Как составить семантическое ядро без помощи специалиста
Содержание:
- Что такое семантическое ядро
- Запросы по частотности
- Зачем вебмастеру-оптимизатору нужны программы Key Collector и СловоЁБ
- Как создать семантическое ядро?
- Проработка вглубь
- Базы слов
- Как группировать запросы
- Мутаген
- Получение шлейфа
- Букварикс
- Сбор конкурентов
- Что такое семантическое ядро простыми словами
- Кластеризация семантического ядра
- Как работать в программе
Что такое семантическое ядро
Это список ключевых слов или фраз, инициирующих показ объявления пользователю, который интересуется вашими товарами или услугами. Борьба за клиента начинается именно на уровне семантики: от того, насколько хорошо вы понимаете потенциального клиента, умеете спрогнозировать его поисковые запросы и подобрать те, по которым покажется реклама, — зависит успех и прибыль.
Все способы составления семантического ядра можно условно разделить на две группы.
Первая группа основана на предположении о том, какие запросы могут вводить пользователи. Мы строим догадки и гипотезы, но не прибегаем к дополнительному инструментарию, можем упустить много нужных фраз или придумать лишние — запросы с нулевой частотностью, по которым не будет трафика.
Вторая группа — это способы, основанные на фактических данных и использовании инструментов, позволяющих увидеть реальные запросы пользователей. Они помогают правильно оценить конкурентов, тщательно проработать семантику и составить полное семантическое ядро. В итоге мы сможем показывать рекламные предложения, релевантные запросам пользователей — когда пользователи ищут наш продукт или услугу.
Комбинируя способы из этих двух групп, можно составить правильное и грамотное семантическое ядро, которое подойдет бизнесу и повысит результативность рекламы.
Сбор семантики состоит из нескольких этапов. Чтобы понять общий принцип, давайте подберем ключевые слова для клиента, специализирующегося на доставке цветов в Москве.
Запросы по частотности
-
Высокочастотные (ВЧ)
Наиболее популярные тематические слова. Они имеют большую конкуренцию, поэтому долго выводятся в ТОП. Могут состоять из одного или двух слов. Показатель частотности от 1500. -
Среднечастотные (СЧ)
Имеют средний показатель частотности между ВЧ и НЧ — до 1500 показов в месяц. Чаще всего состоят из нескольких слов. -
Низкочастотные (НЧ)
Узкое направление с точным отражением потребности пользователей. Содержат невысокую конкуренцию, что позволяет их быстро вывести в ТОП. Частотность — меньше 150 показов в месяц.
Используя для продвижения сайта только СЧ и ВЧ запросы, не забывайте, что на их вывод в ТОП-10 уйдет больше времени и усилий. Поэтому лучше использовать все группы запросов.
Зачем вебмастеру-оптимизатору нужны программы Key Collector и СловоЁБ
Собственно, все рассказать, даже используя скриншоты и видео урок, найденный в на Yoou Tube (который я поместил в конце статьи), очень сложно. Каждому, кто решит ею воспользоваться. придется потратить N-ный промежуток времени, что бы ее хорошенько изучить. Полагаю — не очень много.
Поэтому главной задачей мануала — сжатое объяснение принципов и назначения блоков программы. Суть же этих программ — помощь оптимизатору в нахождении ключевых слов (фраз), по выбранному запросу, которые выдает Яндекс Вордстат, среди которых нужно выбрать наиболее подходящие для создания сообщений (страниц) на своих сайтах. В этом деле помощником является и сам Яндекс Вордстат, но в его функциях нет некоторых существенных положений и данных, которые можно узнать и использовать в программах, подобной этой утилите. Не говоря уже о Key Collector. Все данные, которые дают такого рода программы, можно получить на различных и специальных сервисах и в сумме с Яндекс Вордстатом и Адводсом Гугла их можно раздобыть, но в разрозненном варианте. В программах — всё (или почти всё), что интересует оптимизатора, предоставляется компактным сервисом.
Кроме того, прежде чем приступить к изучению материала этого поста, настоятельно рекомендую прочесть мою раннюю статью по теме , где рекомендую обратить внимание на разъяснения касательно выбора и использования операторов для подбора ключевых слов, особливо » » и «!». И вообще — что бы быть в теме того, о чем здесь будет говориться
Как создать семантическое ядро?
Формирование семантического ядра — это комплексный процесс, включающий анализ тематики и структуры сайта, работу со специальными сервисами и программами, редактирование базы ключей вручную. Есть два основных принципа создания СЯ:
- подбор максимального количества ключей и дальнейшей очистки;
- подбор точных ключевых фраз с самого начала с последующим расширением базы.
Мы обратились к нескольким SEO-экспертам, чтобы узнать, какой подход они предпочитают.
Тарас Гуща, СЕО в SEO.UA, склоняется к первому методу:
Лучше много ключей и потом чистить. Потому как иногда можно упустить весьма стоящие ключевые фразы. Нам как профессионалам продвижения сайтов надо давать клиентам максимальный результат. Поэтому каждая ключевая фраза, которая может конвертировать потенциальную аудиторию в клиента, очень важна.
А вот Катерина Золотарева, Founder & CEO в Site24, считает, что в зависимости от выбранной стратегии можно использовать оба подхода:
Если проект небольшой или в сложной для формирования семантики нише, например, технологические услуги, то однозначно надо собирать все и даже больше, потом вычеркивать нерелевантное, а околотематические ключи отправлять в блог.
Также имеет смысл глубоко заниматься семантикой, если проект уже имеет позиции, трафик, а стандартные базовые ключи и так уже включены в метатеги и текст. Тогда глубокая проработка семантики поможет вам значительно улучшить видимость и трафик.
Этапы создания семантического ядра
Создание СЯ можно разделить на три этапа.
- Выбор подхода для создания СЯ.
Есть несколько стратегий того, как можно собрать семантического ядро. Их применяют в зависимости от того, имеет ли ресурс структуру или только находится в процессе разработки, какой у него уровень оптимизации, какие позиции по ключевым словам он занимает и т.д..
- Сбор запросов с помощью специальных инструментов.
Сервисы подбора ключевых слов дают возможность охватить максимальное число запросов и поисковых подсказок. Для лучшего результата стоит задействовать инструменты для анализа семантики конкурентов.
- Формирование СЯ из общей базы запросов.
Этапы преобразования облака тематических запросов в семантическое ядро включают два основных этапа:
- очистка базы ключей от ненужных запросов;
- кластеризация путем деления семантики на группы.
Также в процессе анализа ключей можно отделить минус-слова. Кластеризация базы запросов предшествует распределению ключевых фраз по URL. В следующих разделах мы рассмотрим все этапы разработки семантического ядра подробно.
Подходы при создании семантического ядра
Рассмотрим стандартные схемы для создания баз ключей. В зависимости от конкретного случая можно использовать один из подходов, приведенных ниже, или же индивидуальную стратегию.
ПЕРВЫЙ ПОДХОД — ФОРМИРОВАНИЕ СТРУКТУРЫ НОВОГО САЙТА НА ОСНОВЕ СЯ.
- Исследование рыночной ниши/торговой линейки/брифа клиента.
- Определение списка основных запросов (seed keywords).
- Сбор максимального количества фраз для каждого основного ключа.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Очистка полученного списка запросов от дублей и мусорных фраз (при наличии списка минус-слов).
- Автоматическая кластеризация через SE Ranking.
- Окончательная очистка запросов.
- Создание структуры сайта по разделам, категориям, страницам на основе кластеризации.
ВТОРОЙ ПОДХОД — СБОР СЯ ПОД ГОТОВУЮ СТРУКТУРУ САЙТА
- Анализ структуры и разделов сайта.
- Определение списка основных запросов.
- Сбор ТОП-20 ключевых фраз, по которым ранжируются основные конкуренты.
- Сбор максимального количества релевантных ключевых фраз для запросов из п. 2 и 3.
- Очистка от мусорных и нерелевантных фраз.
- Разделение собранных запросов под существующие категории и страницы.
ТРЕТИЙ ПОДХОД — ОБНОВЛЕНИЕ СЕМАНТИЧЕСКОГО ЯДРА ДЛЯ САЙТА.
- Анализ существующей семантики сайта.
- Поиск «слабых мест»: сбор актуальных запросов в тематике, изучение поисковых подсказок, анализ конкурентов для определения недостающих ключей.
- Создание списка упущенных запросов и распределение их по разделам, категориям, страницам.
Проработка вглубь
Вот мы и собрали весь список возможных дополнений к нашим базовым ключам, что же делать дальше? А дальше нужно подготовить список ключевых фраз для еще большей проработки вглубь — поиска запросов со всеми возможными уточнениями.
Необходимо по очереди скомпоновать между собой ключи из разных столбцов, «перемножить» их друг с другом, получив все возможные комбинации. В решении этого вопроса помогут специальные программы, например, генератор фраз PPC-help. Вставляем наши ключи из столбцов таблицы Excel и получаем готовый список ключевых фраз, которые позже мы используем для парсинга в KeyCollector:
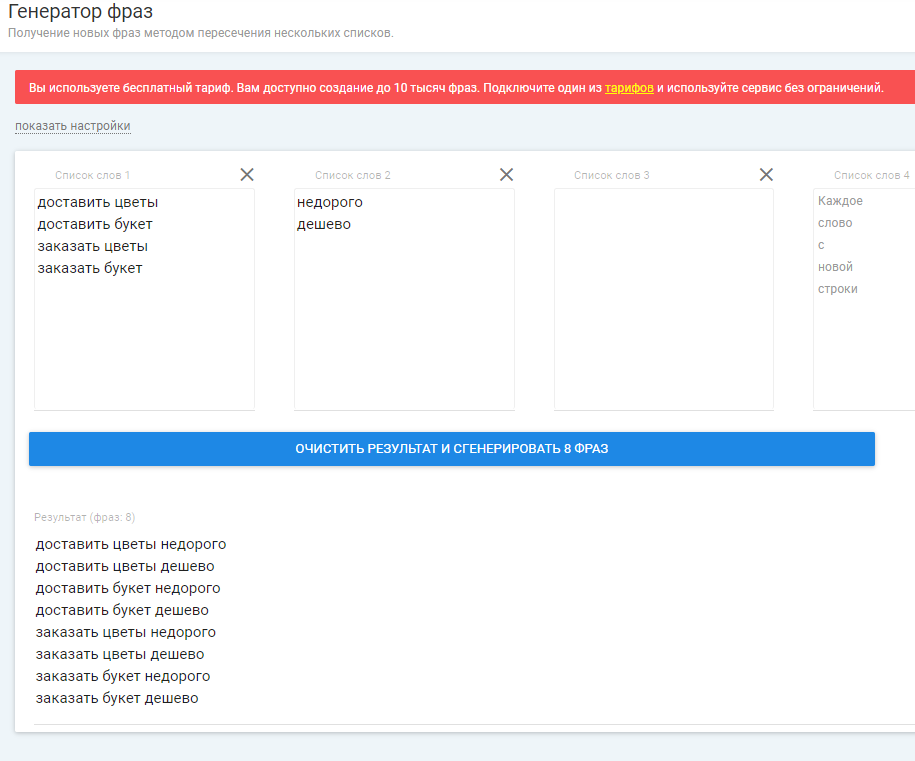 Генерация фраз в программе PPC-help
Генерация фраз в программе PPC-help
Таким образом, мы собрали семантическое ядро для дальнейшего парсинга. Потратьте еще немного времени и проверьте весь список ключевых фраз. Все ли они соответствуют вашей тематике? Все ли они описывают ваши услуги или продукты? Если есть лишние, удалите их, это сэкономит много времени в будущем.
Список готов? Приступайте к парсингу в Key Collector. Это незаменимый инструмент в работе специалиста по контекстной рекламе. Он значительно упрощает процесс создания семантического ядра, собирая запросы на основе загруженных масок ключевых фраз.
Запускайте программу, загружайте ключи, не забудьте выбрать целевой регион и ждите результатов. Помните, что после получения списка из Key Collector необходимо избавиться от дублей типа «доставка цветы москва» и «москва цветы доставка», чтобы в дальнейшем исключить конкуренцию внутри кампании. Также нужно удалить нецелевые запросы, по которым мы не хотим рекламироваться, сохранив при этом список минус-слов в отдельный файл
В финале важно провести кластеризацию, разбив фразы на тематические группы. Все это удобно делать прямо в Key Collector
Как видим, сбор семантического ядра является трудоемким и затратным по времени процессом, но важным этапом создания кампании, поскольку от качества семантики напрямую зависит успешность рекламы, а значит, и финансовая отдача.
Удачных вам рекламных кампаний!
Базы слов
1. Букварикс
Букварис — онлайн-сервис с базой в 2 миллиарда 122 миллиона поисковых фраз для русскоязычного интернета. Просто и удобный интерфейс для поиска ключевых слов.
Возможности сервиса:
- Поиск по одному слову
- Поиск по списку слов
- Поиск по одному домену
- Сравнение двух доменов
- Сравнение нескольких доменов
Инструменты для работы со списками
- Нормализатор слов
- Дедупликатор слов
- Комбинатор слов
- Компаратор слов
- Анализатор слов
Есть также база дополнительной информации с учебными материалами и полезными списками слов.
Сервис предоставляется в открытом доступе без регистрации, но в упрощенной версии. При регистрации открываются почти все возможности, кроме поддержки фильтров (по частотности, количеству слов и символов). Есть разница и в лимитах проверок.
Бизнес аккаунт стоит 695 рублей.
2. Базы Пастухова
Базы Пастухова — наиболее известная база ключевых слов в рунете. Содержит 1.65 миллиарда русских запросов и 618 млн. английских. Базы доступны онлайн.
Также есть базы поисковых подсказок (1,1 млрд. в русской базе и 1,3 млрд. в английской).
Кроме русской и английской базы ключевых слов и подсказок, есть: итальянская, испанская, немецкая, и французская.
Базы предоставляются в онлайн виде и как десктопные программы.
Полный комплект с новыми десктопными базами ключевых слов и новыми онлайн базы с 15 января 2021 года по 28 февраля 2021 года можно приобрести за 9 835 рублей. Реальная экономия — больше $1800. Самое главное — бесплатные пожизненные обновления, это доступно только в рамках этого пакета.
3. MOAB.Tools Семантика
MOAB.Tools — топовый парсер семантики из Яндекс.Метрики, Яндекс.Подсказок, Google.Подсказок. 4+ млн. фраз в час без капчи, прокси и сложных настроек. База загружается на сервер и вы имеете удобный доступ к ней.
Есть тестовый период, доступен после регистрации.
Интегрируется с Key Collector.
Стоимость тарифов стартует от 1 299 рублей и до 6 099 рублей без ограничений по времени (от выработки лимита).
4. Roostat
Roostat — уникальная база с более чем 620 миллионами поисковых запросов Рунета.
Нет информации о стоимости базы. Следует обратится к менеджерам Roostat.
|
Название |
Описание |
Тарифы |
Trial |
|
Букварикс |
Онлайн-сервис с базой поисковых фраз для русскоязычного интернета |
695 рублей |
Есть |
|
Базы Пастухова |
Мультиязычная база ключевых слов (онлайн+десктоп) |
9 835 рублей (по скидке) |
Есть |
|
MOAB.Tools Семантика |
Топовый парсер семантики из Яндекс.Метрики, Яндекс.Подсказок, Google.Подсказок. 4+ млн. фраз в час без капчи, прокси и сложных настроек |
От 1 299 рублей и до 6 099 рублей без ограничений по времени (от выработки лимита) |
Есть |
|
Roostat |
Уникальная база с более чем 620 миллионами поисковых запросов Рунета |
— |
— |
Как группировать запросы
Чтобы понять, как распределять ключевые слова по отдельным страницам, нужно сгруппировать запросы. Для этого надо создать семантические кластеры.
Чаще всего, ключевые слова из кластеров первого и второго уровней определяются еще на этапе мозгового штурма. Для этого просто нужно хорошо разбираться в своем продукте или ориентироваться на структуру сайтов-конкурентов. Семантика остальных подуровней определяется на этапе детального составления семантического ядра и его кластеризации
Еще одно важное условие — каждая группа запросов последнего уровня должна соответствовать одной потребности пользователя. Например, покупка конкретного вида детского белья
Используем Словоёб с уже известной нам функцией быстрого фильтра. С его помощью можно легко отсортировать фразы по категориям для дальнейшего внедрения на посадочных страницах.
1. Введите в поле быстрого фильтра базовое ключевое слово, которое может станет названием для категории/подкатегории/посадочной страницы (например, бренд детского постельного белья «Непоседа») и нажмите Enter.
2. Выделите нужные фразы и скопируйте их.
3. Удалите отмеченные строки правой кнопкой мыши.
4. Создайте в правом меню новую группу (например, с названием «Непоседы»).
5. Для добавления только что выбранных фраз в эту группу, перейдите во вкладку «Данные» — «Добавить фразы».
6. Вернитесь к прежнему списку нажатием клавиши Enter в поле поиска быстрого фильтра.
7. Повторите эту процедуру с другими запросами. Ключевые фразы автоматически выстроятся в алфавитном порядке, благодаря чему можно легко удалить лишние слова или выделить похожие фразы в отдельную группу.
Группировка вручную требует много времени (особенно в том случае, если семантика достаточно широкая). Для автоматизации этого процесса можно использовать платные Key Collector, Rush-Analytics, Just-Magic, или бесплатный скрипт Devaka.ru. Часто приходится объединять некоторые группы запросов. Например, такие:
Согласитесь, создавать две отдельные категории под фразы «красивое белье» и «стильное белье» неразумно 🙂 Для понимания важности фраз для каждой категории/посадочной страницы, скопируйте их в Планировщик ключевых слов Google в раздел «Получение статистики запросов и трендов»:
Так вы проверяете популярность (частотность) поискового запроса. В целом все поисковые запросы делятся на:
- ВЧ-запросы (высокочастотные).
- СЧ-запросы (среднечастотные).
- НЧ-запросы (низкочастотные).
- Микро НЧ-запросы.
При этом нет точных цифр, по которым можно с уверенностью сказать, что запрос принадлежит к определенной группе. Все зависит от тематики сайта. В одних тематиках фраза с частотностью 1000 запросов в месяц может быть низкочастотной (фильмы, музыка), в других — 200 запросов уже может быть признаком высокочастотной фразы (финансовая тематика). Соотношение этих групп: Наиболее высокочастотные запросы впоследствии вписывайте в метатеги. А под низкочастотные оптимизируйте страницы сайта. Как правило, они очень низкоконкурентны, и достаточно провести качественную работу с текстами, чтобы вывести соответствующие страницы в ТОП.
Читайте, как привлечь целевой трафик на сайт с помощью формирования максимально широкого семантического ядра.
После всех этих манипуляций вы получите подробную структуру сайта, состоящую из ключевых фраз для:
Мутаген
Мутаген – платный инструмент, который представляет собой расширенную базу различных ключевых запросов. С его помощью можно легко и просто проверить конкурентность и частотность запросов, используя для этого встроенные инструменты. На сервисе имеется собственный рейтинг конкурентности, благодаря которому вы сможете понять, стоит ли вам пытаться продвигать свои материалы по этим запросам или нет.

Как я уже и сказал, инструмент платный, но стоимость здесь не такая большая. 100 проверок – всего 30 рублей. А парсер Вордстат так и вообще всего 2 копейки. Однако есть и вариант бесплатного использования с ограничением до 10 проверок в сутки.
Обычно Мутаген используют в связке. Сначала парсится семантическое ядро с помощью Вордстата (или Кей Коллектора / СловоЁБа), а потом уже проверяется конкурентность всех подобранный вариантов, чтобы сразу откинуть лишние.
В общем-то, это действительно неплохой онлайн-инструмент, который поможет вам еще лучше очистить свое семантическое ядро. Однозначно рекомендую.
Получение шлейфа
Следующий шаг заключается в формировании шлейфа запросов для отсортированных масок. Под понятием шлейфа подразумевается совокупность средне- и низкочастотных запросов, в которые включены маски.
У каждого запроса есть уточняющий шлейф, который делает семантику более релевантной тематике сайта.
Обратите внимание:
-
Применение «-» позволяет убрать нерелевантные слова.
-
Использование «+» перед предлогами и союзами приводит к их принудительному учету.
-
Если поставить перед словом символ «!», то система будет искать только прямую форму запроса.
-
Использование кавычек «»…»» дает возможность получить статистику по определенному словосочетанию.
-
Применение квадратных скобок [] фиксирует последовательность слов.
-
Если не знаете, какой запрос выбрать, к примеру «машина» или «автомобиль», используйте квадратные скобки в сочетании со знаком «|».
Букварикс
Сервис Букварикс предоставляет набор инструментов для работы с ключевыми словами и доменами, а также для работы со списками.
Возможности Букварикс:
- Поиск по ключевым словам (по одному слову или по списку);
- Поиск по заданному домену;
- Сравнение доменов (двух, нескольких).
- Приведение слов в списке к одному виду;
- Анализ слов в списке по частоте встречаемости (в порядке снижения частоты);
- Сравнение двух списков и формирование одного общего списка оригинальных ключевых слов;
- Комбинирование и формирование словосочетаний из ключевых слов двух списков;
- Поиск и удаление дубликатов слов из списка.
Тарифы:
- Без регистрации – бесплатно (с ограниченными возможностями);
- Бесплатный аккаунт – бесплатно (с ограниченными возможностями);
- Бизнес-аккаунт – 695 рублей за 1 месяц.
Сбор конкурентов
Первым делом нужно осуществить сбор конкурентов и подбор группообразующих ключевых слов – этот процесс делается онлайн и бесплатно. Для начала разберем как можно сделать сбор сайтов-конкурентов на примере ниши болезни глаз.
- Идем в поиск Google/Yandex и вводим общие запросы касательно темы глаз. Например, «болезни глаз», «катаракта» и т. п.
Обращаем внимания на названия домена (выделено красным на скриншоте), как правило, сайт посвященный теме глаз имеет в названии домена на латинице тематическое слово (на примере выше, это «зрение» и «глаза»).

- Копируем название домена в файл, в нашем случае это будут:
- https://www.horosheezrenie.ru/
- www.vseozrenii.ru
- proglaza.ru
- glazkakalmaz.ru
То, что после косой черты «/» нас не интересует. (https://www.vseozrenii.ru/glaznye-bolezni/) берем только название домена до косой черты «/» → https://www.vseozrenii.ru/
- Далее можно посмотреть тематические площадки по уже найденным конкурентам на сайте keys.so. Для этого вставляем в поиск для анализа один из вышеперечисленных доменов.

Скролим вниз и разворачиваем.

Из найденных на keys.so выбираем всех, кто нам подходит, чтобы убедиться в правильности выбора, копируем доменное имя сайта и переходим на него.
- Первый вариант fb.ru – сайт обо всем, он нам не подходит
- Второй Yandex.ru – нам не нужен
- Третий moezrenie.com подходит, заходим на него и проверяем не коммерческий ли он.
- Четвертый mgkl.ru – коммерческий, это сайт глазной клиники.
И так проходим по всем сайтам.
Если не получилось собрать достаточное количество (5-15 шт.) сайтов о глазах, то можно продолжить поиск в keys.so по вновь найденным сайтам.
Что такое семантическое ядро простыми словами
Как это ни странно, но семантическое ядро – это обычный excel файл, в котором списком представлены ключевые запросы, по которым вы (или ваш копирайтер) будете писать статьи для сайта.
Вот как, например, выглядит мое семантическое ядро:
Зеленым цветом у меня помечены те ключевые запросы, по которым я уже написал статьи. Желтым – те, которым статьи собираюсь написать в ближайшее время. А бесцветные ячейки – это значит, что до этих запросов дело дойдет немного позже.
Для каждого ключевого запроса у меня определена частотность, конкурентность, и придуман “цепляющий” заголовок. Вот примерно такой же файл должен получиться и у вас. Сейчас у меня СЯ состоит из 150 ключевиков. Это значит, что я обеспечен “материалом” минимум на 5 месяцев вперед (если даже буду писать по одной статье в день).
Чуть ниже мы поговорим о том, к чему вам готовиться, если вы вдруг решите заказать сбор семантического ядра у специалистов. Здесь скажу кратко – вам дадут такой же список, но только на тысячи “ключей”
Однако, в СЯ важно не количество, а качество. И мы с вами будем ориентироваться именно на это
Зачем вообще нужно семантическое ядро?
А в самом деле, зачем нам эти мучения? Можно же, в конце концов, просто так писать качественные статьи, и привлекать этим аудиторию, правильно? Да, писать можно, а вот привлекать не получится.
Главная ошибка 90% блогеров – это как раз написание просто качественных статей. Я не шучу, у них реально интересные и полезные материалы. Вот только поисковые системы об этом не знают. Они же не экстрасенсы, а всего лишь роботы. Соответственно они и не ставят вашу статью в ТОП.
Здесь есть еще один тонкий момент с заголовком. Например, у вас есть очень качественная статья на тему “Как правильно вести бизнес в “мордокниге”. Там вы очень подробно и профессионально расписываете все про фейсбук. В том числе и то, как там продвигать сообщества. Ваша статья – самая качественная, полезная и интересная в интернете на эту тему. Никто и рядом с вами не валялся. Но вам это все равно не поможет.
Почему качественные статьи вылетают из ТОПа
Представьте, что на ваш сайт зашел не робот, а живой проверяльщик (асессор) с Яндекса. Он понял, что у вас самая классная статья. И рукам поставил вас на первое место в выдаче по запросу “Продвижение сообщества в фейсбук”.
Знаете, что произойдет дальше? Вы оттуда все равно очень скоро вылетите. Потому что по вашей статье, даже на первом месте, никто не будет кликать. Люди вводят запрос “Продвижение сообщества в фейсбук”, а у вас заголовок – “Как правильно вести бизнес в “мордокниге”. Оригинально, свежо, забавно, но… не под запрос. Люди хотят видеть именно то, что они искали, а не ваш креатив.
Соответственно, ваша статья будет вхолостую занимать место в ТОП выдачи. И живой асессор, горячий поклонник вашего творчества, может сколько угодно умолять начальство оставить вас хотя бы в ТОП-10. Но не поможет. Все первые места займут пустые, как шелуха от семечек, статейки, которые друг у друга переписали вчерашние школьники.
Зато у этих статей будет правильный “релевантный” заголовок – “Продвижение сообщества в фейсбук с нуля” (по шагам, за 5 шагов, от А до Я, бесплатно и пр.) Обидно? Еще бы. Ну так боритесь против несправедливости. Давайте составим грамотное семантическое ядро, чтобы ваши статьи занимали заслуженные первые места.
Еще одна причина начать составлять СЯ прямо сейчас
Есть еще одна вещь, о которой почему-то люди мало задумываются. Вам надо писать статьи часто – как минимум каждую неделю, а лучше 2-3 раза в неделю, чтобы набрать побольше трафика и побыстрее.
Все это знают, но почти никто этого не делает. А все потому, что у них “творческий застой”, “никак не могут себя заставить”, “просто лень”. А на самом деле вся проблема именно в отсутствие конкретного семантического ядра.
Наше СЯ – это как контент-план для социальных сетей. То есть там написано конкретно, что мы будем делать в ближайшие 2-3 месяца. Нам не надо будет садиться с утра и начать выдумывать тему для нового поста. У нас все придумано, продумано и прочитано.
Именно это и спасет вас от так называемого “творческого кризиса”. Когда вы точно знаете, что вам делать – становится гораздо легче. Поэтому ни в коем случае не пропускайте этап создания семантического ядра (каким бы муторным вам это дело не показалось). Потом вам все равно придется подбирать темы и запросы, но только потратите вы на это в десять раз больше времени и сил.
А теперь. собственно, давайте разберем, как правильно составить семантическое ядро с нуля.
Кластеризация семантического ядра
Кластеризация (кластерный анализ) — процесс обработки запрос и распределение их на одинаковые лексические группы, называемые кластерами. В кластер попадают запросы, которые могут продвигаться на 1 странице, совместимы между собой и похожи по смыслу.
Виды кластеризации запросов
HARD кластеризация
При данном методе в группу попадают запросы, которые на 100% совместимы между собой, группа формируется, когда URL из ТОП-10 пересекаются во всех запросах, и их количество достигает или превышает определенного порога.
В результате мы получаем большое количество групп небольшого размера за счет высокой точности группировки, метод походит для дальнейшего текстового анализа, т.к. мы будем точно уверены, что в группе нет лишних запросов.
Подходит для большинства коммерческих сайтов и тематик.
SOFT кластеризация
В группу попадают запросы, которые пересекаются URL в ТОП-10 c главным ключом и если их число совпадений достигло нужного нам порога или превысило его.
На выходе получаем меньшее количество групп большого размера за счет слабой точности пересечения запросов, идеально подходит для информационных порталов или форумов, для контекстной рекламы. В группу могут попадать слабо совместимые ключи, в следствии чего использовать такие группы для текстового анализа не рекомендуется.
Программы для кластеризации
Кроме онлайн инструментов есть еще и десктопные версии программ по кластеризации ядра (все программы работают только в Windows):
- Key Collector — 1800 рублей.
- KeyAssort — 1990 рублей. (невозможно работать на Retina дисплеях)
- Majento — , для работы необходимы XML лимиты.
Пример кластеризации семантического ядра в программе Magento:
Сервисы для кластеризации
Для автоматической кластеризации семантического ядра используют платные онлайн сервисы:
- Rush Analytics — является лучшим сервисом для кластеризации ядер, собирает данные с реальной выдачи, без использования XML. Сервис платный, но при регистрации выдается 200 лимитов, которых хватит на группировку 400 запросов в семантике.
- Just-Magic.org — также платный сервис, используется в кластеризации очень сложных тематик, когда необходимо видеть силу связи между ключевыми запросами в кластерах. При регистрации вы получаете лимит на 100 запросов.
- http://coolakov.ru/tools/razbivka/ — бесплатный сервис кластеризации ядра до 1000 запросов.
Пример кластеризации семантики от Coolakov:
Как работать в программе
Теперь мы кратко разберемся, как пользоваться этой программой. Сложностей тут никаких нет. Но все равно стоит дать небольшую инструкцию, которая будет включать в себя последовательность действий и обзор некоторых функций.
Для начала вы должны создать проект. Идем в главное меню (кнопочка Еб в углу), нажимаем на “Создать проект”. Выскочит окно нашего файлового менеджера, где нам будет предложено заполнить поле “Имя” и сохранить наш файл проекта в каком-то месте.
Это все делается на ваше усмотрение. Но лучше сохранять проекты в той же папке, где и сам Словоеб. После того, как вы кликнете “Сохранить”, проект откроется в окне программы.
В нижней части программы мы видим настройки регионов для Яндекса и Гугла. Самая первая отвечает за Яндекс.Вордстат, вторая – за Директ, третья – Гугл. Также тут есть кнопка обновления, которая поможет вам в случае, если программа начнет тупить.
Чуть выше вы можете видеть вкладки: “Новости” – которых уже не было 2 года, “Журнал событий” – лог всех операций, производимых через утилиту, и “Статистика” – тут будет отображаться статистика по собранным ключевикам.
Еще выше у нас расположилось большое поле, где будут все запросы и их частотности. Вся информация представлена в виде удобной таблицы.
Рядом “Управление группами”. С помощью этого инструмента вы сможете разбивать запросы на группы и работать уже с ними.
В самом верху у нас находятся инструменты для работы с семантическим ядром. Самая первая из доступных нам кнопок позволяет работать с минус-словами. Туда можно вписать слова и фразы, которые программа должна игнорировать при сборе ядра.
Рядом идут инструменты для работы с Вордстатом и поисковыми подсказками. Вы можете собрать ключи из левой колонки Вордстата (с наличием самого ключа в запросах), правой колонки (похожие запросы). После этого можно собрать поисковые подсказки или проверить корректность словоформ. Здесь же инструменты для вычисления KEI и сбора частотностей.
Для добавления своих поисковых фраз вы должны перейти во вкладку “Данные”, нажать на кнопку “Добавить фразы”. У вас выскочит окно, куда вы сможете ввести одну или несколько поисковых фраз.
Поисковые фразы можно добавлять в текущую группу, либо же создать новую. Также вы можете воспользоваться функцией “Загрузить из файла”. Программа работает только с TXT-файлами, поэтому если вы сохраняли поисковые фразы где-то еще – самое время перенести их в блокнот. После этого вы сможете собрать частотности или провести любые другие операции с этими данными.
Как только работа по сбору семантического ядра и очистке его от лишнего мусора будет закончена, вы должны экспортировать всю информацию в файл. Для этого найдите в левом верхнем углу иконку с Excel-файлом и кликните на нее. Далее вновь откроется окно файлового менеджера, используя которое вы и сохраните файлик с таблицей.
Вы можете сохранить проект и вернуться к работе над ним позже. Для этого нажмите на иконку сохранения, также выберите папку через файловый менеджер и кликните на “Сохранить”.