Иерархическая модель данных
Содержание:
- Обобщенное описание структуры
- Другие модели баз данных (ООСУБД)
- Ограничения типа данных hierarchyidLimitations of hierarchyid
- Основные свойства типа hierarchyidKey Properties of hierarchyid
- 6) Хранилища данных и модели их представления
- Язык описания данных иерархической модели
- 7 многомерная модель
- Ключи в БД
- §3.3. Иерархическая модель данных§3.4. Сетевая модель данных
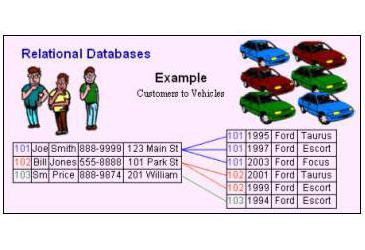
- Структура реляционной модели данных
- Сетевая модель данных
Обобщенное описание структуры
Термин «древовидная» для описания структуры упоминается в этой статье уже далеко не единожды. Пора рассказать, откуда он произошел. Все потому что иерархическая база данных — это такая БД, которая использует тип данных «дерево». Рассмотрим подробнее, что он из себя представляет.
Это составной тип: в каждый из элементов (узлов) вкладывается несколько последующих (один или более). А начинается все с одного корневого элемента. Суть в том, что каждый из кусочков типа «дерево», является подтипом, тоже «деревом». Много-много разветвленных, и все также упорядоченных структур.
Элементарные типы могут быть простыми и составными, но по существу это всегда записи. Но в простом записи присутствует один тип данных, а в составном — целая их совокупность.
Иерархической модели свойственен принцип потомков, когда каждый предыдущий сегмент является предком для последующего. Кроме того, потомок по отношению к вышестоящему типу является типом подчиненным, в то время как равнозначные один другому записи считаются близнецами.
Другие модели баз данных (ООСУБД)
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Данная публикация является переводом статьи «Types of Database Models | Database Management System» , подготовленная редакцией проекта.
Ограничения типа данных hierarchyidLimitations of hierarchyid
Тип данных hierarchyid имеет следующие ограничения.The hierarchyid data type has the following limitations:
-
Столбец типа hierarchyid не принимает древовидную структуру автоматически.A column of type hierarchyid does not automatically represent a tree. Приложение должно создать и назначить значения hierarchyid таким образом, чтобы они отражали требуемые связи между строками.It is up to the application to generate and assign hierarchyid values in such a way that the desired relationship between rows is reflected in the values. Некоторые приложения могут содержать столбец типа hierarchyid , указывающий местоположение в иерархии, определенной в другой таблице.Some applications might have a column of type hierarchyid that indicates the location in a hierarchy defined in another table.
-
Параллельными процессами создания и присвоения значений hierarchyid управляет само приложение.It is up to the application to manage concurrency in generating and assigning hierarchyid values. Нет никакой гарантии, что значения hierarchyid уникальны, если приложение не использует ограничение уникального ключа или не обеспечивает уникальность своей логикой.There is no guarantee that hierarchyid values in a column are unique unless the application uses a unique key constraint or enforces uniqueness itself through its own logic.
-
Иерархические связи, представленные значениями типа hierarchyid , не обеспечиваются и не проверяются, как связи по внешнему ключу.Hierarchical relationships represented by hierarchyid values are not enforced like a foreign key relationship. Можно, а иногда и удобно иметь иерархическую связь, в которой у A есть потомок B и когда A удаляется, у B остается связь с несуществующей записью.It is possible and sometimes appropriate to have a hierarchical relationship where A has a child B, and then A is deleted leaving B with a relationship to a nonexistent record. Если это неприемлемо, приложение должно запросить потомков, прежде чем удалять родителей.If this behavior is unacceptable, the application must query for descendants before deleting parents.
Основные свойства типа hierarchyidKey Properties of hierarchyid
Значение типа данных hierarchyid представляет позицию в древовидной иерархии.A value of the hierarchyid data type represents a position in a tree hierarchy. Значения hierarchyid обладают следующими свойствами.Values for hierarchyid have the following properties:
-
Исключительная компактностьExtremely compact
Среднее число бит, необходимое для представления узла в древовидной структуре с n узлами, зависит от среднего количества потомков у узла.The average number of bits that are required to represent a node in a tree with n nodes depends on the average fanout (the average number of children of a node). Для структур с низкой степенью ветвления (0-7) объем занимаемой памяти равен примерно 6*logA n бит, где A — среднее ветвление.For small fanouts, (0-7) the size is about 6*logA n bits, where A is the average fanout. Для представления узла в иерархии организации, насчитывающей 100 000 человек со средним уровнем ветвления 6, необходимо около 38 бит.A node in an organizational hierarchy of 100,000 people with an average fanout of 6 levels takes about 38 bits. Эта величина округляется до 40 бит (5 байт), которые необходимы для хранения.This is rounded up to 40 bits, or 5 bytes, for storage.
-
Сравнение проводится в порядке приоритета глубиныComparison is in depth-first order
Если заданы два значения hierarchyid — a и b, a<b означает, что значение a появляется раньше значения b, если проходить по дереву с приоритетным направлением в глубину.Given two hierarchyid values a and b, a<b means a comes before b in a depth-first traversal of the tree. Индексы для типов данных hierarchyid располагаются в порядке приоритета глубины, а узлы, встречающиеся рядом при проходе по дереву с приоритетным направлением глубины, хранятся рядом друг с другом.Indexes on hierarchyid data types are in depth-first order, and nodes close to each other in a depth-first traversal are stored near each other. Например, потомки некоторой записи хранятся рядом с этой записью.For example, the children of a record are stored adjacent to that record.
-
Поддержка произвольных вставок и удаленийSupport for arbitrary insertions and deletions
С помощью метода GetDescendant можно в любой момент создать одноуровневый элемент, расположенный справа от заданного узла, слева от заданного узла или между любыми двумя другими одноуровневыми элементами.By using the GetDescendant method, it is always possible to generate a sibling to the right of any given node, to the left of any given node, or between any two siblings. Свойство сравнения сохраняется, если произвольное число узлов вставляется в иерархию или удаляется из нее.The comparison property is maintained when an arbitrary number of nodes is inserted or deleted from the hierarchy. Большинство операций вставки и удаления сохраняют свойство компактности.Most insertions and deletions preserve the compactness property. Однако операции вставки между двумя узлами приводят к созданию значений hierarchyid, обладающих менее компактным представлением.However, insertions between two nodes will produce hierarchyid values with a slightly less compact representation.
6) Хранилища данных и модели их представления
: предметно-ориентированный, интегрированный,
неизменяемый и поддерживающий хронологию набор данных,
предназначенный для обеспечения принятия управленческих решений.
Основные модели представления данных в хранилищах данных:
- 1. Реляционная
- 2. Многомерная
- 3. Гибридная
- 4. Виртуальная
Реляционная модель хранилищ данных
В основе реляционных хранилищ данных лежит разделение данных на две группы – измерения и факты.
Измерения – это категориальные атрибуты, наименования и свойства объектов, участвующих в некотором бизнес-процессе.
Примеры измерений: наименования товаров, названия фирм-поставщиков и покупателей, ФИО людей, названия городов и т. д.Измерения качественно описывают исследуемый бизнес-процесс.Факты – это непрерывные по своему характеру данные (могут принимать бесконечное множество значений).
Примеры фактов: цена товара или изделия, их количество, сумма продаж или закупок, зарплата сотрудников, сумма кредита и т. д.
Факты количественно описывают бизнес-процесс.
рис Схема построения реляционного хранилища данных «звезда»
Центральной является таблица фактов (Fact table), с которой связаны таблицы измерений (Dimension tables).
Преимущества схемы «звезда»:
- простота и логическая прозрачность модели
- более простая процедура пополнения измерений, поскольку
- приходится работать только с одной таблицей
Недостатки схемы «звезда»:
- медленная обработка измерений, поскольку одни и те же значения
- измерений могут встречаться несколько раз в одной и той же таблице высокая вероятность возникновения несоответствий в данных (в частности, противоречий), например, из-за ошибок ввода
Рис Схема построения реляционного хранилища данных «снежинка» (модификация схемы «звезда»)
Основное функциональное отличие схемы «снежинка» от схемы «звезда» – это возможность работы с иерархическими уровнями, определяющими
степень детализации данных.Преимущества схемы «снежинка»:
- она ближе к представлению данных в многомерной модели
- процедура загрузки из РХД в многомерные структуры более
- эффективна и проста, поскольку загрузка производится из отдельных таблиц
- намного ниже вероятность появления ошибок, несоответствия данных
- большая, по сравнению со схемой «звезда», компактность
- представления данных, поскольку все значения измерений упоминаются только один раз
Недостатки схемы «снежинка»:
- достаточно сложная для реализации и понимания структура данных
- усложненная процедура добавления значений измерений
Преимущества реляционных хранилищ данных:
- Практически неограниченный объем хранимых данных
- Поскольку реляционные СУБД лежат в основе построения многих систем оперативной обработки (OLTP), которые обычно являются главными источниками данных для ХД, использование реляционной модели позволяет упростить процедуру загрузки и интеграции данных в хранилище
- При добавлении новых измерений данных нет необходимости выполнять сложную физическую реорганизацию хранилища, в отличие, например, от многомерных ХД
- Обеспечиваются высокий уровень защиты данных и широкие возможности разграничения прав доступа
Главный недостаток реляционных хранилищ данных:
При использовании высокого уровня обобщения данных и иерархичности измерений в таких хранилищах начинают «размножаться» таблицы агрегатов. В результате скорость выполнения запросов реляционным хранилищем замедляется
Язык описания данных иерархической модели
В рамках
иерархической модели выделяют языковые средства описания данных (DDL, Data Definition
Language) и средства манипулирования данными (DML, Data Manipulation Language).
Каждая физическая
база описывается набором операторов, определяющих как ее логическую структуру,
так и структуру хранения БД. Описание начинается с оператора определения базы — DBD (Data Base
Definition):
DBD Name = <
имя БД>, ACCESS = < способ доступа>
Способ доступа
определяет способ организации взаимосвязи физических записей.
Определено 5 способов доступа:
HSAM
—
hierarchical sequential access method (иерархически
последовательный метод),
HISAM
—
hierarchical index sequential access method
(иерархически индексно-последовательный метод),
EDAM
—
hierarchical direct access method (иерархически прямой метод),
HID AM
—
hierarchical index direct access method (иерархически индексно-прямой метод),
INDEX
—
индексный метод.
Далее идет
описание наборов данных, предназначенных для хранения БД:
DATA SET D01 = < имя оператора, определяющего хранимый набор данных>. DEVICE =< устройство хранения БД>,
Так как физические записи имеют разную длину, то при модификации данных запись может увеличиться
и превысит исходную длину записи до модификации. В этом случае при определенных
методах хранения может понадобиться дополнительное пространство хранения, где
и будут размещены дополнительные данные. Это пространство и называется областью
переполнения.
После описания
всей физической БД идет описание типов сегментов, ее составляющих, в соответстшш
с иерархией. Описание сегментов всегда начинается с описания корневого сегмента.
Общая схема описания типа сегмента такова:
SEGM NAME =
< имя сегмента>. BYTES =< размер в байтах>.
FREQ = <средняя
частота реализаций сегмента под одним исходным>
PARENT = <имя
родительского сегмента>
Параметр
FREQ определяет среднее количество экземпляров данного сегмента, связанных с
одним экземпляром родительского сегмента. Для корневого сегмента это число возможных
экземпляров корневого сегмента.
Для корневого
сегмента параметр PARENT равен 0 (нулю). Далее для каждого сегмента дается описание
полей:
FIELD NAME =
{(<имя поля> .{U M}) | <имя поля> }.
START = <
номер байта, с которого начинается значения поля >,
BYTES = <размер
поля в байтах>,
TYPE = {X |
Р | С}
Признак SEQ
— задается для ключевого поля, если экземпляры данного сегмента физически упорядочены
в соответствии со значениями данного поля.
Параметр
U задается, если значения ключевого поля уникальны для всех экземпляров данного
сегмента, М — в противном случае. Если поле является ключевым, то его описание
задается в круглых скобках, в противном случае имя поля задается без скобок.
Параметр TYPE определяет тип данных. Для ранних иерархических моделей были определены
только три типа данных: X — шестпадцатеричиый, Р —упакованный десятичный, С
— символьный.
Заканчивается
описание схемы вызовом процедуры генерации:
- DBDGEN — указывает
на конец последовательности управляющих операторов описания БД; - FINISH — устанавливает
ненулевой код завершения при обнаружении ошибки; - END — конец.
В системе
может быть несколько физических БД (ФБД), но каждая из них описывается отдельно
своим DBD и ей присваивается уникальное имя. Каждая ФБД содержит только один
корневой сегмент. Совокупность ФБД образует концептуальную модель данных.
7 многомерная модель
В основе многомерного представления данных лежит их разделение на две группы – измерения и факты
Многомерная модель данных реализуется с помощью многомерных кубов
Измерения – это категориальные атрибуты, наименования и свойства объектов, участвующих в некотором бизнес-процессе (наименования
товаров, названия фирм-поставщиков и покупателей, ФИО людей, названия городов и т. д.)
Факты – это данные, количественно описывающие бизнес-процесс, непрерывные по своему характеру, то есть они могут принимать
бесконечное множество значений (цена товара или изделия, их количество, сумма продаж или закупок, зарплата сотрудников, сумма
кредита, страховое вознаграждение и т. д.)
Многомерный куб можно рассматривать как систему координат, осями которой являются измерения (например, Дата, Товар, Покупатель). По осям
будут откладываться значения измерений
В ячейке 1 будут располагаться факты, относящиеся к продаже цемента ООО «Спецстрой» 3 ноября, в ячейке 2 – к продаже плит ЗАО « » 6
ноября, а в ячейке 3 – к продаже плит ООО «Спецстрой» 4 ноября.
Рис Многомерный взгляд на измерения Дата, Товар и Покупатель
Выделенный сегмент будет содержать информацию о том, сколько плит, на какую сумму и по какой цене приобрела фирма ЗАО «Строитель» 3 ноября.
Из многомерного куба может быть составлен обычный плоский отчет. По столбикам и строчкам отчета будут бизнес-категории (грани куба), а в ячейках
показатели.
Преимущества многомерного подхода:
- Представление данных в виде многомерных кубов более наглядно, чем совокупность нормализованных таблиц реляционной модели, структуру которой представляет только администратор БД
- Возможности построения аналитических использующей МХД, более широки запросов
- В некоторых случаях использование многомерной значительно уменьшить продолжительность поиска в выполнение аналитических запросов практически в времени к системе, модели позволяет МХД, обеспечивая режиме реального
Недостатки использования многомерной модели:
- Для ее реализации требуется больший объем памяти
- Многомерная структура труднее поддается модификации
Системы, поддерживающие многомерную модель данных:
Essbase, Media Multi-matrix, Oracle Express Server, Cache.
Многие программные продукты позволяют одновременно работать с
многомерными и с реляционными БД.
Ключи в БД
Первичный ключ (РК, primary key) — столбец, значения которого различны во всех строках. РК бывают логические (естественные) и суррогатные (искусственные).
Суррогатный ключ — это дополнительное поле в БД. Обычно это уникальный id (порядковый номер записи), хотя принцип может быть и другой, главное — уникальность.
Вносим первичные ключи в наши таблицы:
Заметьте, что каждая запись в таблице уникальна. Осталось лишь установить соответствие между сообщениями и темами, используя первичные ключи. Добавляем в таблицу с сообщениями ещё одно поле:
Теперь становится ясно, что сообщение id=2 относится к теме «О рыбалке» (id=4), которая создана Васей, а остальные принадлежат теме «О рыбалке», созданной Кириллом (id=1). Такое поле будет называться внешний ключ (FK, foreign key). При этом каждое значение данного поля сопоставляется с каким-либо первичным ключом из таблицы «Темы». В результате устанавливается однозначное соответствие между темами и сообщениями.
Ещё момент: допустим, добавляется новый пользователь по имени Вася.
Как узнать, какой же из «Васей» оставил сообщение? Для этого поля «Автор» в наших таблицах «Сообщения» и «Темы» мы тоже сделаем внешними ключами:
Итак, наша база данных фактически готова. Схематично она выглядит так:
В этой небольшой базе данных лишь 3 таблицы. А что делать, если их 10 либо 200? Ясно, что всё не так просто. Именно поэтому любое проектирование реляционных баз данных начинается с разработки концептуальной модели данных.
§3.3. Иерархическая модель данных§3.4. Сетевая модель данных
Иерархическая базы данных «Доменная система имен»
Еще одним примером иерархической базы данных является доменная система имен подключенных к Интернету компьютеров. На верхнем уровне находится табличная база данных, содержащая перечень доменов верхнего уровня (всего 269 домена), из которых 12 — административные, а остальные 257 — географические. Наиболее многочисленным доменом (данные на январь 2008 года) является административный домен net (около 190 миллионов серверов), а некоторых доменах (например, в географическом домене zr) до сих пор не зарегистрировано ни одного сервера.
На втором уровне находятся табличные базы данных, содержащие перечень доменов второго уровня для каждого домена первого уровня.
На третьем уровне могут находиться табличные базы данных, содержащие перечень доменов третьего уровня для каждого домена второго уровня и таблицы, содержащие IP-адреса компьютеров, находящихся в домене второго уровня.
Рис. 3.3. Иерархическая база данных Доменная система имен
База данных «Доменная система имен» должна содержать записи обо всех компьютерах, подключенных к Интернету, т. е. более 500 миллионов записей. Размещение такой огромной базы данных на одном компьютере сделало бы поиск информации очень медленным и неэффективным. Решение этой проблемы было найдено путем размещения отдельных составных частей базы данных на различных DNS- серверах. Таким образом, иерархическая база данных «Доменная система имен» является распределенной базой данных.
Поиск информации в такой иерархической распределенной базе данных ведется следующим образом. Например, мы хотим ознакомиться с содержанием WWW-сервера фирмы Microsoft.
Сначала наш запрос, содержащий доменное имя сервера www.microsoft.com, будет оправлен на DNS-сервер нашего провайдера, который переадресует его на DNS-сервер самого верхнего уровня базы данных. В таблице первого уровня будет найден интересующий нас домен сот и запрос будет адресован на DNS-сервер второго уровня, который содержит перечень доменов второго уровня, зарегистрированных в домене сот.
В таблице второго уровня будет найден домен microsoft и запрос будет переадресован на DNS-сервер третьего уровня. В таблице третьего уровня будет найдена запись, соответствующая доменному имени, содержавшемуся в запросе. Поиск информации в базе данных «Доменная система имен» будет завершен и начнется поиск компьютера в сети по его IР-адресу.
Следующая страница §3.3. Иерархические базы данных. Контрольные вопросы
Cкачать материалы урока
Структура реляционной модели данных
При табличной организации данных отсутствует иерархия элементов. Строки и столбцы могут быть просмотрены в любом порядке, поэтому высока гибкость выбора любого подмножества элементов в строках и столбцах. Любая таблица в реляционной базе состоит из строк, которые называют записями, и столбцов, которые называют полями. На пересечении строк и столбцов находятся конкретные значения данных. Для каждого поля определяется множество его значений.
В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствованна соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Записи в таблице хранятся упорядоченными по ключу. Ключ может быть простым, состоящим из одного поля, и сложным, состоящим из нескольких полей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами. Индекс – это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице. Индекс обеспечивает логическую последовательность записей в таблице, а также прямой доступ к записи.
По первичному ключу всегда отыскивается только одна строка, а по вторичному – может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Индексы можно создавать и удалять, оставляя неизменным содержание записей реляционной таблицы. Количество индексов, имена индексов, соответствие индексов полям таблицы определяется при создании схемы таблицы.
Индексы позволяют эффективно реализовать поиск и обработку данных, формирую дополнительные индексные файлы. При корректировке данных автоматически упорядочиваются индексы, изменяется местоположение каждого индекса согласно принятому условию (возрастанию или убыванию значений). Сами же записи реляционной таблицы не перемещаются при удалении или включении новых экземпляров записей, изменении значений их ключевых полей.
С помощью индексов и ключей устанавливаются связи между таблицами. Связь устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Группа связанных таблиц называется схемой данных. Информация о таблицах, их полях, ключах и т.п. называется метаданными.
Сетевая модель данных
Стандарт
сетевой модели впервые был определен в 1975 году организацией CODASYL (Conference
of Data System Languages), которая определила базовые понятия модели и формальный
язык описания.
Базовыми
объектами модели являются:
- элемент данных;
- агрегат данных;
- запись;
- набор данных,
Элемент данных
—
то же, что и в иерархической модели, то есть минимальная информационная
единица, доступная пользователю с использованием СУБД.
Агрегат данных
—
соответствует следующему уровню обобщения в модели. В модели определены
агрегаты двух типов: агрегат типа вектор и агрегат типа повторяющаяся группа.
Агрегат данных
имеет имя, и в системе допустимо обращение к агрегату по имени. Агрегат типа
вектор соответствует линейному набору элементов данных. Например, агрегат Адрес
может быть представлен следующим образом:
|
Адрес |
|||
|
Город |
Улица |
дом |
квартира |
Агрегат типа
повторяющаяся группа соответствует совокупности векторов данных. Например, агрегат
Зарплата соответствует типу повторяющаяся группа с числом повторений 12.
|
Зарплата |
|
|
Месяц |
Сумма |
Записью называется
совокупность агрегатов или элементов данных, моделирующая некоторый класс объектов
реального мира. Понятие записи соответствует понятию «сегмент» в
иерархической модели. Для записи, так же как и для сегмента, вводятся понятия
типа записи и экземпляра записи.
Следующим
базовым понятием в сетевой модели является понятие «Набор».
Набор
—
это двухуровневый граф, связывающий отношением «один-ко-многим» два типа записи.
Набор фактически
отражает иерархическую связь между двумя типами записей. Родительский тип записи
в данном наборе называется владельцем набора, а дочерний тип записи — членом
того же набора.
Для любых
двух типов записей может быть задано любое количество наборов, которые их связывают.
Фактически наличие подобных возможностей позволяет промоделировать отношение
«многие-ко-многим» между двумя объектами реального мира, что выгодно
отличает сетевую модель от иерархической. В рамках набора возможен последовательный
просмотр экземпляров членов набора, связанных с одним экземпляром владельца
набора.
Между двумя
типами записей может быть определено любое количество наборов: например, можно
построить два взаимосвязанных набора. Существенным ограничением набора является
то, что один и тот же тип записи не может быть одновременно владельцем и членом
набора.
В качестве
примера рассмотрим таблицу, на основе которой организуем два набора и определим
связь между ними:
|
Преподаватель |
Группа |
День недели |
№ пары |
Аудитория |
Дисциплина |
||
|
Иванов |
4306 |
Понедельник |
1 |
22-13 |
КИД |
||
|
Иванов |
4307 |
Понедельник |
2 |
22-13 |
КИД |
||
|
Карпова |
4307 |
Вторник |
2 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
4309 |
Вторник |
4 |
22-14 |
БЗ и ЭС |
||
|
Карпова |
84305 |
Вторник |
1 |
22-14 |
БД |
||
|
Смирнов |
4306 |
Вторник |
3 |
23-07 |
ГВП |
||
|
Смирнов |
4309 |
Вторник |
4 |
23-07 |
ГВП |
||
Экземпляров
набора Ведет занятия будет 3 (по числу преподавателей), экземпляром набора Занимается
у будет 4 (по числу групп). На рис. 3.6 представлены взаимосвязи экземпляров
данных наборов.
Рис.
3.6. Пример взаимосвязи экземпляров двух наборов
Среди всех
наборов выделяют специальный тип набора, называемый «Сингулярным набором»,
владельцем которого формально определена вся система. Сингулярный набор изображается
в виде входящей стрелки, которая имеет собственно имя набора и имя члена набора,
но у которой не определен тип записи «Владелец набора». Например,
сингулярный набор М.
Сингулярные
наборы позволяют обеспечить доступ к экземплярам отдельных типов данных, поэтому
если в задаче алгоритм обработки информации предполагает обеспечение произвольного
доступа к некоторому типу записи, то для поддержки этой возможности необходимо
ввести соответствующий сингулярный набор.
В общем случае
сетевая база данных представляет совокупность взаимосвязанных наборов, которые
образуют на концептуальном уровне некоторый граф.