Hashlib
Содержание:
- Свойства
- История
- Использование онлайн-ресурсов
- Методы
- Статистика базы данных с отбором по подсистемам (кол-во и открытие списков: документов, справочников, регистров) и анализ наличия основных реквизитов: универсальная обработка (два файла — обычный и управляемый режим)
- Криптоанализ[править | править код]
- Проблемы надежности MD5
- Проблемы надежности MD5
- Алгоритм MD5
- Примеры использования
- Как расшифровать MD5-хэш: общие принципы
- Dynamic в John the Ripper
- QuickHash
- StartManager 1.4 — Развитие альтернативного стартера Промо
- Как расшифровать MD5-хэш самому?
- Что такое хеши и как они используются
- Сравнение хеша в любой операционной системе
Свойства
|
Получает или задает размер блока, используемый в значении хэша.Gets or sets the block size to use in the hash value. (Унаследовано от HMAC) |
|
|
Получает значение, указывающее на возможность повторного использования текущего преобразования.Gets a value indicating whether the current transform can be reused. (Унаследовано от HashAlgorithm) |
|
|
Если переопределено в производном классе, возвращает значение, указывающее, возможно ли преобразование нескольких блоков.When overridden in a derived class, gets a value indicating whether multiple blocks can be transformed. (Унаследовано от HashAlgorithm) |
|
|
Получает значение вычисленного хэш-кода.Gets the value of the computed hash code. (Унаследовано от HashAlgorithm) |
|
|
Возвращает или задает имя используемого хэш-алгоритма.Gets or sets the name of the hash algorithm to use for hashing. (Унаследовано от HMAC) |
|
|
Возвращает размер вычисляемого значения HMAC в битах.Gets the size, in bits, of the computed HMAC. |
|
|
Получает размер вычисленного хэш-кода в битах.Gets the size, in bits, of the computed hash code. (Унаследовано от HashAlgorithm) |
|
|
При переопределении в производном классе получает размер входного блока.When overridden in a derived class, gets the input block size. (Унаследовано от HashAlgorithm) |
|
|
Возвращает или задает ключ, используемый при вычислении HMAC.Gets or sets the key to use in the HMAC calculation. |
|
|
Возвращает или задает ключ, используемый при вычислении HMAC.Gets or sets the key to use in the HMAC calculation. (Унаследовано от HMAC) |
|
|
При переопределении в производном классе получает размер выходного блока.When overridden in a derived class, gets the output block size. (Унаследовано от HashAlgorithm) |
История
В 1993 году Берт ден Бур (Bert den Boer) и Антон Босселарс (Antoon Bosselaers) показали, что в алгоритме возможны псевдоколлизии, когда разным инициализирующим векторам соответствуют одинаковые дайджесты для входного сообщения.
В 1996 году Ганс Доббертин (Hans Dobbertin) объявил о коллизии в алгоритме, и уже в то время было предложено использовать другие алгоритмы хеширования, такие как Whirlpool, SHA-1 или RIPEMD-160.
Из-за небольшого размера хеша в 128 бит можно рассматривать birthday-атаки. В марте 2004 года был запущен проект MD5CRK с целью обнаружения уязвимостей алгоритма, используя birthday-атаки. Проект MD5CRK закончился 17 августа 2004 года, когда Ван Сяоюнь (Wang Xiaoyun), Фэн Дэнго (Feng Dengguo), Лай Сюэцзя (Lai Xuejia) и Юй Хунбо (Yu Hongbo) обнаружили уязвимости в алгоритме.
1 марта 2005 года Арьен Ленстра, Ван Сяоюнь и Бенне де Вегер продемонстрировали построение двух документов X.509 с различными открытыми ключами и одинаковым хешем MD5.
18 марта 2006 года исследователь Властимил Клима (Vlastimil Klima) опубликовал алгоритм, который может найти коллизии за одну минуту на обычном компьютере, метод получил название «туннелирование».
В конце 2008 года US-CERT призвал разработчиков программного обеспечения, владельцев веб-сайтов и пользователей прекратить использовать MD5 в любых целях, так как исследования продемонстрировали ненадёжность этого алгоритма.
24 декабря 2010 года Тао Се (Tao Xie) и Фэн Дэнго (Feng Dengguo) впервые представили коллизию сообщений длиной в один блок (512 бит).
Ранее коллизии были найдены для сообщений длиной в два блока и более. Позднее Марк Стивенс (Marc Stevens) повторил успех, опубликовав блоки с одинаковым хешем MD5, а также алгоритм для получения таких коллизий.
Использование онлайн-ресурсов
Если уж назрела необходимость расшифровки, для начала можно воспользоваться услугами множества интернет-ресурсов, предлагающих свои услуги. В общих чертах принцип работы заключается в том, что пользователь вводит в специальной строке на сайте комбинацию, подлежащую расшифровке, после чего активирует процесс подбора.
Если кодирование начальной информации производилось при помощи средств языка PHP, в некоторых случаях онлайн-сервисы могут использовать комбинацию команд base_64 encode/base_64 decode. В любом случае методика подразумевает только подбор символов, цифр или литер в искомом сочетании путем сравнения с базами данных, в которых хранятся примеры кодированных результатов.
Методы
|
Освобождает все ресурсы, используемые классом HashAlgorithm.Releases all resources used by the HashAlgorithm class. (Унаследовано от HashAlgorithm) |
|
|
Вычисляет хэш-значение для заданного массива байтов.Computes the hash value for the specified byte array. (Унаследовано от HashAlgorithm) |
|
|
Вычисляет хэш-значение для заданной области заданного массива байтов.Computes the hash value for the specified region of the specified byte array. (Унаследовано от HashAlgorithm) |
|
|
Вычисляет хэш-значение для заданного объекта Stream.Computes the hash value for the specified Stream object. (Унаследовано от HashAlgorithm) |
|
|
Асинхронно вычисляет хэш-значение для заданного объекта Stream.Asynchronously computes the hash value for the specified Stream object. (Унаследовано от HashAlgorithm) |
|
|
Освобождает все ресурсы, используемые текущим экземпляром класса HashAlgorithm.Releases all resources used by the current instance of the HashAlgorithm class. (Унаследовано от HashAlgorithm) |
|
|
Освобождает неуправляемые ресурсы, используемые объектом HMACMD5, а при необходимости освобождает также управляемые ресурсы.Releases the unmanaged resources used by the HMACMD5 and optionally releases the managed resources. |
|
|
Освобождает неуправляемые ресурсы, используемые объектом HMAC, и, если допускается изменение ключа, опционально освобождает управляемые ресурсы.Releases the unmanaged resources used by the HMAC class when a key change is legitimate and optionally releases the managed resources. (Унаследовано от HMAC) |
|
|
Определяет, равен ли указанный объект текущему объекту.Determines whether the specified object is equal to the current object. |
|
|
Служит хэш-функцией по умолчанию.Serves as the default hash function. (Унаследовано от Object) |
|
|
Возвращает объект Type для текущего экземпляра.Gets the Type of the current instance. (Унаследовано от Object) |
|
|
Передает данные из объекта в HMAC-алгоритм для вычисления HMAC.Routes data written to the object into the HMAC algorithm for computing the HMAC. |
|
|
Если переопределено в производном классе, передает данные, записанные в объект, в HMAC-алгоритм для вычисления значения HMAC.When overridden in a derived class, routes data written to the object into the HMAC algorithm for computing the HMAC value. (Унаследовано от HMAC) |
|
|
Передает данные из объекта в HMAC-алгоритм для вычисления HMAC.Routes data written to the object into the HMAC algorithm for computing the HMAC. |
|
|
Передает данные из объекта в HMAC-алгоритм для вычисления HMAC.Routes data written to the object into the HMAC algorithm for computing the HMAC. (Унаследовано от HMAC) |
|
|
Завершает вычисление HMAC после обработки последних данных алгоритмом.Finalizes the HMAC computation after the last data is processed by the algorithm. |
|
|
Если переопределено в производном классе, завершает вычисление HMAC после обработки последних данных алгоритмом.When overridden in a derived class, finalizes the HMAC computation after the last data is processed by the algorithm. (Унаследовано от HMAC) |
|
|
Сбрасывает хэш-алгоритм в исходное состояние.Resets the hash algorithm to its initial state. |
|
|
Инициализирует новый экземпляр реализации по умолчанию класса HMAC.Initializes an instance of the default implementation of HMAC. (Унаследовано от HMAC) |
|
|
Создает неполную копию текущего объекта Object.Creates a shallow copy of the current Object. (Унаследовано от Object) |
|
|
Возвращает строку, представляющую текущий объект.Returns a string that represents the current object. (Унаследовано от Object) |
|
|
Вычисляет хэш-значение для заданной области входного массива байтов и копирует указанную область входного массива байтов в заданную область выходного массива байтов.Computes the hash value for the specified region of the input byte array and copies the specified region of the input byte array to the specified region of the output byte array. (Унаследовано от HashAlgorithm) |
|
|
Вычисляет хэш-значение для заданной области заданного массива байтов.Computes the hash value for the specified region of the specified byte array. (Унаследовано от HashAlgorithm) |
|
|
Пытается вычислить хэш-значение для заданного массива байтов.Attempts to compute the hash value for the specified byte array. (Унаследовано от HashAlgorithm) |
|
|
Пытается завершить вычисление HMAC после обработки последних данных алгоритмом HMAC.Attempts to finalize the HMAC computation after the last data is processed by the HMAC algorithm. |
|
|
Пытается завершить вычисление HMAC после обработки последних данных алгоритмом HMAC.Attempts to finalize the HMAC computation after the last data is processed by the HMAC algorithm. (Унаследовано от HMAC) |
Статистика базы данных с отбором по подсистемам (кол-во и открытие списков: документов, справочников, регистров) и анализ наличия основных реквизитов: универсальная обработка (два файла — обычный и управляемый режим)
Универсальная обработка для статистики базы данных (документы, справочники, регистры, отчеты) с отбором по подсистемам и с анализом наличия основных реквизитов (организации, контрагенты, договора, номенклатура, сотрудники, физлица, валюта).
Возможность просмотра списка документов или справочников или регистров при активизации в колонке «Документы, справочники, регистры, отчеты» в текущей строке.
Полезная обработка для консультации пользователей, где искать метаданные в каком интерфейсе, т.к. подсистема указывает в каком интерфейсе находятся метаданные (документы, справочники, регистры, отчеты).
1 стартмани
Криптоанализ[править | править код]
На данный момент существуют несколько видов «взлома» хешей MD5 — подбора сообщения с заданным хешем:
- Перебор по словарю
- RainbowCrack
RainbowCrack — новый вариант взлома хеша. Он основан на генерировании большого количества хешей из набора символов, и потом по этой базе можно вести поиск заданного хеша. Хотя генерация хешей занимает недели, зато последующий взлом производится за считанные минуты. Rainbow-таблицы можно найти, а можно сгенерировать самому.
Коллизия хеш-функции — это получение одинакового значения функции для разных сообщений и идентичного начального буфера. Природа таких коллизий кроется в размере хеша. При своей длине в 128 бит, он имеет различных дайджестов и для сообщений большей длины чем 128, коллизии просто неизбежны. Существуют еще так называемые псевдоколлизии, когда для разного значения начального буфера получаются одинаковые значения хеша, при этом сообщения могут совпадать или отличаться. Вскоре после создания алгоритма такие коллизии были обнаружены.
A = 0x12AC2375 В = 0x3B341042 C = 0x5F62B97C D = 0x4BA763ED
и задать входное сообщение
| AA1DDABE | D97ABFF5 | BBF0E1C1 | 32774244 |
| 1006363E | 7218209D | E01C136D | 9DA64D0E |
| 98A1FB19 | 1FAE44B0 | 236BB992 | 6B7A779B |
| 1326ED65 | D93E0972 | D458C868 | 6B72746A |
то, добавляя число к определенному 32-разрядному слову в блочном буфере, можно получить второе сообщение с таким же хешем. Ханс Доббертин представил такую формулу:
Тогда MD5(IV, L1) = MD5(IV, L2) = BF90E670752AF92B9CE4E3E1B12CF8DE.
| d131dd02c5e6eec4693d9a0698aff95c | 2fcab58712467eab4004583eb8fb7f89 |
| 55ad340609f4b30283e488832571415a | 085125e8f7cdc99fd91dbdf280373c5b |
| d8823e3156348f5bae6dacd436c919c6 | dd53e2b487da03fd02396306d248cda0 |
| e99f33420f577ee8ce54b67080a80d1e | c69821bcb6a8839396f9652b6ff72a70 |
и
| d131dd02c5e6eec4693d9a0698aff95c | 2fcab50712467eab4004583eb8fb7f89 |
| 55ad340609f4b30283e4888325f1415a | 085125e8f7cdc99fd91dbd7280373c5b |
| d8823e3156348f5bae6dacd436c919c6 | dd53e23487da03fd02396306d248cda0 |
| e99f33420f577ee8ce54b67080280d1e | c69821bcb6a8839396f965ab6ff72a70 |
Каждый их этих блоков дает MD5 хеш равный 79054025255fb1a26e4bc422aef54eb4.
Метод Сяоюнь Вана и Хунбо Юправить | править код
позволяет для заданного инициализирующего вектора найти две пары и , такие что
Важно отметить, что этот метод работает для любого инициализирующего вектора, а не только для вектора используемого по стандарту.. Применение этой атаки к MD4 позволяет найти коллизию меньше чем за секунду
Она также применима к другим хеш-функциям, таким как RIPEMD и HAVAL.
Применение этой атаки к MD4 позволяет найти коллизию меньше чем за секунду. Она также применима к другим хеш-функциям, таким как RIPEMD и HAVAL.
Проблемы надежности MD5
Казалось бы, такая характеристика MD5 должна обеспечивать 100% гарантии неуязвимости и сохранения данных. Но даже этого оказалось мало. В ходе проводимых исследований учеными был выявлен целый ряд прорех и уязвимостей в этом уже распространенном на тот момент алгоритме. Основной причиной слабой защищенности MD5 является относительно легкое нахождение коллизий при шифровании.
Под коллизией понимают возможность получения одинакового результата вычислений хеш-функции при разных входных значениях.
Проще говоря, чем больше вероятность нахождения коллизий, тем надежность используемого алгоритма ниже. Вероятность нахождения коллизий при шифровании более надежными хеш-функциями практически сводится к 0.
То есть большая вероятность расшифровки паролей MD5 является основной причиной отказа от использования этого алгоритма. Многие криптологи (специалисты по шифрованию данных) связывают низкую надежность MD5 с малой длиной получаемого хеш-кода.
Область применения алгоритма хеширования:
- Проверка целостности файлов, полученных через интернет – многие инсталляционные пакеты программ снабжены хеш-кодом. Во время активации приложения его значение сравнивается со значением, расположенным в базе данных разработчика;
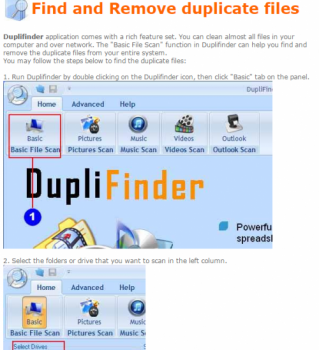
- Поиск в файловой системе продублированных файлов – каждый из файлов снабжен своим хеш-кодом. Специальное приложение сканирует файловую систему компьютера, сравнивая между собой хеши всех элементов. При обнаружении совпадения утилита оповещает об этом пользователя или удаляет дубликат. Одной из подобных программ является Duplifinder:
Для хеширования паролей – в семействе операционных систем UNIX каждый пользователь системы имеет свой уникальный пароль, для защиты которого используется хеширование на основе MD5. Некоторые системы на основе Linux также пользуются этим методом шифрования паролей.
Проблемы надежности MD5
Казалось бы, такая характеристика MD5 должна обеспечивать 100% гарантии неуязвимости и сохранения данных. Но даже этого оказалось мало. В ходе проводимых исследований учеными был выявлен целый ряд прорех и уязвимостей в этом уже распространенном на тот момент алгоритме. Основной причиной слабой защищенности MD5 значится относительно легкое нахождение коллизий при шифровании.
Под коллизией понимают возможность получения одинакового результата вычислений хеш-функции при разных входных значениях.
Проще говоря, чем больше вероятность нахождения коллизий, тем надежность используемого алгоритма ниже. Вероятность нахождения коллизий при шифровании более надежными хеш-функциями практически сводится к 0.
То есть большая вероятность расшифровки паролей MD5 значится основной причиной отказа от использования этого алгоритма. Многие криптологи (специалисты по шифрованию данных) связывают низкую надежность MD5 с малой длиной получаемого хеш-кода.
Область применения алгоритма хеширования:
- Проверка целостности файлов, полученных через интернет – многие инсталляционные пакеты прог снабжены хеш-кодом. Во время активации приложения его значение сравнивается со значением, расположенным в базе данных разработчика;
- Поиск в файловой системе продублированных файлов – каждый из файлов снабжен своим хеш-кодом. Специальное приложение сканирует файловую систему компа, сравнивая между собой хеши всех элементов. При обнаружении совпадения утилита оповещает об этом пользователя или удаляет дубликат. Одной из подобных прог значится Duplifinder:
- Для хеширования паролей – в семействе операционных систем UNIX каждый юзер системы имеет свой замечательный пароль, для защиты которого используется хеширование на основе MD5. Некоторые системы на основе Линукс также пользуются этим методом шифрования паролей.
Алгоритм MD5
На вход алгоритма поступает входной поток данных, хеш которого необходимо найти. Длина сообщения может быть любой (в том числе нулевой). Запишем длину сообщения в L. Это число целое и неотрицательное. Кратность каким-либо числам необязательна. После поступления данных идёт процесс подготовки потока к вычислениям.
Ниже приведены 5 шагов алгоритма:
Шаг 1. Выравнивание потока
Сначала дописывают единичный бит в конец потока(байт 0x80), затем необходимое число нулевых бит.
Входные данные выравниваются так, чтобы их новый размер L’ был сравним с 448 по модулю 512 (L’ = 512 × N + 448).
Выравнивание происходит, даже если длина уже сравнима с 448.
Шаг 2. Добавление длины сообщения
В оставшиеся 64 бита дописывают 64-битное представление длины данных (количество бит в сообщении) до выравнивания. Сначала записывают младшие 4 байта. Если длина превосходит 264−1{\displaystyle 2^{64}-1}, то дописывают только младшие биты. После этого длина потока станет кратной 512. Вычисления будут основываться на представлении этого потока данных в виде массива слов по 512 бит.
Шаг 3. Инициализация буфера
Для вычислений инициализируются 4 переменных размером по 32 бита и задаются начальные значения шестнадцатеричными числами (шестнадцатеричное представление, сначала младший байт):
А = 01 23 45 67; В = 89 AB CD EF; С = FE DC BA 98; D = 76 54 32 10.
В этих переменных будут храниться результаты промежуточных вычислений. Начальное состояние ABCD называется инициализирующим вектором.
Определим ещё функции и константы, которые нам понадобятся для вычислений.
Потребуются 4 функции для четырёх раундов. Введём функции от трёх параметров — слов, результатом также будет слово.
- 1 раунд FunF(X,Y,Z)=(X∧Y)∨(¬X∧Z){\displaystyle Fun F(X,Y,Z) = (X\wedge{Y}) \vee (\neg{X} \wedge{Z})}.
- 2 раунд FunG(X,Y,Z)=(X∧Z)∨(¬Z∧Y){\displaystyle Fun G(X,Y,Z) = (X\wedge{Z}) \vee (\neg{Z} \wedge{Y})}.
- 3 раунд FunH(X,Y,Z)=X⊕Y⊕Z{\displaystyle Fun H(X,Y,Z) = X \oplus Y \oplus Z}.
- 4 раунд FunI(X,Y,Z)=Y⊕(¬Z∨X){\displaystyle Fun I(X,Y,Z) = Y \oplus (\neg{Z} \vee X)}.
- Определим таблицу констант T — 64-элементная таблица данных, построенная следующим образом: Ti=int(4294967296∗|sin(i)|){\displaystyle T=int(4294967296*|sin(i)|)}, где 4294967296=232{\displaystyle 4294967296 = 2^{32}}. Иными словами, в таблице представлены по 32 бита после десятичной запятой от значений функции sin.
- Выровненные данные разбиваются на блоки (слова) по 32 бита, и каждый блок проходит 4 раунда из 16 операторов. Все операторы однотипны и имеют вид: , определяемый как a=b+((a+Fun(b,c,d)+Xk+Ti)<<<s){\displaystyle a = b + ((a + Fun(b, c, d) + X + T) <<< s)}, где X — блок данных. X = M , где k — номер 32-битного слова из n-го 512-битного блока сообщения, и s — циклический сдвиг влево на s бит полученого 32-битного аргумента.
Шаг 4. Вычисление в цикле
Заносим в блок данных элемент n из массива. Сохраняются значения A, B, C и D, оставшиеся после операций над предыдущими блоками (или их начальные значения, если блок первый).
- AA = A
- BB = B
- CC = C
- DD = D
Раунд 1
/* a = b + ((a + F(b,c,d) + X + T) <<< s). */
Раунд 2
/* a = b + ((a + G(b,c,d) + X + T) <<< s). */
Раунд 3
/* a = b + ((a + H(b,c,d) + X + T) <<< s). */
Раунд 4
/* a = b + ((a + I(b,c,d) + X + T) <<< s). */
Суммируем с результатом предыдущего цикла:
A = AA + A B = BB + B C = CC + C D = DD + D
После окончания цикла необходимо проверить, есть ли ещё блоки для вычислений. Если да, то изменяем номер элемента массива (n++) и переходим в начало цикла.
Шаг 5. Результат вычислений
Результат вычислений находится в буфере ABCD, это и есть хеш. Если выводить побайтово начиная с младшего байта A и закончив старшим байтом D, то мы получим MD5 хеш.
Сравнение MD5 и MD4
Алгоритм MD5 происходит от MD4. В новый алгоритм добавили ещё один раунд, теперь их стало 4 вместо 3 в MD4. Добавили новую константу для того, чтобы свести к минимуму влияние входного сообщения, в каждом раунде на каждом шаге и каждый раз константа разная, она суммируется с результатом F и блоком данных. Изменилась функция G = XZ v (Y not(Z)) вместо (XY v XZ v YZ). Результат каждого шага складывается с результатом предыдущего шага, из-за этого происходит более быстрое изменение результата. Изменился порядок работы с входными словами в раундах 2 и 3.
Различия в скорости работы представлены в таблице:
| MD5 | MD4 | |||
|---|---|---|---|---|
| RFC | 2,614 сек | 37 359 Кб/с | 2,574 сек | 37 940 Кб/с |
| OpenSSL | 1,152 сек | 84 771 Кб/с | 0,891 сек | 109 603 Кб/с |
Примеры использования
Ранее считалось, что MD5 позволяет получать относительно надёжный идентификатор для блока данных. На данный момент данная хеш-функция не рекомендуется к использованию, так как существуют способы нахождения коллизий с приемлемой вычислительной сложностью.
Свойство уникальности хеша широко применяется в разных областях. Стоит отметить, что приведенные примеры относятся и к другим .
С помощью MD5 проверяли целостность и подлинность скачанных файлов — так, некоторые программы поставляются вместе со значением контрольной суммы. Например, пакеты для инсталляции свободного ПО.
MD5 использовался для хеширования паролей. В системе UNIX каждый пользователь имеет свой пароль и его знает только пользователь. Для защиты паролей используется хеширование. Предполагалось, что получить настоящий пароль можно только полным перебором. При появлении UNIX единственным способом хеширования был DES (Data Encryption Standard), но им могли пользоваться только жители США, потому что исходные коды DES нельзя было вывозить из страны. Во FreeBSD решили эту проблему. Пользователи США могли использовать библиотеку DES, а остальные пользователи имеют метод, разрешённый для экспорта. Поэтому в FreeBSD стали использовать MD5 по умолчанию.. Некоторые Linux-системы также используют MD5 для хранения паролей.
Многие системы используют базы данных для аутентификации пользователей и существует несколько способов хранения паролей:
- Пароли хранятся как есть. При взломе такой базы все пароли станут известны.
- Хранятся только хеши паролей. Найти пароли можно используя заранее подготовленные таблицы хешей. Такие таблицы составляются из хешей простых или популярных паролей.
- К каждому паролю добавляется несколько случайных символов (их называют «соль») и результат хешируется. Полученный хеш вместе с «солью» сохраняются в открытом виде. Найти пароль с помощью таблиц таким методом не получится.
Существует несколько надстроек над MD5.
- MD5 (HMAC) — Keyed-Hashing for Message Authentication (хеширование с ключом для аутентификации сообщения) — алгоритм позволяет хешировать входное сообщение L с некоторым ключом K, такое хеширование позволяет аутентифицировать подпись.
- MD5 (Base64) — здесь полученный MD5-хеш кодируется алгоритмом Base64.
- MD5 (Unix) — алгоритм вызывает тысячу раз стандартный MD5, для усложнения процесса. Также известен как MD5crypt.
Как расшифровать MD5-хэш: общие принципы
В лучшем случае речь может идти только о подборе искомого содержимого тремя основными методами:
- использование словаря;
- применение «радужных таблиц»;
- метод брута.

Начальная технология MDA5-хэширования была разработана в Массачусетском технологическом институте под руководством профессора Рональда Л. Ривеста. С тех пор она широко применяется как один из методов криптографии для хранения паролей и онлайн-ключей, создания электронных подписей, проверки целостности файловых систем, создания веб-идентификаторов, поиска дубликатов файлов и т.д. И, как считается, расшифровать MD5-хэш прямыми алгоритмическими методами крайне трудно (хотя и возможно), ведь даже изменение одного из символов в шестнадцатричном представлении влечет за собой автоматическое изменение всех остальных. Таким образом, остается только метод, обычно называемый брутом (вмешательство с применением грубой силы). Тем не менее простейшие комбинации привести в исходный вид можно.
Dynamic в John the Ripper
Динамический «самостоятельно описывающий» формат (a.k.a. Динамический компилятор выражений (dynamic expression compiler)). Это режим в котором пользователь без использования программирования описывает формулу, по которой хешируются пароли.
Допустим, мы добыли хеш пароля:
838c9416a8d094b7e660a0f3b12e3e543c71f7f4
И его соль:
mial
С помощью обратной инженерии выяснено, что хеш высчитывается по следующей формуле:
sha1(md5(sha512($p.$s).$p).$s)
Нам нужно записать хеш в файл в следующем формате:
ХЕШ$СОЛЬ
То есть хеш и соль разделяются знаком доллара.
Создаём файл hash.txt и записываем:
838c9416a8d094b7e660a0f3b12e3e543c71f7f4$mial
Создадим крошечный словарик, назовём его wordlist.txt и запишем в него:
123 hackware 123567890 123456 111111111111111111
Команда для запуска взлома по словарю:
john -form=dynamic='sha1(md5(sha512($p.$s).$p).$s)' --wordlist=wordlist.txt hash.txt
Или по маске:
john -form=dynamic='sha1(md5(sha512($p.$s).$p).$s)' --mask='?l?l?l?l?l?l?l?l' hash.txt
Пароль успешно взломан, это «hackware»:
В данном примере мы использовали нашу собственную формулу, по которой вычислялся хеш, но в John the Ripper много встроенных динамичных форматов. Более того, вы можете записать ваш динамический формат в конфигурационном файле и использовать его по присвоенному имени, вместо того, чтобы каждый раз вводить формулу. Сначала мы познакомимся со встроенными форматами, а затем вернёмся к синтаксису динамических форматов, которые вы можете составить сами.
Хотя нет, чтобы понимать обозначения встроенных форматов, нужно знать синтаксис — поэтому начнём всё-таки с синтаксиса написания пользовательских форматов dynamic.
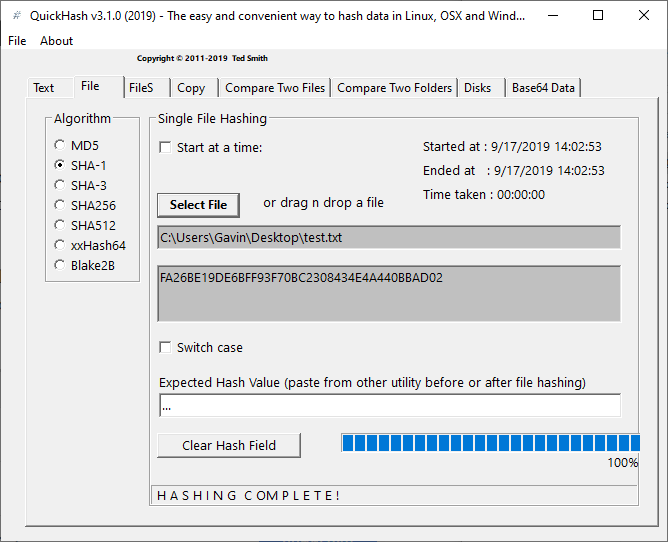
QuickHash
QuickHash — это генератор хэшей с открытым исходным кодом для Windows, macOS и Linux. Это также одна из наиболее полнофункциональных систем создания хэшей и проверки их правильности в этом списке.
Хотя количество хэшей, которые вы можете использовать, небольшое, просто MD5, SHA1, SHA256, SHA512, и xxHash64, но Quick Hash имеет массу дополнительных функций.
QuickHash может хэшировать целую папку, сравнивать два отдельных файла, сравнивать целые каталоги или диск целиком. Конечно, последнее занимает значительное количество времени в связи с размерами, но возможность его использования очень приятно видеть.
Скачать: QuickHash для Windows | macOS | Linux (Debian)
StartManager 1.4 — Развитие альтернативного стартера Промо
Очередная редакция альтернативного стартера, являющегося продолжением StartManager 1.3. Спасибо всем, кто присылал свои замечания и пожелания, и тем, кто перечислял финансы на поддержку проекта. С учетом накопленного опыта, стартер был достаточно сильно переработан в плане архитектуры. В основном сделан упор на масштабируемость, для способности программы быстро адаптироваться к расширению предъявляемых требований (т.к. довольно часто просят добавить ту или иную хотелку). Было пересмотрено внешнее оформление, переработан существующий и добавлен новый функционал. В общем можно сказать, что стартер эволюционировал, по сравнению с предыдущей редакцией. Однако пока не всё реализовано, что планировалось, поэтому еще есть куда развиваться в плане функциональности.
1 стартмани
Как расшифровать MD5-хэш самому?
Некоторые пользователи пытаются расшифровать хэш-код самостоятельно. Но, как оказывается, сделать это достаточно проблематично. Для упрощения такой процедуры лучше использовать узконаправленные утилиты, среди которых явно выделяются следующие программы:
- PasswordPro.
- John the Ripper.
- Cain & Abel.
- «Штирлиц» и др.
Первые две программы предназначены для вычисления простейших комбинаций путем подстановки элементарных сочетаний вроде 1212121.
Третья вроде бы и может расшифровать MD5-хэш, но делает это слишком медленно. Однако ее преимущество состоит в том, что она имеет в комплекте генератор таблиц, хотя непосвященный пользователь с этим вряд ли разберется.
«Штирлиц» — приложение весьма интересное, но оно использует слишком ограниченное число алгоритмов вычислений, среди которых наиболее значимыми являются такие как BtoA, uuencode, base64, xxencode и binhex.
Если уж та то пошло, нужно использовать утилиту брута BarsWF, которая является наиболее быстрой из всех известных и в большинстве случаев может расшифровать MD5-хэш (пароль, если он есть, тоже может быть приведен в искомый вид), оперируя миллиардами вычислений хэша в секунду. Однако даже с применением всех этих программных средств следует учитывать еще и тот момент, что, кроме основного алгоритма, MDA5-кодирование может производиться одновременно и с применением MD4 или IM.
Но даже несмотря на все это, в хэшировании можно найти и множество прорех. Многие специалисты считают, что длина кода даже при условии 128-битной основы слишком мала, а потому с развитием программных средств и повышением вычислительных возможностей современных процессорных систем процесс дешифрования становится все менее трудоемким, из-за чего дальнейшее развитие и применение таких средств уже выглядит совершенно нецелесообразным.
Что такое хеши и как они используются
Хеш-сумма (хеш, хеш-код) — результат обработки неких данных хеш-функцией (хеширования).
Хеширование, реже хэширование (англ. hashing) — преобразование массива входных данных произвольной длины в (выходную) битовую строку фиксированной длины, выполняемое определённым алгоритмом. Функция, реализующая алгоритм и выполняющая преобразование, называется «хеш-функцией» или «функцией свёртки». Исходные данные называются входным массивом, «ключом» или «сообщением». Результат преобразования (выходные данные) называется «хешем», «хеш-кодом», «хеш-суммой», «сводкой сообщения».
Это свойство хеш-функций позволяет применять их в следующих случаях:
- при построении ассоциативных массивов;
- при поиске дубликатов в сериях наборов данных;
- при построении уникальных идентификаторов для наборов данных;
- при вычислении контрольных сумм от данных (сигнала) для последующего обнаружения в них ошибок (возникших случайно или внесённых намеренно), возникающих при хранении и/или передаче данных;
- при сохранении паролей в системах защиты в виде хеш-кода (для восстановления пароля по хеш-коду требуется функция, являющаяся обратной по отношению к использованной хеш-функции);
- при выработке электронной подписи (на практике часто подписывается не само сообщение, а его «хеш-образ»);
- и др.
Одним из применений хешов является хранение паролей. Идея в следующем: когда вы придумываете пароль (для веб-сайта или операционной системы) сохраняется не сам пароль, а его хеш (результат обработки пароля хеш-функцией). Этим достигается то, что если система хранения паролей будет скомпрометирована (будет взломан веб-сайт и злоумышленник получит доступ к базе данных паролей), то он не сможет узнать пароли пользователей, поскольку они сохранены в виде хешей. Т.е. даже взломав базу данных паролей он не сможет зайти на сайт под учётными данными пользователей. Когда нужно проверить пароль пользователя, то для введённого значения также рассчитывается хеш и система сравнивает два хеша, а не сами пароли.
По этой причине пентестер может столкнуться с необходимостью работы с хешами. Одной из типичных задач является взлом хеша для получения пароля (ещё говорят «пароля в виде простого текста» — поскольку пароль в виде хеша у нас и так уже есть). Фактически, взлом заключается в подборе такой строки (пароля), которая будет при хешировании давать одинаковое значение со взламываемым хешем.
Для взлома хешей используется, в частности, Hashcat. Независимо от выбранного инструмента, необходимо знать, хеш какого типа перед нами.
Сравнение хеша в любой операционной системе
Имея это в виду, давайте посмотрим, как проверить хеш файла, который вы загрузили, и сравнить его с тем, который должен быть. Вот методы для Windows, macOS и Linux. Хеши всегда будут идентичны, если вы используете одну и ту же функцию хеширования в одном файле. Не имеет значения, какую операционную систему Вы используете.
Хеш файла в Windows
Этот процесс возможен без какого-либо стороннего программного обеспечения на Windows, благодаря PowerShell.
Чтобы начать работу, откройте окно PowerShell, запустив ярлык Windows PowerShell из меню Пуск.
Выполните следующую команду, заменив «C:\path\to\file.iso» путём к любому файлу, для которого вы хотите просмотреть хеш:
Get-FileHash C:\path\to\file.iso
Для создания хеша файла потребуется некоторое время, в зависимости от размера файла, используемого алгоритма и скорости диска, на котором находится файл.
По умолчанию команда покажет хеш SHA-256 для файла. Однако, можно указать алгоритм хеширования, который необходимо использовать, если вам нужен хэш MD5, SHA-1 или другой тип.
Выполните одну из следующих команд, чтобы задать другой алгоритм хэширования:
Get-FileHash C:\path\to\file.iso -Algorithm MD5
Get-FileHash C:\path\to\file.iso -Algorithm SHA1
Get-FileHash C:\path\to\file.iso -Algorithm SHA256
Get-FileHash C:\path\to\file.iso -Algorithm SHA384
Get-FileHash C:\path\to\file.iso -Algorithm SHA512
Get-FileHash C:\path\to\file.iso -Algorithm MACTripleDES
Get-FileHash C:\path\to\file.iso -Algorithm RIPEMD160
Сравните результат хеш-функций с ожидаемым результатом. Если это то же значение, файл не был поврежден, подделан или иным образом изменен от исходного.
Хеш файла на macOS
macOS содержит команды для просмотра различных типов хэшей. Для доступа к ним запустите окно терминала. Вы найдете его в Finder → Приложения → Утилиты → Терминал.
Команда md5 показывает MD5-хеш файла:
md5 /path/to/file
Команда shasum показывает хеша SHA-1 по умолчанию. Это означает, что следующие команды идентичны:
shasum /path/to/file
shasum -a 1 /path/to/file
Чтобы отобразить хеш файла SHA-256, выполните следующую команду:
shasum -a 256 /path/to/file
Хеш файла в Linux
В Linux обратитесь к терминалу и выполните одну из следующих команд для просмотра хеша файла, в зависимости от типа хеша, который вы хотите посмотреть:
md5sum /path/to/file
sha1sum /path/to/file
sha256sum /path/to/file







