базы данных:
- набор данных;
- источник информации;
- визуальные компоненты управления.
В случае Access роль таких звеньев выполняют:
- Table.
- DataSource.
- DBGrid.
Приложения базы данных является нитью, которая связывает базу и пользователя:
БД => набор данных –=> источник данных => визуальные компоненты => пользователь
Набор данных:
- Table, в виде таблицы, навигационного доступа;
- Query, включая запрос, реляционный доступ.
Визуальными компонентами являются:
- Сетки DBGrid, DBCtrlGrid.
- Навигатор DBNavigator.
- Разные аналоги Lable, Edit.
- Компоненты подстановки.
Access характеризуется наличием следующих типов полей:
- текстовый, в виде текстовой строки с максимальной длиной до 255, заданной параметром «размер»;
- поле МЕМО, является текстом длиной до 65535 символов;
- числовой, в параметре «Размер поля» можно задать поле: байт, целое, действительное и другие;
- дата/время, необходимо для записи данных о времени;
- денежный, является специальным форматом для решения финансовых задач;
- счетчик, в виде автоинкрементного поля, который предназначен для ключевого поля, увеличивается на единицу после добавления новой записи и сохраняется в данное поле новой записи, что гарантирует разные значения для неодинаковых записей;
- логический, в виде «да или нет», «правда или ложь», «включен или выключен»;
- объект OLE, предназначен для хранения документов, картинок, звуков и другой информации, представляет собой частный случай BLOB, то есть полей (Binary Large Object), которые можно встретить в разных базах данных;
- гиперссылка, необходима для хранения ссылок на ресурсы в Интернете, характерна не для всех форматов баз данных, например, отсутствует в dBase и Paradox;
- подстановка.
Благодаря связи с обеспечением целостности таблиц осуществляется контроль удаления и модификации данных. С помощью монопольного доступа к базам данных в них производят фундаментальные изменения.
Разное
База данных Программа, предназначенная для создания баз данных и хранения в них записей. В программе имеется поиск, режим напоминания, импорт и экспорт данных. Также существует возможность установки пароля на базу данных (от посторонних).Windows | Русский язык: Есть | Shareware
Oracle Loger Программа предоставляет возможность просмотра, удаления и выгрузки в текстовый файл записей таблицы логов, имеющей определенную структуру, в базе данных Oracle, не прибегая при этом к написанию SQL-запросов.Windows | Русский язык: Есть | Бесплатно
SQL Server Dumper Программа позволяет делать дамп баз данных SQL Server в текстовые файлы. SQL Server Dumper будет полезна, когда необходимо сохранить данные не из всей базы целиком, а только из нескольких таблиц, или когда нужно импортировать данные из нескольких разных баз.Windows | Русский язык: Нет (англ. интерфейс) | Бесплатно
dbfHeaderEdit Программа dbfHeaderEdit предназначена для просмотра и изменения заголовков файлов формата DBF. Структура заголовка представлена в удобном для понимания и редактирования виде, что позволяет легко восстанавливать поврежденные таблицы.Windows | Русский язык: Возможно (многояз. интерфейс) | Бесплатно
dbForge Data Compare for SQL Server Инструмент для сравнения и синхронизации данных в SQL-базах. Хорошо продуманный интерфейс поможет вам быстро проанализировать различия в данных, а удобный мастер обеспечит синхронизацию результатов сравнения с дополнительными настройками. Windows | Русский язык: Есть | Shareware
КУЛИНАР В базе данных представлены кулинарные рецепты от очень простых, до очень сложных. В ознакомительной версии программы содержится 12100 рецептов блюд из любых продуктов.После оплаты Вы получаете по е-мейл ссылку на скачивания базы данных с содержанием более 50500 кулинарных рецептов …Windows | Русский язык: Есть | Shareware
Alpha Five Инструмент для создания прикладных и веб-приложений, работающих с базами данных. Alpha Five обладает встроенными редакторами HTML и CSS.Windows | Русский язык: Нет (англ. интерфейс) | Демо-версия
SQLyog Удобное средство для удаленного обслуживания баз данных MySQL.Windows | Русский язык: Нет (англ. интерфейс) | Shareware
InterBase/Firebird Development Studio Универсальный пакет программ, являющийся прекрасным инструментом для разработчика баз данных под управлением серверов InterBase или Firebird.Windows | Русский язык: Нет (англ. интерфейс) | Shareware
dbForge Studio for MySQL Профессиональный инструмент для разработчиков БД и пользователей MySQL. dbForge Studio for MySQL автоматизирует рутинные задачи по разработке и администрированию СУБД MySQL.Windows | Русский язык: Возможно (многояз. интерфейс) | Бесплатно
GS-Base Небольшая и очень удобная в работе база данных с функциями быстрого поиска и автозаполнения. Поддерживает импорт данных из популярных форматов (FoxPro, dBase) и из электронных таблиц (Excel). GS-Base позволяет хранить огромное количество записей в одной базе (до 2 млн).Windows | Русский язык: Нет (англ. интерфейс) | Shareware